Machine Learning by professor Andrew Ng in Coursera
Anomaly Detection
1) Developing and evaluating an anomaly detection system
'이전 강의에서 배웠던 내용, the importance of real-number evaluation.
숫자로 결과를 명확하게 내려주는게 좋다고 했던..'
learning algorithm을 개발(feature 선택 등 ..)할 때 알고리즘을 평가해주는 방법 ('예를들어 정상인 데이터의 y=0, 비정상인 데이터의 y=1로 값을 주는 것처럼')이 있으면 결정을 내리기 훨씬 수월하다.
Aircraft engines motivation example
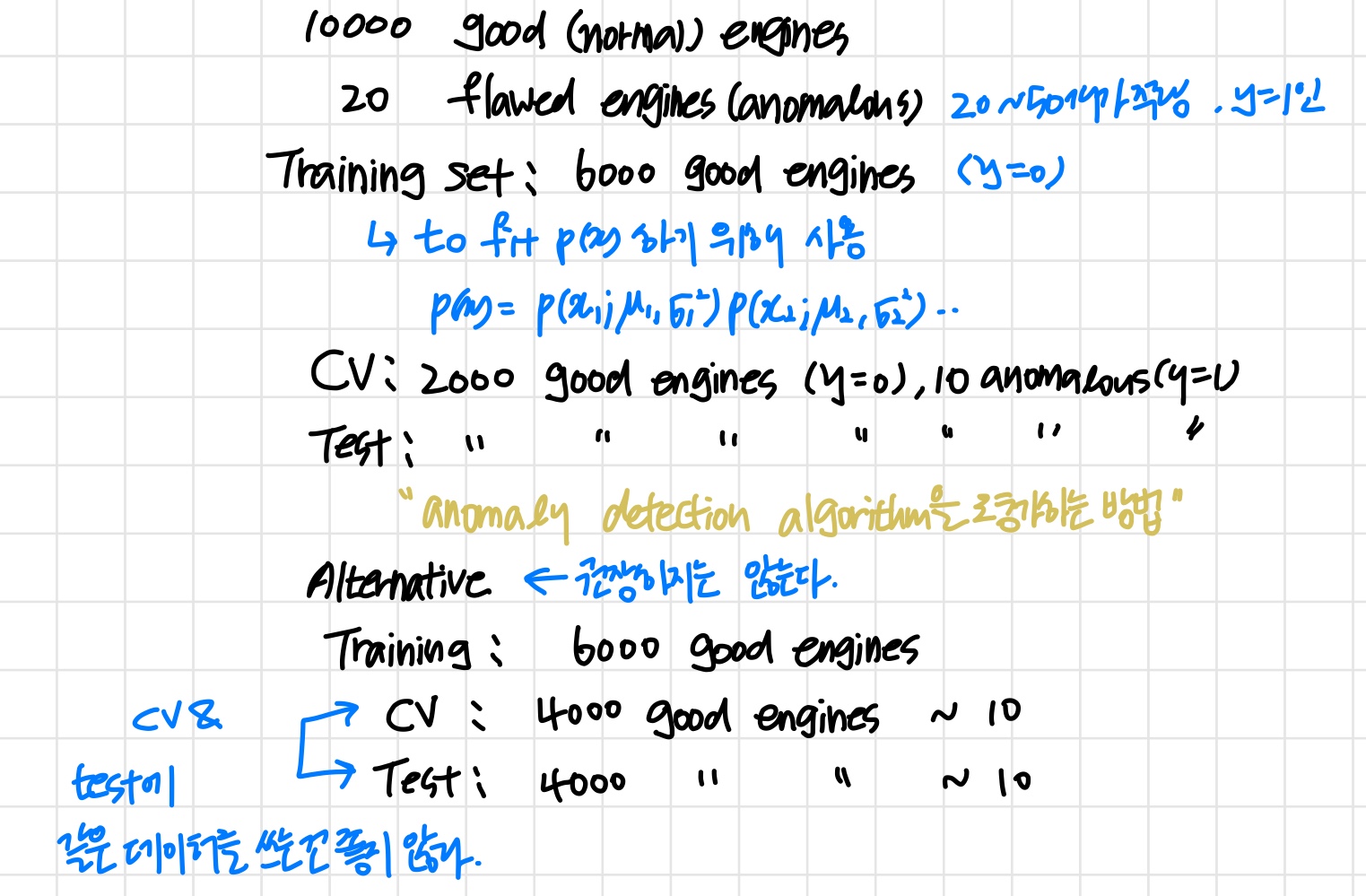
Algorithm evaluation

따라서 이후에 배우는 와 같은 단일 숫자로 표현되는 것을 평가 기준으로 삼는다.

2) Anomaly detection vs. Supervised learning
- Anomaly detection
- 양성 샘플()이 매우 적다
- 음성 샘플()이 매우 많다.
- 한 데이터들의 유형이 다양하다.
