[2025.05.17] Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment
제안 배경
Trajectory-level 학습의 한계
- 에이전트 학습 시, 멀티턴 trajectory임에도 전체 에이전트 시퀀스에 동일한 피드백 시그널을 제공하는 trajectory-level의 reward assignment를 많이 사용
- 이 경우 개별 단계의 중요성이 천차만별인 장기 추론 작업의 효과적 학습이 어려움
Credit에 대한 할당
- 멀티턴 시나리오에서는 성공/실패에 기여한 특정 작업을 결정하는 것이 중요함
- 적절한 크레딧 할당 없이 모든 턴에 대한 가중을 동일시하는 경우 중간 단계의 중요성에 대해 학습하지 못하는 경우가 생김
Tool에 대한 사용
- 외부 도구를 "언제" 사용해야 하는지 뿐만 아니라, 검색된 정보를 추론 프로세스에 "어떻게" 효과적으로 통합하는지도 학습해야함
- 부적절한 크레딧 할당은 에이전트가 도구를 불필요하게 과도하게 사용하게 만들거나, 도구 사용이 필요할 때 포기하게 만들어버림
방법론
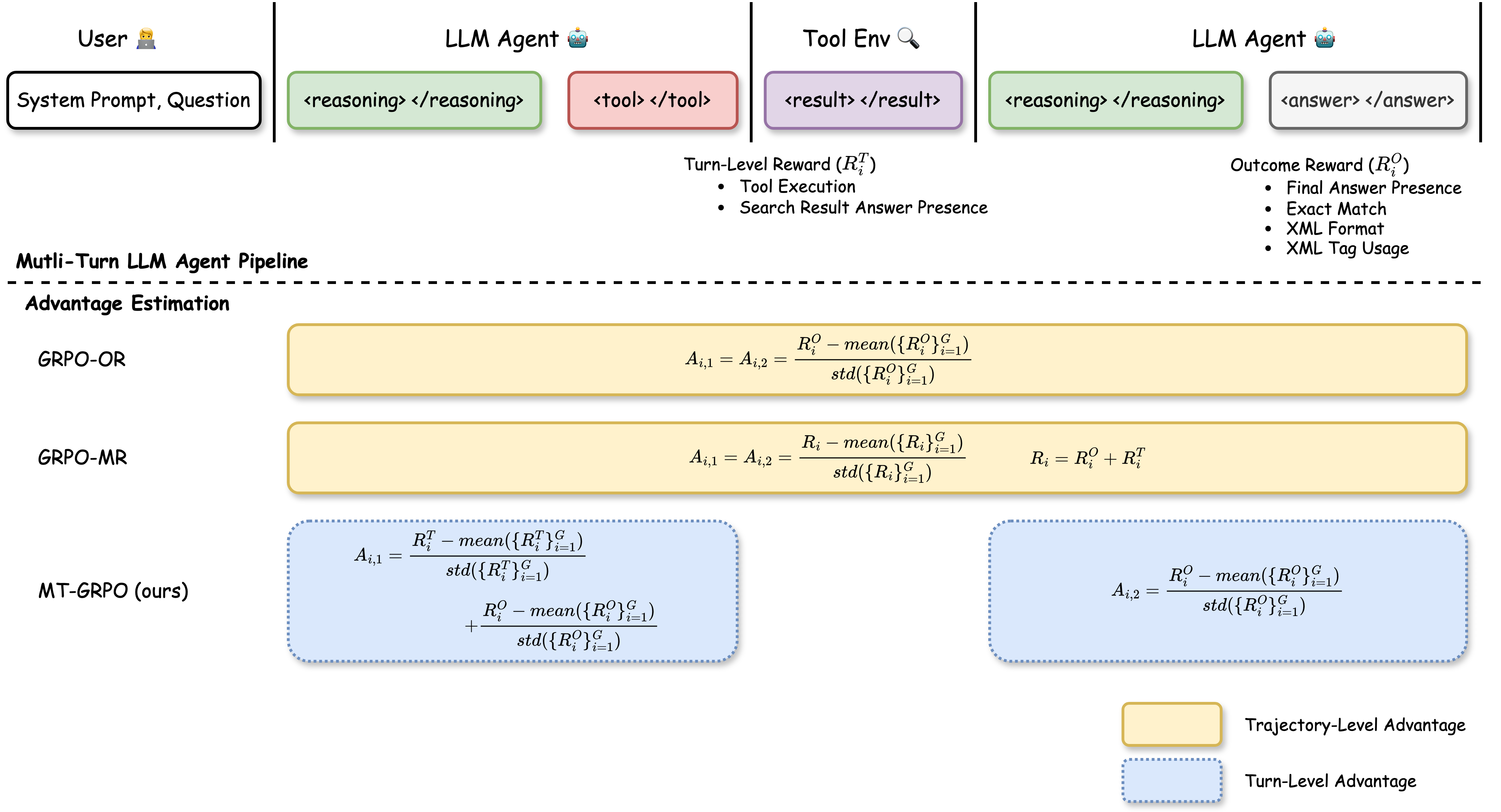
Markov Decision Process (MDP) 구조
- 도구 호출 기반 멀티턴 에이전트의 작업 자체를 bandit 공식이 아닌 MDP로 수식화
- Agent 구조: 위키피디아 검색 도구 기반으로, tool call - query writing - final answer의 2턴 구조로 동작
- Reward 구조: Turn-level & Outcome-level의 reward를 모두 사용
- Turn-level reward (): (1) Tool call 성공 여부, (2) 검색 결과 품질
- Outcome-level (): (1) 최종 답변 정확도, (2) 출력 형식 준수
