Overview
In Chapter 11, General Bayesian estimators
MMSE takes a simple form when x \text{x} x θ \theta θ Gaussian→ \rightarrow → 1 s t 1^{st} 1 s t 2 n d 2^{nd} 2 n d
General MMSE(without the Gaussian assumption) requires multi-dimensional integrations to implement → \rightarrow → undesirable
In Chapter 12, Linear Bayesian estimators
What to do if we can't assume Gaussian but want MMSE?
Keep the MMSE criteria, but... restrict the form of the estimator to be LINEAR
LMMSE = Wiener Filter
Linear MMSE Estimation
Scalar Paramter Case
Estimate θ \theta θ
Given a data vector x = [ x [ 0 ] x [ 1 ] , ⋯ , x [ N − 1 ] ] T \text{x} = [x[0]\;x[1],\;\cdots,x[N-1]]^T x = [ x [ 0 ] x [ 1 ] , ⋯ , x [ N − 1 ] ] T
Assume joint PDF p ( x , θ ) p(\text{x},\theta) p ( x , θ )
Statistical dependence between x \text{x} x θ \theta θ
Goal : Make the best possible estimate while using a linear (or affine) form for the estimatorθ ^ = ∑ n = 0 N − 1 a n x [ n ] + a N \hat \theta=\sum^{N-1}_{n=0} a_nx[n]+a_N θ ^ = n = 0 ∑ N − 1 a n x [ n ] + a N
Choose a n a_n a n Bmse ( θ ^ ) = E [ ( θ − θ ^ ) 2 ] → linear MMSE estimator \text{Bmse}(\hat\theta)=E\left[(\theta-\hat\theta)^2\right] \rightarrow \text{linear MMSE estimator} Bmse ( θ ^ ) = E [ ( θ − θ ^ ) 2 ] → linear MMSE estimator
Derivation of Optimal LMMSE CoefficientsBmse ( θ ^ ) = E [ ( θ − ∑ n = 0 N − 1 a n x [ n ] − a N ) 2 ] \text{Bmse}(\hat \theta)=E\left[\left(\theta-\sum^{N-1}_{n=0}a_nx[n]-a_N\right)^2\right] Bmse ( θ ^ ) = E ⎣ ⎢ ⎡ ( θ − n = 0 ∑ N − 1 a n x [ n ] − a N ) 2 ⎦ ⎥ ⎤
Step 1 : Focus on a N a_N a N ∂ ∂ a N E [ ( θ − ∑ n = 0 N − 1 a n x [ n ] − a N ) 2 ] = − 2 E [ θ − ∑ n = 0 N − 1 a n x [ n ] − a N ] = 0 → a N = E ( θ ) − ∑ n = 0 N − 1 a n E ( x [ n ] ) \frac{\partial}{\partial a_N}E\left[\left(\theta-\sum^{N-1}_{n=0} a_nx[n]-a_N\right)^2\right]\\[0.2cm] =-2E\left[\theta-\sum^{N-1}_{n=0}a_nx[n]-a_N\right]=0\\[0.3cm] \rightarrow a_N=E(\theta)-\sum^{N-1}_{n=0}a_nE(x[n]) ∂ a N ∂ E ⎣ ⎢ ⎡ ( θ − n = 0 ∑ N − 1 a n x [ n ] − a N ) 2 ⎦ ⎥ ⎤ = − 2 E [ θ − n = 0 ∑ N − 1 a n x [ n ] − a N ] = 