[2025.05.26] RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn RL
제안 배경
- 에이전트는 기존의 instruction chatbot 학습처럼 single turn 학습을 하는 경우, multi turn 작업(특히 stochastic한 작업들)에서 부족함
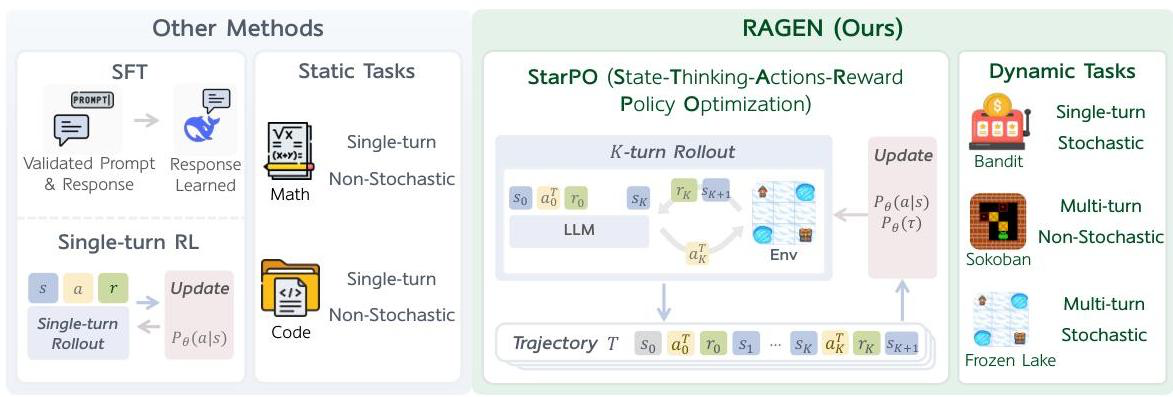
- Multi turn RL을 통해 에이전트의 self-evolution을 이해하고 개선하기 위한 프레임워크, RAGEN (Reasoning Agents through Generative Environments)을 제안
- 흥미롭게도 여기서는 바로 위의 MT-GRPO나 기존의 RL 알고리즘인 PPO, GRPO 등과 다르게 turn-level이 아닌 trajectory-level로 학습해야 좋다고 주장
방법론
-
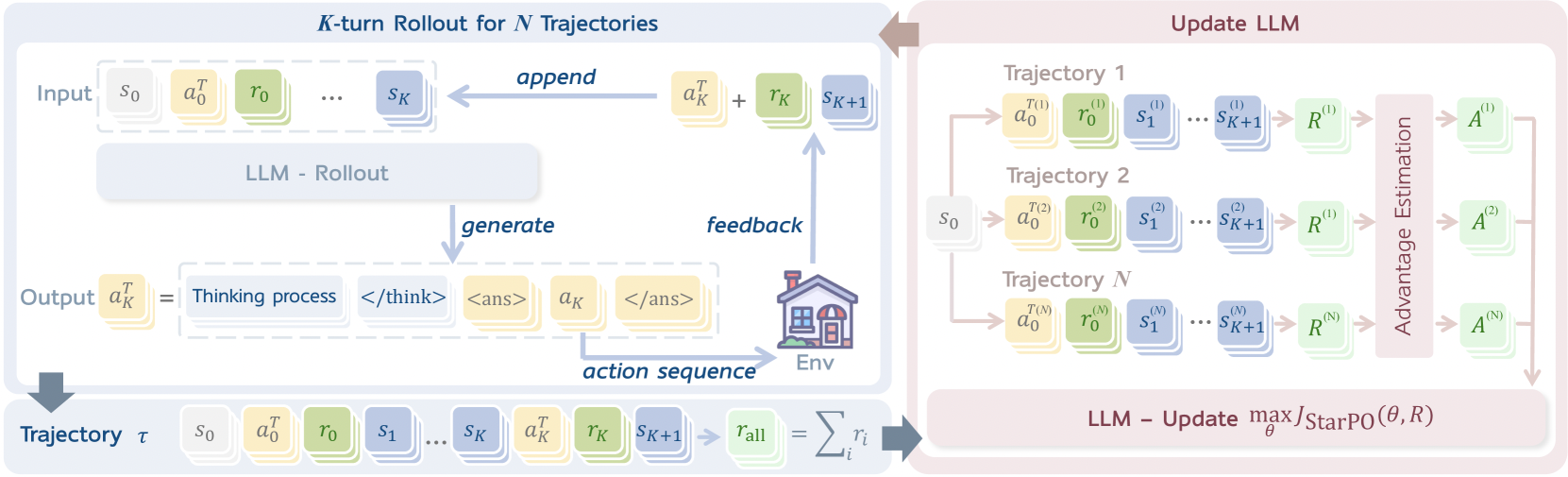
Multi-turn & Trajectory-level의 RL 프레임워크인 StarPO(State-Thinking-Actions-Reward policy optimization)를 제안
-
이 프레임워크도 MT-GRPO에서처럼 에이전트 학습을 MDP()로 수식화
State (): Observation sequence & Interaction history
Action (): LLM output
