.png)
[혼자 공부하는 머신러닝+딥러닝] 책에 기반한 정리글입니다.
전체 소스코드는 아래 Github 링크에서 확인할 수 있습니다.
0. 개요
이번 편에서는 딥러닝으로 댓글을 분석해서 평가가 긍정적인지, 부정적이지 판단해보려 한다. 순차데이터와 순환신경망(Recurrent Neural Network)의 개념을 알아보고, 순환 신경망으로 IMDB 리뷰 데이터를 학습하여 긍정과 부정 댓글로 분류해본다.
1. 순차 데이터
순차 데이터란 텍스트나 시계열 데이터와 같이 순서에 의미가 있는 데이터이다.
대표적인 순차 데이터로는 글, 대화, 일자별 날씨, 일자별 판매 실적 등이 있다.
이번에 분석할 댓글, 즉 텍스트 데이터는 단어의 순서가 중요한 순차 데이터이다. 이 순서를 유지하며 신경망에 주입해야 하는데, 이를 위해 이전에 입력한 데이터를 기억하는 기능이 필요하다.
완전 연결 신경망, 합성곱 신경망은 이런 기능이 없다. 이들은 하나의 샘플을 사용하여 계산을 수행하면 그 샘플은 버려지고, 재사용되지 않는다.
이렇게 입력 데이터의 흐름이 앞으로만 전달되는 것을 피드포워드 신경망이라고 한다.
반대로, 이전에 처리했던 샘플을 다음 샘플을 처리하는데 재사용하며 데이터가 순환되는 신경망이 순환 신경망이다.
2. 순환 신경망 (RNN)
순환 신경망은 일반적인 완전 연결 신경망이랑 거의 비슷하나, 순환 신경망은 이전 데이터의 처리 흐름을 순환하는 고리 하나가 추가된다.
뉴런의 출력이 다시 자기 자신으로 전달되는데, 즉 어떤 샘플을 처리할 때 바로 이전에 사용했던 데이터를 재사용하는 것이다.
이렇게 샘플을 처리하는 한 단계를 타임스텝이라고 부르며, 순환신경망은 이전 타임스텝의 샘플을 기억하지만, 타임스텝이 오래될수록 순환되는 정보는 희미해진다.
순환 신경망에서는 특별히 층을 셀이라고 부른다. 한 셀에는 여러 개의 뉴런이 있지만, 뉴런을 모두 표시하지 않고 하나의 셀로 층을 표현한다. 또 셀의 출력을 은닉 상태라고 부른다.
입력에 어떤 가중치를 곱하고, 활성화 함수를 통과시켜 다음층으로 보내는 구조는 합성곱 신경망과 같으나, 층의 출력을 다음 타임 스텝에 재사용하는 것이 다르다.
은닉층의 활성화 함수로는 하이퍼볼릭 탄젠트(tanh)를 사용한다. 시그모이드 함수와는 달리 -1 ~ 1 사이의 범위를 가진다.
3. IMDB 리뷰 분류
3-1. 데이터 준비하기
IMDB 리뷰 데이터셋을 적재한다. 리뷰를 감상평에 따라 긍정과 부정으로 분류해 놓은 데이터셋인데, 총 50,000개의 샘플로 이루어져 있고 훈련 데이터와 테스트 데이터에 25,000개씩 나누어져 있다.
실제 IMDB 리뷰 데이터셋은 영어로 된 문장이지만, 텐서플로에는 이미 정수로 바꾼 데이터가 포함되어 있다. 여기에서는 가장 자주 등장하는 단어 500개만 사용한다.
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(num_words=500)
print(len(train_input[0]))
print(len(train_input[1]))출력
(25000,) (25000,)
218
189첫 번째 리뷰의 길이는 218개의 토큰, 두 번째는 189개의 토큰으로 이루어져 있다.
print(train_input[0])출력
[1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 458, 2, 66, 2, 4,
173, 36, 256, 5, 25, 100, 43, 2, 112, 50, 2, 2, 9, 35, 480, ... ]텐서플로의 IMDB 리뷰 데이터는 정수로 변환되어 있다. num_words=500 으로 지정했기 때문에 어휘 사전에 없는 단어는 모두 2로 표시된다.
print(train_target[:20])출력
[1 0 0 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 1]타깃 데이터는 0(부정) 과 1(긍정)으로 나누어진다.
from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)훈련 데이터의 20%정도를 검증 세트로 떼어 놓는다.
3-2. 데이터 분석과 패딩
평균적인 리뷰, 가장 짧은 리뷰, 가장 긴 리뷰의 길이를 확인하기 위해 먼저 각 리뷰의 길이를 계산해 넘파이 배열에 담아 그래프로 표현한다.
import numpy as np
import matplotlib.pyplot as plt
lengths = np.array([len(x) for x in train_input])
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()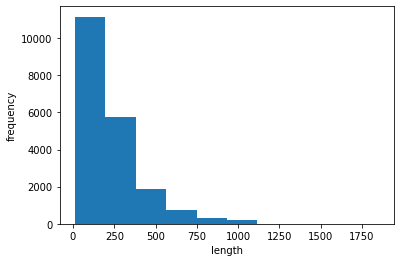
대부분의 리뷰 길이는 300개 미만인 것을 볼 수 있다.
리뷰는 대부분 짧기 때문에 이 예제에서는 100개의 단어만 사용하기로 한다.