0 → a N = E ( θ ) − n = 0 ∑ N − 1 a n E ( x [ n ] ) Step 2 : Plug-In Step 1, Result for a N a_N a N Bmse ( θ ^ ) = E { [ ∑ n = 0 N − 1 a n ( x [ n ] − E ( x [ n ] ) ) − ( θ − E ( θ ) ) ] 2 } \text{Bmse}(\hat \theta)=E\left\{\left[\sum^{N-1}_{n=0}a_n(x[n]-E(x[n]))-(\theta-E(\theta))\right]^2\right\} Bmse ( θ ^ ) = E ⎩ ⎪ ⎨ ⎪ ⎧ [ n = 0 ∑ N − 1 a n ( x [ n ] − E ( x [ n ] ) ) − ( θ − E ( θ ) ) ] 2 ⎭ ⎪ ⎬ ⎪ ⎫ a = [ a 0 a 1 ⋯ a N − 1 ] T \text{a}=[a_0\;a_1\;\cdots\;a_{N-1}]^T a = [ a 0 a 1 ⋯ a N − 1 ] T Bmse ( θ ^ ) = E { [ a T ( x − E ( x ) ) − ( θ − E ( θ ) ) ] 2 } = E [ a T ( x − E ( x ) ( x − E ( x ) ) T a ] − E [ a T ( x − E ( x ) ) ( θ − E ( θ ) ) ] − E [ ( θ − E ( θ ) ) ( x − E ( x ) ) T a ] + E [ ( θ − E ( θ ) ) 2 ] = a T C x x a − a T C x θ − C θ x a + C θ θ = a T C x x a − 2 a T C x θ + C θ θ \text{Bmse}(\hat\theta)=E\left\{\left[a^T(\text{x}-E(\text{x}))-(\theta-E(\theta))\right]^2\right\} \\[0.2cm] =E\left[a^T(\text{x}-E(\text{x})(\text{x}-E(\text{x}))^Ta\right] - E\left[a^T(\text{x}-E(\text{x}))(\theta-E(\theta))\right]\\[0.2cm] -E\left[(\theta-E(\theta))(\text{x}-E(\text{x}))^Ta\right]+E\left[(\theta-E(\theta))^2\right]\\[0.2cm] =a^TC_{xx}a-a^TC_{x\theta}-C_{\theta x}a+C_{\theta\theta}=a^TC_{xx}a-2a^TC_{x\theta}+C_{\theta\theta} Bmse ( θ ^ ) = E { [ a T ( x − E ( x ) ) − ( θ − E ( θ ) ) ] 2 } = E [ a T ( x − E ( x ) ( x − E ( x ) ) T a ] − E [ a T ( x − E ( x ) ) ( θ − E ( θ ) ) ] − E [ ( θ − E ( θ ) ) ( x − E ( x ) ) T a ] + E [ ( θ − E ( θ ) ) 2 ] = a T C x x a − a T C x θ − C θ x a + C θ θ = a T C x x a − 2 a T C x θ + C θ θ Step 3 : Minimize w.r.t. a \text{a} a ∂ Bmse ( θ ^ ) ∂ a = 2 C x x a − 2 C x θ = 0 → a = C x x − 1 C x θ \frac{\partial\text{Bmse}(\hat\theta)}{\partial a}=2C_{xx}a-2C_{x\theta}=0\\[0.2cm] \rightarrow a=C^{-1}_{xx}C_{x\theta} ∂ a ∂ Bmse ( θ ^ ) = 2 C x x a − 2 C x θ = 0 → a = C x x − 1 C x θ Step 4 : Combine resultsθ ^ = a T x + a N = C x θ T C x x − 1 x + E ( θ ) − C x θ T C x x − 1 E ( x ) → θ ^ = E ( θ ) + C θ x C x x − 1 ( x − E ( x) ) \hat \theta=a^T\text{x}+a_N=C^T_{x\theta}C^{-1}_{xx}\text{x}+E(\theta)-C^T_{x\theta}C^{-1}_{xx}E(\text{x})\\[0.2cm] \rightarrow\hat \theta=E(\theta)+C_{\theta x}C^{-1}_{xx}(\text{x}-E(\text{x)}) θ ^ = a T x + a N = C x θ T C x x − 1 x + E ( θ ) − C x θ T C x x − 1 E ( x ) → θ ^ = E ( θ ) + C θ x C x x − 1 ( x − E ( x) ) Step 5 : Find Minimum BmseBmse ( θ ^ ) = C x θ T C x x − 1 C x x C x x − 1 C x θ − 2 C x θ T C x x − 1 C x θ + C θ θ = C θ θ − C θ x C x x − 1 C x θ \text{Bmse}(\hat\theta)=C^T_{x\theta}C^{-1}_{xx}C_{xx}C^{-1}_{xx}C_{x\theta}-2C^T_{x\theta}C^{-1}_{xx}C_{x\theta}+C_{\theta\theta}\\[0.2cm] =C_{\theta\theta}-C_{\theta x}C^{-1}_{xx}C_{x\theta} Bmse ( θ ^ ) = C x θ T C x x − 1 C x x C x x − 1 C x θ − 2 C x θ T C x x − 1 C x θ + C θ θ = C θ θ − C θ x C x x − 1 C x θ
Linear MMSE - Example
DC Level in WGN with Uniform Prior PDFx [ n ] = A + w [ n ] , n = 0 , ⋯ , N − 1 A : parameter to estimate ∼ U [ − A 0 , A 0 ] , w [ n ] : WGN ∼ N ( 0 , σ 2 ) x[n]=A+w[n],\;n=0,\;\cdots,N-1\\[0.2cm] A:\text{parameter to estimate }\sim U[-A_0,A_0],\;w[n]:\text{WGN}\sim\mathcal{N}(0,\sigma^2) x [ n ] = A + w [ n ] , n = 0 , ⋯ , N − 1 A : parameter to estimate ∼ U [ − A 0 , A 0 ] , w [ n ] : WGN ∼ N ( 0 , σ 2 )
Closed form solution is available
We don't need to know the PDF. Only the first and second moments are required
Statistical independence between A A A w \text{w} w uncorrelated
Required information for LMMSE estimation :[ E ( θ ) E ( x ) ] , [ C θ θ C θ x C x θ C x x ] \left[\begin{matrix}E(\theta)\\E(\text{x})\end{matrix}\right],\; \left[\begin{matrix}C_{\theta\theta}&C_{\theta x}\\C_{x\theta}&C_{xx}\end{matrix}\right] [ E ( θ ) E ( x ) ] , [ C θ θ C x θ C θ x C x x ]
Note that LMMSE estimator is suboptimal due to the linearity constraint
Geometrical Interpretations
Zero mean random variables θ ′ = θ − E ( θ ) , x ′ = x − E ( x ) \theta'=\theta-E(\theta),\;\text{x}'=\text{x}-E(\text{x}) θ ′ = θ − E ( θ ) , x ′ = x − E ( x ) Find θ ^ = ∑ n = 0 N − 1 a n x [ n ] \hat \theta=\sum^{N-1}_{n=0}a_nx[n] θ ^ = ∑ n = 0 N − 1 a n x [ n ] Bmse ( θ ^ ) = E [ ( θ − θ ^ ) 2 ] \text{Bmse}(\hat \theta)=E\left[(\theta-\hat\theta)^2\right] Bmse ( θ ^ ) = E [ ( θ − θ ^ ) 2 ]