Transition dynamics & Reward generation ()- 에이전트 정책 는 현재 상태 와 히스토리 를 조건으로, 각 timestep 에서의 액션 를 생성
- 환경은 현재의 에 따라 reward 와 새로운 상태 를 반환
-
각 timestep에서 에이전트는 다음 XML 포맷의 응답을 생성하며, trajectory-level의 object function으로 함께 최적화
J_\text{StarPO}(\theta)=\mathbb{E}_{M,\tau\sim\pi_\theta}[R(\tau)] $$
결과
성능 지표
턴 수와 확률적 측면에서 서로 다른 4가지 task를 실험
이 중 WebShop은 실제 세계에 대한 이해 및 추론을 동반하며, 나머지는 minimalistic하고 controllable한 게임 환경임
- Bandit: single / stochastic
- Sokoban: multi / deterministic
- Frozen lake: multi / stochastic
- WebShop: multi / open-domain
Echo Trap 완화
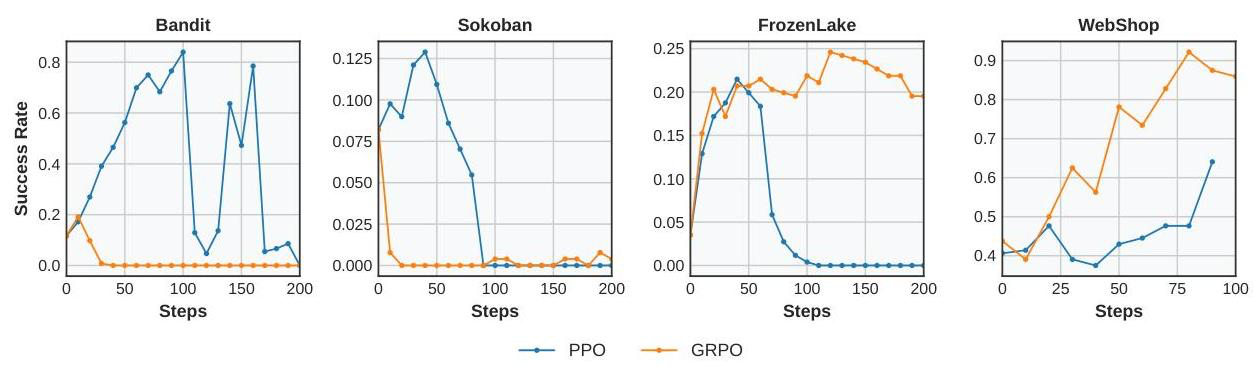
- 학습을 지속하면서 Echo trap이라는 학습 붕괴 현상이 발견됨
- 지속적인 학습에도 reward가 정체되거나 하락하는 현상
- Reward의 std로 측정된 행동 다양성 감소
- Grad. norm. 스파이크 다량 발생
- 메아리치듯이 자체 추론 패턴에 "갇혀" 재귀적으로 잘못 훈련되는 경우 (반복이라는 뜻인가?)