Multi-Turn GRPO (MT-GRPO)
- 전체 trajectory의 모든 action에 대해서는 동일한 advantage(credit) 값을 사용하지 않고 각 턴에 대한 advantage를 별도로 계산
- Turn 1 (질문-검색):
- Turn 2 (검색-대답):
- Turn 1 (질문-검색):
결과
성능 지표
모델: Qwen2.5-7B
벤치마크: TriviaQA
대조군:
- GRPO-OR (outcome reward만)
- GRPO-MR (merged reward, 턴 레벨로 계산은 하지만 각각 업데이트아니고 합산해서 한번에)
- Tool 실행 성공률
- 검색 결과 내 답변 존재 여부
- 최종 답변 정확도 (EM)
- XML 포맷 준수
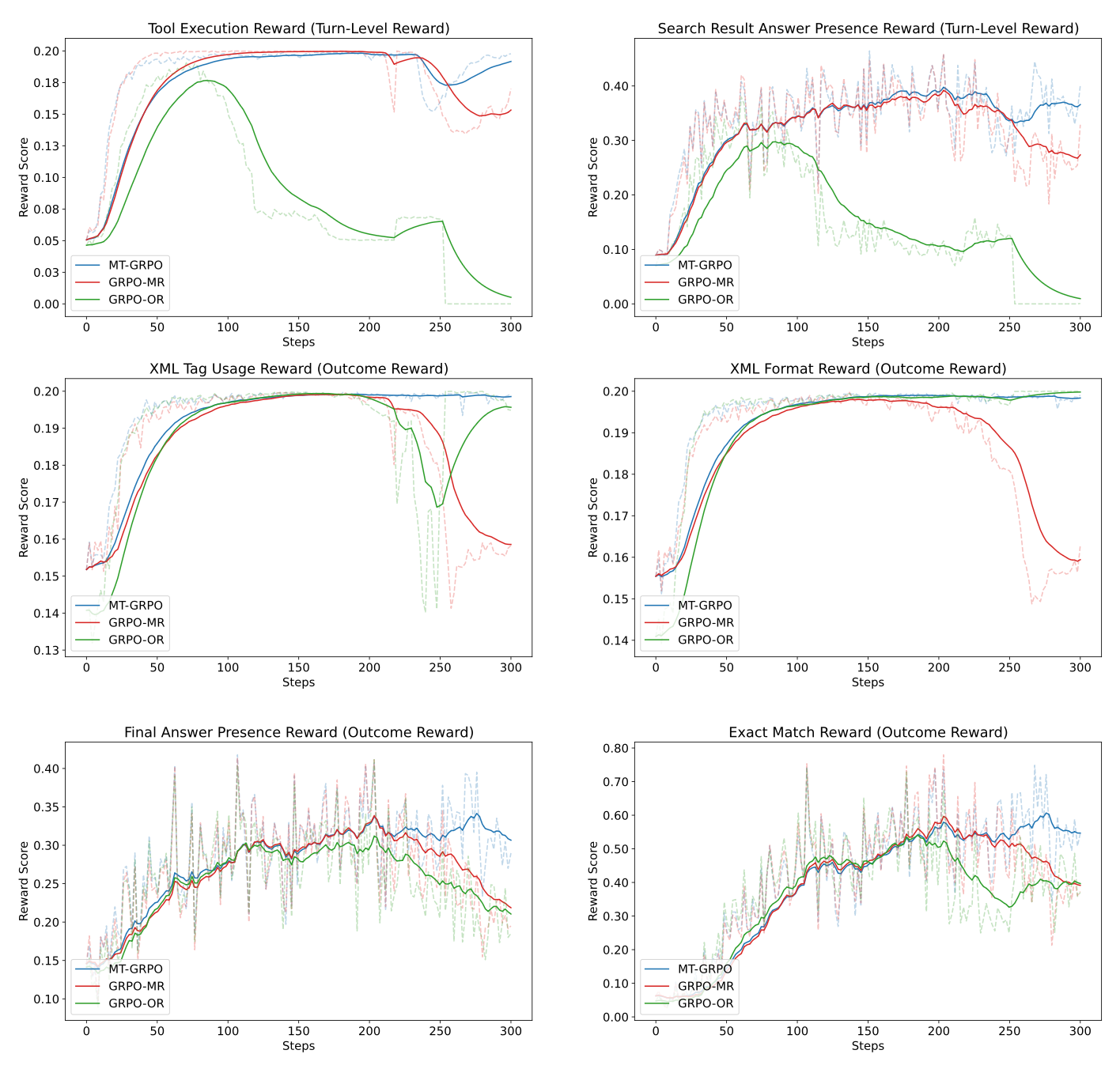
Tool 실행 성능
- 전반에 걸쳐 100% 성공률을 유지
- OR은 점진적으로 도구 사용을 줄이고 결국에 완전히 중단
답변 정확도
- MR이 33.46% 정도의 정확도를 보이는데 반해 MT는 50.10%의 정확도
학습 안정성
- 학습 중 분산이 더 낮음
- 총 300스텝 학습 중 200스텝 근처에서 tool 실행이 일시적으로 감소하는 현상이 발생했으나 MT-GRPO는 잘 복구함
- 특히 OR의 경우 비슷한 스텝 근처에서 XML 포맷도 무너질 뻔 하였고, MR의 경우에는 아예 해당 스텝부터 모든 성능 하락하며 학습 붕괴
시사점
- 어떤 특정한 효과적 방법론에 대해 소개한다기 보다는, "Multi-turn은 Multi-reward가 필요하다"는 증명 실험에 가까움
- ReAct 형태로 확장한다면 turn의 구분을 어떻게 해야하는지는 생각해봐야 할듯
<think>+<tool_call>-> tool call turn<think>+answer-> answer turn?

J의 틀에 몸을 녹여 맞추는 P