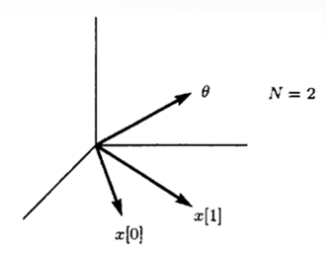
Geometric analogy
θ , x [ 0 ] , x [ 1 ] , … , x [ N − 1 ] \theta,x[0],x[1],\dots,x[N-1] θ , x [ 0 ] , x [ 1 ] , … , x [ N − 1 ] Norm : ∣ ∣ x ∣ ∣ = E ( x 2 ) = var ( x ) ||x|| = \sqrt{E(x^2)}=\sqrt{\text{var}(x)} ∣ ∣ x ∣ ∣ = E ( x 2 ) = var ( x ) Inner product : ( x , y ) = E ( x y ) , ( x , x ) = E ( x 2 ) = ∣ ∣ x ∣ ∣ 2 (x,y)=E(xy),(x,x)=E(x^2)=||x||^2 ( x , y ) = E ( x y ) , ( x , x ) = E ( x 2 ) = ∣ ∣ x ∣ ∣ 2 x x x y y y orthogonal if ( x , y ) = E ( x y ) = 0 (x,y) = E(xy) =0 ( x , y ) = E ( x y ) = 0
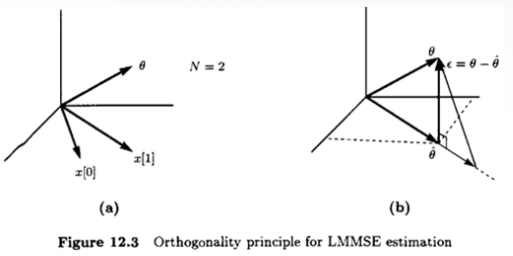
{ a n } \{a_n\} { a n } E [ ( θ − θ ^ ) 2 ] = E [ ( θ − ∑ n = 0 N − 1 a n x [ n ] ) 2 ] = ∣ ∣ θ − ∑ n = 0 N − 1 a n x [ n ] ∣ ∣ 2 E\left[(\theta-\hat\theta)^2\right]=E\left[\left(\theta-\sum^{N-1}_{n=0}a_nx[n]\right)^2\right]=\left|\left|\theta-\sum^{N-1}_{n=0}a_nx[n]\right|\right|^2 E [ ( θ − θ ^ ) 2 ] = E ⎣ ⎢ ⎡ ( θ − n = 0 ∑ N − 1 a n x [ n ] ) 2 ⎦ ⎥ ⎤ = ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ θ − n = 0 ∑ N − 1 a n x [ n ] ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∣ 2
ϵ = θ − θ ^ \epsilon=\theta-\hat\theta ϵ = θ − θ ^ orthogonal to the subspace spanned by { x [ 0 ] , x [ 1 ] , ⋯ , x [ N − 1 ] } \{x[0],x[1],\cdots,x[N-1]\} { x [ 0 ] , x [ 1 ] , ⋯ , x [ N − 1 ] } ϵ ⊥ x [ 0 ] , x [ 1 ] , … , x [ N − 1 ] \epsilon \perp x[0], x[1], \dots, x[N-1] ϵ ⊥ x [ 0 ] , x [ 1 ] , … , x [ N − 1 ] E [ ( θ − θ ^ ) x [ n ] ] = 0 , n = 0 , 1 , ⋯ , N − 1 E[(\theta-\hat \theta)x[n]] =0,\;n=0,1,\cdots,N-1 E [ ( θ − θ ^ ) x [ n ] ] = 0 , n = 0 , 1 , ⋯ , N − 1 Orthogonality principle or Projection theorem)E [ ( θ − ∑ m = 0 N − 1 a m x [ m ] ) x [ n ] ] = 0 , n = 0 , 1 , … , N − 1 ⟹ ∑ m = 0 N − 1 a m E ( x [ m ] x [ n ] ) = E ( θ x [ n ] ) , n = 0 , 1 , … , N − 1 E \left[ \left( \theta - \sum_{m=0}^{N-1} a_m x[m] \right) x[n] \right] = 0, \quad n = 0, 1, \dots, N-1\\[0.2cm] \implies \sum_{m=0}^{N-1} a_m E(x[m] x[n]) = E(\theta x[n]), \quad n = 0, 1, \dots, N-1 