Hard for any algorithm to learn from positive examples what the anomalies look like;
이후에 들어올 새로운 데이터는 이전과는 전혀 다른 형태일 수 있다. - 예시
- Fraud detection
- Manufacturing
많은 제품들 중 비정상 제품 탐지 - Monitoring machines in a data center
비정상적으로 작동하는 기계 탐지
만약 비정상 데이터들이 많아진다면 -> Supervised learning 으로 바꿔준다
- Supervised learning
- 양성 & 음성 샘플이 모두 골고루 많을 때
- 충분히 많은 양성 샘플을 통해 학습 알고리즘이 양성 샘플에 대해 파악할 수 있다. 따라서 이후에 새로 들어올 양성 샘플들은 학습 알고리즘이 알고 있는 것과 유사한 형태를 가진다.
'양성샘플의 형태를 예측할 수 있다.' - 예시
- Email spam classification
- Weather prediction (sunny / rainy / etc.)
- Cancer classificatio
골고루 많을 때
3) Choosing what features to use
feature가 반드시 Gaussian을 따라야 하는 것은 아니다.
하지만 Gaussian을 따르면 더 좋기 때문에 를 이용해 해준다.
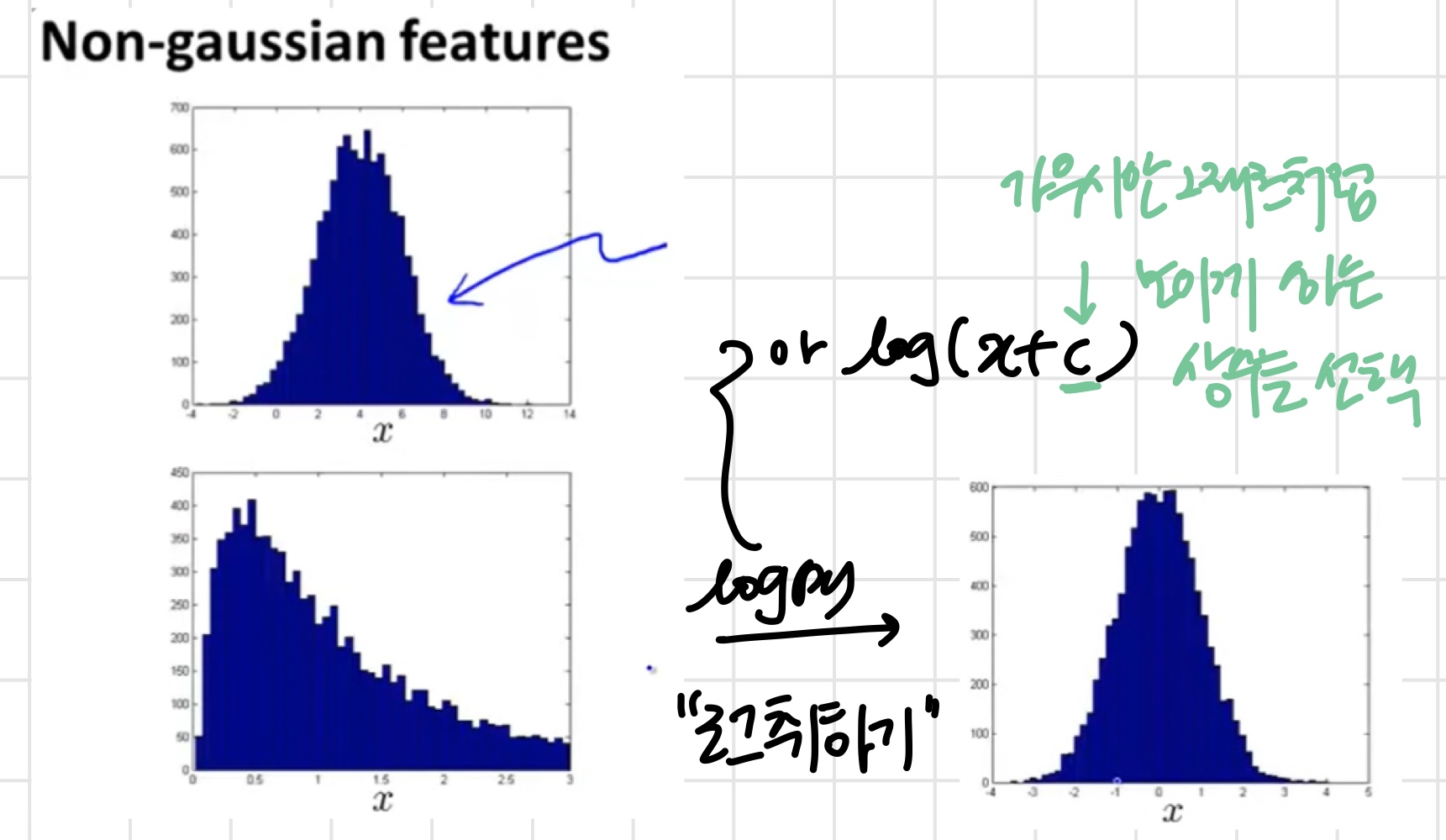
Error Analysis for Anomaly Detection
정상 샘플의 는 높고 비정상 샘플의 는 낮은 것이 이상적이다.