이 리뷰들의 길이를 맞추기 위해 패딩이 필요하다.
pad_sequences() 함수를 통해 시퀸스 데이터의 길이를 맞출 수 있다.
짧은 리뷰는 앞에서부터 0 토큰을 채우고, 긴 리뷰는 잘라내는데, 만약 pad_sequences() 의 매개변수 padding를 기본값인 pre에서 post로 바꾸면 샘플의 뒷부분으로 패딩할 수 있다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)
val_seq = pad_sequences(val_input, maxlen=100)
print(train_seq.shape)출력 (20000, 100)train_seq는 이제 (20000, 100) 크기의 2차원 배열임을 알 수 있다.
3-3. 원-핫 인코딩으로 데이터 바꾸기
케라스는 여러 종류의 순환층 클래스를 제공하는데, 가장 간단한 것은 SimpleRNN 클래스이다. 이 문제는 이진 분류이므로 마지막 출력층은 1개의 뉴런을 가지고 시그모이드 활성화 함수를 사용한다.
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 500)))
model.add(keras.layers.Dense(1, activation='sigmoid')) #이진 분류뉴런 갯수를 8개로 지정하고, 샘플의 길이가 100이고 500개의 단어만 사용하도록 설정했기 때문에 input_shape를 (100,500)으로 둔다.
순환층도 활성화 함수를 사용하는데 기본 매개변수 acivation의 기본값은 tanh로, 하이퍼볼릭 탄젠트 함수를 사용한다.
그러나 토큰을 정수로 변환한 데이터를 신경망에 주입하면, 큰 정수가 큰 활성화 출력을 만들게 된다.
이 정수들 사이에는 어떤 관련이 없기 때문에 정수값에 있는 크기 속성을 없애고 각 정수를 고유하게 표현하기 위해 원-핫 인코딩을 사용한다.
keras.utils 패키지의 to_categorical() 함수를 사용하여 훈련세트와 검증 세트를 원-핫 인코딩으로 바꾸어준다.
train_oh = keras.utils.to_categorical(train_seq)
val_oh = keras.utils.to_categorical(val_seq)
print(train_oh.shape)출력 (20000, 100, 500)정수 하나마다 500차원의 배열로 변경되었다.
print(train_oh[0][0][:12])
print(np.sum(train_oh[0][0]))출력
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
1.0첫 리뷰의 첫 단어를 원-핫 인코딩시킨 결과이다.
모든 원소의 값을 더하면 1임을 알 수 있다.
3-4. 순환 신경망 훈련하기
RMSprop의 기본 학습률 0.001을 사용하지 않기 위해 별도의 RMSprop 객체를 만들어 학습률을 0.0001로 지정한다. 에포크 횟수는 100으로 늘리고, 배치 크기는 64개로 지정한다.
체크포인트와 조기 종료를 구성하고, 신경망을 훈련한다.
rmsprop = keras.optimizers.RMSprop(learning_rate = 1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model.fit(train_oh, train_target, epochs=100, batch_size=64, validation_data = (val_oh, val_target), callbacks=[checkpoint_cb, early_stopping_cb])출력
Epoch 1/100
313/313 [==============================] - 14s 41ms/step - loss: 0.6968 - accuracy: 0.5038 - val_loss: 0.6970 - val_accuracy: 0.5008
Epoch 2/100
313/313 [==============================] - 12s 40ms/step - loss: 0.6898 - accuracy: 0.5366 - val_loss: 0.6878 - val_accuracy: 0.5494
Epoch 3/100
313/313 [==============================] - 12s 40ms/step - loss: 0.6800 - accuracy: 0.5793 - val_loss: 0.6774 - val_accuracy: 0.5900
...
Epoch 42/100
313/313 [==============================] - 12s 38ms/step - loss: 0.3983 - accuracy: 0.8228 - val_loss: 0.4540 - val_accuracy: 0.7922검증 세트에 대한 정확도는 약 79% 정도이다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()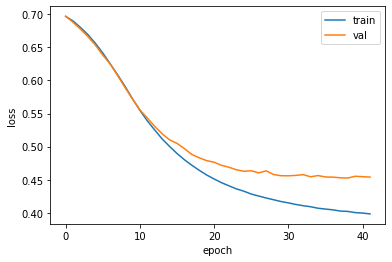
40번째 에포크에서 감소가 둔해짐을 알 수 있다.
3-5. 단어 임베딩 사용하기
원-핫 인코딩의 단점은 입력 데이터가 매우 커진다는 것이다.
이를 해결하기 위해 순환 신경망에서 단어 임베딩을 사용할 수 있다.
단어 임베딩은 각 단어를 고정된 크기의 실수 벡터로 바꾸어 준다. 이렇게 단어 임베딩으로 만들어진 벡터는 원-핫 인코딩으로 된 벡터보다 훨씬 의미있는 값으로 채워져 있기 때문에 자연어 처리에서 좋은 성능을 내는 경우가 많다.
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500, 16, input_length=100))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))Embedding 클래스의 첫 매개변수 500은 어휘 사전의 크기이며, 두 번째 16은 임베딩 벡터의 크기이다. 세 번째 input_length는 입력 시퀸스의 길이이다.

좋아연.
1. 원-핫 인코딩 -> 단어 임베딩
2. RNN
3. RMNsorp
4. number of nureon
5. sample size
6. pad_sequence to padding
7. batch_size, epochs