E [ ( θ − m = 0 ∑ N − 1 a m x [ m ] ) x [ n ] ] = 0 , n = 0 , 1 , … , N − 1 ⟹ m = 0 ∑ N − 1 a m E ( x [ m ] x [ n ] ) = E ( θ x [ n ] ) , n = 0 , 1 , … , N − 1 In matrix form,[ E ( x 2 [ 0 ] ) E ( x [ 0 ] x [ 1 ] ) ⋯ E ( x [ 0 ] x [ N − 1 ] ) E ( x [ 1 ] x [ 0 ] ) E ( x 2 [ 1 ] ) ⋯ E ( x [ 1 ] x [ N − 1 ] ) ⋮ ⋮ ⋱ ⋮ E ( x [ N − 1 ] x [ 0 ] ) E ( x [ N − 1 ] x [ 1 ] ) ⋯ E ( x 2 [ N − 1 ] ) ] [ a 0 a 1 ⋮ a N − 1 ] = [ E ( θ x [ 0 ] ) E ( θ x [ 1 ] ) ⋮ E ( θ x [ N − 1 ] ) ] → C x x a = C x θ so a = C x x − 1 C x θ θ ^ = a T x = C x θ T C x x − 1 x \begin{bmatrix} E(x^2[0]) & E(x[0]x[1]) & \cdots & E(x[0]x[N-1]) \\ E(x[1]x[0]) & E(x^2[1]) & \cdots & E(x[1]x[N-1]) \\ \vdots & \vdots & \ddots & \vdots \\ E(x[N-1]x[0]) & E(x[N-1]x[1]) & \cdots & E(x^2[N-1]) \end{bmatrix} \begin{bmatrix} a_0 \\ a_1 \\ \vdots \\ a_{N-1} \end{bmatrix} = \begin{bmatrix} E(\theta x[0]) \\ E(\theta x[1]) \\ \vdots \\ E(\theta x[N-1]) \end{bmatrix}\\[0.2cm] \rightarrow \mathbf{C}_{xx} \mathbf{a} = \mathbf{C}_{x\theta} \quad \text{so} \quad \mathbf{a} = \mathbf{C}_{xx}^{-1} \mathbf{C}_{x\theta}\\[0.2cm] \hat{\theta} = \mathbf{a}^T \mathbf{x} = \mathbf{C}_{x\theta}^T \mathbf{C}_{xx}^{-1} \mathbf{x} ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ E ( x 2 [ 0 ] ) E ( x [ 1 ] x [ 0 ] ) ⋮ E ( x [ N − 1 ] x [ 0 ] ) E ( x [ 0 ] x [ 1 ] ) E ( x 2 [ 1 ] ) ⋮ E ( x [ N − 1 ] x [ 1 ] ) ⋯ ⋯ ⋱ ⋯ E ( x [ 0 ] x [ N − 1 ] ) E ( x [ 1 ] x [ N − 1 ] ) ⋮ E ( x 2 [ N − 1 ] ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 0 a 1 ⋮ a N − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ E ( θ x [ 0 ] ) E ( θ x [ 1 ] ) ⋮ E ( θ x [ N − 1 ] ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ → C x x a = C x θ so a = C x x − 1 C x θ θ ^ = a T x = C x θ T C x x − 1 x