하지만 실제로는 정상, 비정상 샘플의 는 서로 비슷하다.
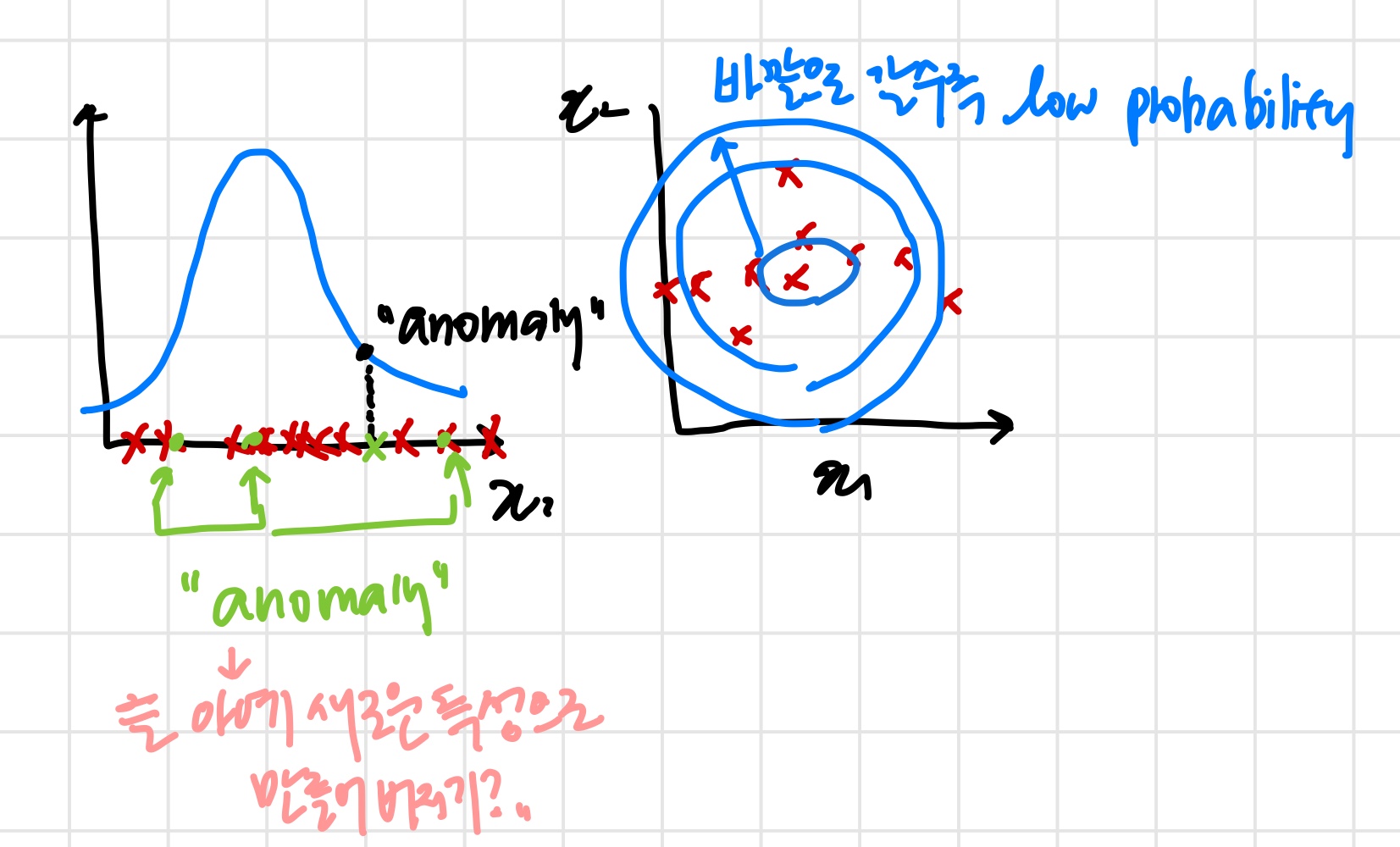
따라서 이면서 가 큰 경우들을 따로 뽑아 아예 새로운 특성으로 만들어버린다.
Monitoring computers in a data center
값이 아주 크거나 작은, 즉 일 것 같은 특성들을 고른다.
주어진 특성이 위와 같다.
이때 과 는 서로 선형적으로 증가한다.
예를 들어 웹서버 중 하나가 무한루프에 갇혀 버렸다고 해보자.
이때 cpu양은 증가하는 반면 traffic은 증가하지 못한다.
이러한 를 감지하기 위해
인 특성을 새로 추가할 수 있다.
또는 조금 더 신박하게 의 제곱값을 으로 나눠준다.