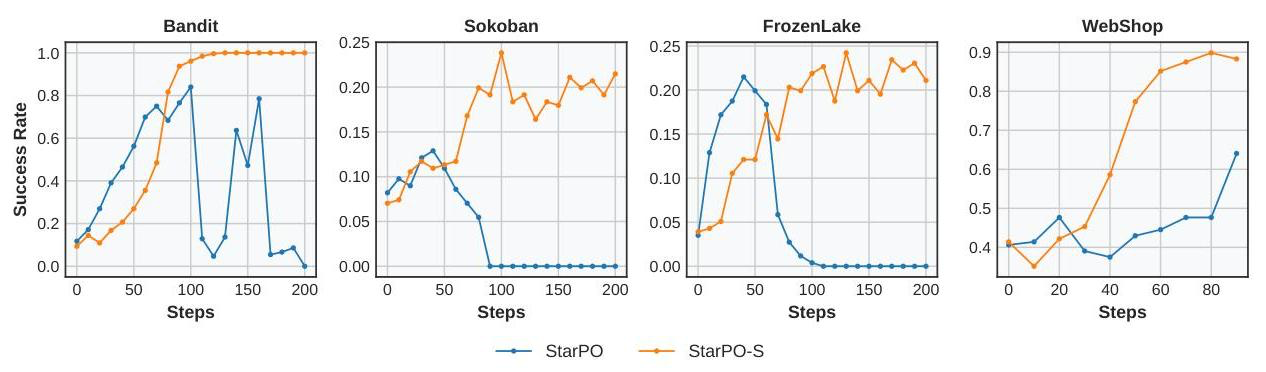
- 이를 해결하기 위해 3가지 안정화 기술을 추가 -> StarPO-S
- Uncertainty 기반 필터링: Reward의 std에 따라 가장 "불확실한" 상위 p% 훈련 프롬프트만 유지
- KL-term 제거: PPO에서 KL div. 페널티를 제거해 더 공격적인 탐색을 허용 (조기에 non-optimal policy로 갇히는 것을 방지)
- 비대칭 clipping: 예를 들어, =0.28, =0.20 처럼 positive advantage로부터 더 적극적인 학습을 가능하도록
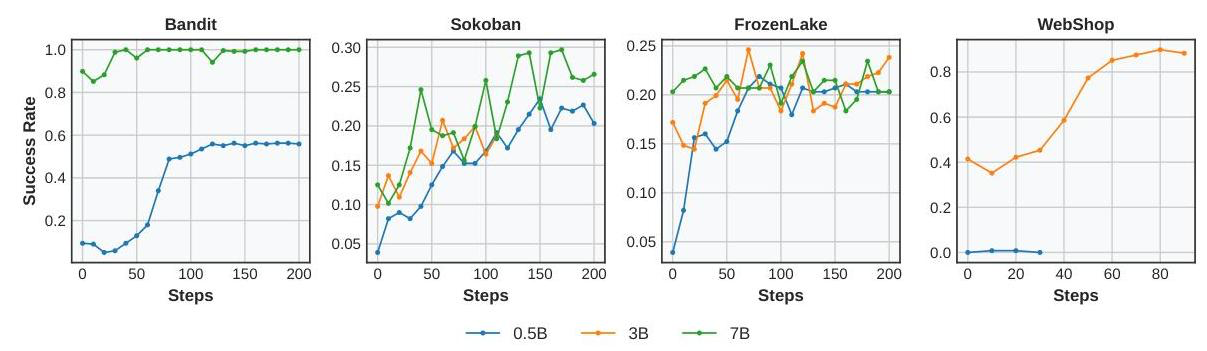
- 최종적으로 Qwen2.5 패밀리의 0.5B, 3B, 7B 모델에 대해 일관적으로 4가지 작업에 대한 성능 향상을 관찰함
시사점
-
상술했듯이 재미있게도 MT-GRPO의 GRPO-MR 방식의 trajectory-level reward 기반 RL 학습임
- 학습 자체는 그래프로 보건데 MT-GRPO쪽이 조금 더 안정적이어 보이나..
- 물론 여기서는 fixed 2-turn이 아니라 말 그대로 multi-turn 추론을하고 web search를 사용하면서 조금 더 사실적인 에이전트 환경을 구현했다고 봐야함
-
만약 직접 사용한다고 한다면.. 사실 turn-level reward를 사용하는 것이 원칙상 조금 더 맞다고 느껴지나, GRPO의 자비 없는 동작 시간을 봤을 때 trajectory-level로 사용해야할 수도 있다고 느꼈음
- 만약 trajectory-level로 사용한다면 참고할만한 논문
- 그리고 기본적으로 StarPO는 GRPO 뿐 아니라 PPO도 사용 가능한, 알고리즘에 무관한 프레임워크라서 참고할 부분들이 있을 듯

J의 틀에 몸을 녹여 맞추는 P