BmseBmse ( θ ^ ) = ∥ θ − ∑ n = 0 N − 1 a n x [ n ] ∥ 2 = E [ ( θ − ∑ n = 0 N − 1 a n x [ n ] ) 2 ] = E [ ( θ − ∑ n = 0 N − 1 a n x [ n ] ) ( θ − ∑ m = 0 N − 1 a m x [ m ] ) ] = E ( θ 2 ) − ∑ n = 0 N − 1 a n E ( x [ n ] θ ) − ∑ m = 0 N − 1 a m E ( θ x [ m ] ) + ∑ n = 0 N − 1 ∑ m = 0 N − 1 a n a m E ( x [ n ] x [ m ] ) = C θ θ − a T C x θ = C θ θ − C x θ T C x x − 1 C x θ = C θ θ − C x θ C x x − 1 C x θ \text{Bmse}(\hat{\theta}) = \left\lVert \theta - \sum_{n=0}^{N-1} a_n x[n] \right\rVert^2 = \mathbb{E} \left[ \left( \theta - \sum_{n=0}^{N-1} a_n x[n] \right)^2 \right]\\[0.2cm] = \mathbb{E} \left[ \left( \theta - \sum_{n=0}^{N-1} a_n x[n] \right) \left( \theta - \sum_{m=0}^{N-1} a_m x[m] \right) \right]\\[0.2cm] = \mathbb{E}(\theta^2) - \sum_{n=0}^{N-1} a_n \mathbb{E}(x[n] \theta) - \sum_{m=0}^{N-1} a_m \mathbb{E}(\theta x[m]) + \sum_{n=0}^{N-1} \sum_{m=0}^{N-1} a_n a_m \mathbb{E}(x[n] x[m])\\[0.2cm] = C_{\theta\theta} - \mathbf{a}^T \mathbf{C}_{x\theta} = C_{\theta\theta} - \mathbf{C}_{x\theta}^T \mathbf{C}_{xx}^{-1} \mathbf{C}_{x\theta}= C_{\theta\theta} - C_{x\theta} \mathbf{C}_{xx}^{-1} C_{x\theta} Bmse ( θ ^ ) = ∥ ∥ ∥ ∥ ∥ ∥ θ − n = 0 ∑ N − 1 a n x [ n ] ∥ ∥ ∥ ∥ ∥ ∥ 2 = E ⎣ ⎢ ⎡ ( θ − n = 0 ∑ N − 1 a n x [ n ] ) 2 ⎦ ⎥ ⎤ = E [ ( θ − n = 0 ∑ N − 1 a n x [ n ] ) ( θ − m = 0 ∑ N − 1 a m x [ m ] ) ] = E ( θ 2 ) − n = 0 ∑ N − 1 a n E ( x [ n ] θ ) − m = 0 ∑ N − 1 a m E ( θ x [ m ] ) + n = 0 ∑ N − 1 m = 0 ∑ N − 1 a n a m E ( x [ n ] x [ m ] ) = C θ θ − a T C x θ = C θ θ − C x θ T C x x − 1 C x θ = C θ θ − C x θ C x x − 1 C x θ
Geometrical Interpretations - Examples
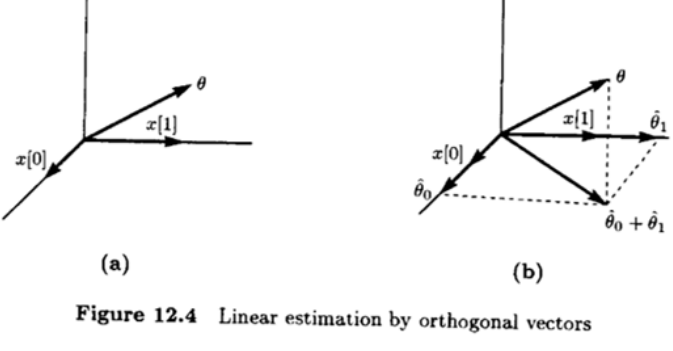
Estimation by orthogonal vectors, where x [ 0 ] x[0] x [ 0 ] x [ 1 ] x[1] x [ 1 ] θ ^ = θ ^ 0 + θ ^ 1 = ( θ , x [ 0 ] ∥ x [ 0 ] ∥ ) x [ 0 ] ∥ x [ 0 ] ∥ + ( θ , x [ 1 ] ∥ x [ 1 ] ∥ ) x [ 1 ] ∥ x [ 1 ] ∥ = ( θ , x [ 0 ] ) ( x [ 0 ] , x [ 0 ] ) x [ 0 ] + ( θ , x [ 1 ] ) ( x [ 1 ] , x [ 1 ] ) x [ 1 ] = E ( θ x [ 0 ] ) E ( x 2 [ 0 ] ) x [ 0 ] + E ( θ x [ 1 ] ) E ( x 2 [ 1 ] ) x [ 1 ] = [ E ( θ x [ 0 ] ) E ( θ x [ 1 ] ) ] [ E ( x 2 [ 0 ] ) 0 0 E ( x 2 [ 1 ] ) ] − 1 [ x [ 0 ] x [ 1 ] ] = C θ x C x x − 1 x \hat{\theta} = \hat{\theta}_0 + \hat{\theta}_1\\[0.2cm] = \left( \theta, \frac{x[0]}{\|x[0]\|} \right) \frac{x[0]}{\|x[0]\|} + \left( \theta, \frac{x[1]}{\|x[1]\|} \right) \frac{x[1]}{\|x[1]\|}\\[0.2cm] = \frac{(\theta, x[0])}{(x[0], x[0])} x[0] + \frac{(\theta, x[1])}{(x[1], x[1])} x[1] \\[0.2cm] = \frac{\mathbb{E}(\theta x[0])}{\mathbb{E}(x^2[0])} x[0] + \frac{\mathbb{E}(\theta x[1])}{\mathbb{E}(x^2[1])} x[1]\\[0.2cm] = \begin{bmatrix} \mathbb{E}(\theta x[0]) & \mathbb{E}(\theta x[1]) \end{bmatrix} \begin{bmatrix} \mathbb{E}(x^2[0]) & 0 \\ 0 & \mathbb{E}(x^2[1]) \end{bmatrix}^{-1} \begin{bmatrix} x[0] \\ x[1] \end{bmatrix}= \mathbf{C}_{\theta x} \mathbf{C}_{xx}^{-1} \mathbf{x} θ ^ = θ ^ 0 + θ ^ 1 = ( θ , ∥ x [ 0 ] ∥ x [ 0 ] ) ∥ x [ 0 ] ∥ x [ 0 ] + ( θ , ∥ x [ 1 ] ∥ x [ 1 ] ) ∥ x [ 1 ] ∥ x [ 1 ] = ( x [ 0 ] , x [ 0 ] ) ( θ , x [ 0 ] ) x [ 0 ] + ( x [ 1 ] , x [ 1 ] ) ( θ , x [ 1 ] ) x [ 1 ] = E ( x 2 [ 0 ] ) E ( θ x [ 0 ] ) x [ 0 ] + E ( x 2 [ 1 ] ) E ( θ x [ 1 ] ) x [ 1 ] = [ E ( θ x [ 0 ] ) E ( θ x [ 1 ] ) ] [ E ( x 2 [ 0 ] ) 0 0 E ( x 2 [ 1 ] ) ] − 1 [ x [ 0 ] x [ 1 ] ] = C θ x C x x − 1 x
Sequential LMMSE Estimation
Increasing number of data samples for estimating fixed number of parameters
Data model :x [ n − 1 ] = H [ n − 1 ] θ + w [ n − 1 ] → x [ n ] = [ x [ n − 1 ] x [ n ] ] = [ H [ n − 1 ] h T [ n ] ] θ + [ w [ n − 1 ] w [ n ] ] = H [ n ] θ + w [ n ] \mathbf{x}[n-1] = \mathbf{H}[n-1]\boldsymbol{\theta} + \mathbf{w}[n-1]\\[0.2cm] \rightarrow \mathbf{x}[n] = \begin{bmatrix} \mathbf{x}[n-1] \\ x[n] \end{bmatrix} = \begin{bmatrix} \mathbf{H}[n-1] \\ \mathbf{h}^T[n] \end{bmatrix} \boldsymbol{\theta} + \begin{bmatrix} \mathbf{w}[n-1] \\ w[n] \end{bmatrix} = \mathbf{H}[n] \boldsymbol{\theta} + \mathbf{w}[n] x [ n − 1 ] = H [ n − 1 ] θ + w [ n − 1 ] → x [ n ] = [ x [ n − 1 ] x [ n ] ] = [ H [ n − 1 ] h T [ n ] ] θ + [ w [ n − 1 ] w [ n ] ] = H [ n ] θ + w [ n ]
Goal : Given an estimate θ ^ [ n − 1 ] \hat\theta[n-1] θ ^ [ n − 1 ] x [ n − 1 ] \text{x}[n-1] x [ n − 1 ] x [ n ] \text{x}[n] x [ n ] θ ^ [ n ] \hat\theta[n] θ ^ [ n ]
Ex) DC level in WGN, with μ A = 0 \mu_A=0 μ A = 0
A ^ [ N − 1 ] \hat A[N-1] A ^ [ N − 1 ] A A A x [ 0 ] , x [ 1 ] , … , x [ N − 1 ] x[0], x[1],\dots,x[N-1] x [ 0 ] , x [ 1 ] , … , x [ N − 1 ] A ^ [ N − 1 ] = σ A 2 σ A 2 + σ 2 / N x ˉ Bmse ( A ^ [ N − 1 ] ) = σ 2 N ( σ A 2 σ A 2 + σ 2 / N ) = σ 2 σ A 2 N σ A 2 + σ 2 \hat{A}[N-1] = \frac{\sigma_A^2}{\sigma_A^2 + \sigma^2 / N} \bar{x}\\[0.2cm]\text{Bmse}(\hat{A}[N-1]) = \frac{\sigma^2}{N} \left( \frac{\sigma_A^2}{\sigma_A^2 + \sigma^2 / N} \right) = \frac{\sigma^2 \sigma_A^2}{N \sigma_A^2 + \sigma^2} A ^ [ N − 1 ] = σ A 2 + σ 2 / N σ A 2 x ˉ Bmse ( A ^ [ N − 1 ] ) = N σ 2 ( σ A 2 + σ 2 / N σ A 2 ) = N σ A 2 + σ 2 σ 2 σ A 2 When x [ N ] x[N] x [ N ] A ^ [ N ] = σ A 2 σ A 2 + σ 2 N + 1 1 N + 1 ∑ n = 0 N x [ n ] = N σ A 2 ( N + 1 ) σ A 2 + σ 2 1 N ( ∑ n = 0 N − 1 x [ n ] + x [ N ] ) = N σ A 2 ( N + 1 ) σ A 2 + σ 2 σ A 2 + σ 2 N σ A 2 A ^ [ N − 1 ] + σ A 2 ( N + 1 ) σ A 2 + σ 2 x [ N ] = N σ A 2 + σ 2 ( N + 1 ) σ A 2 + σ 2 A ^ [ N − 1 ] + σ A 2 ( N + 1 ) σ A 2 + σ 2 x [ N ] \hat{A}[N] = \frac{\sigma_A^2}{\sigma_A^2 + \frac{\sigma^2}{N+1}} \frac{1}{N+1} \sum_{n=0}^N x[n] = \frac{N \sigma_A^2}{(N+1) \sigma_A^2 + \sigma^2} \frac{1}{N} \left( \sum_{n=0}^{N-1} x[n] + x[N] \right)\\[0.2cm] = \frac{N \sigma_A^2}{(N+1) \sigma_A^2 + \sigma^2} \frac{\sigma^2_A+\frac{\sigma^2}{N}}{\sigma^2_A}\hat{A}[N-1] + \frac{\sigma_A^2}{(N+1) \sigma_A^2 + \sigma^2} x[N]\\[0.2cm] = \frac{N \sigma_A^2 + \sigma^2}{(N+1) \sigma_A^2 + \sigma^2} \hat{A}[N-1] + \frac{\sigma_A^2}{(N+1) \sigma_A^2 + \sigma^2} x[N] A ^ [ N ] = σ A 2 + N + 1 σ 2 σ A 2 N + 1 1 n = 0 ∑ N x [ n ] = ( N + 1 ) σ A 2 + σ 2 N σ A 2 N 1 ( n = 0 ∑ N − 1 x [ n ] + x [ N ] ) = ( N + 1 ) σ A 2 + σ 2 N σ A 2 σ A 2 σ A 2 + N σ 2 A ^ [ N − 1 ] + ( N + 1 ) σ A 2 + σ 2 σ A 2 x [ N ] = ( N + 1 ) σ A 2 + σ 2 N σ A 2 + σ 2 A ^ [ N − 1 ] + ( N + 1 ) σ A 2 + σ 2 σ A 2 x [ N ]
A ^ [ N ] = A ^ [ N − 1 ] + ( N σ A 2 + σ 2 ( N + 1 ) σ A 2 + σ 2 − 1 ) A ^ [ N − 1 ] + σ A 2 ( N + 1 ) σ A 2 + σ 2 x [ N ] = A ^ [ N − 1 ] + σ A 2 ( N + 1 ) σ A 2 + σ 2 ( x [ N ] − A ^ [ N − 1 ] ) \hat{A}[N] = \hat{A}[N-1] + \left( \frac{N \sigma_A^2 + \sigma^2}{(N+1) \sigma_A^2 + \sigma^2} - 1 \right) \hat{A}[N-1] + \frac{\sigma_A^2}{(N+1) \sigma_A^2 + \sigma^2} x[N]\\[0.2cm] = \hat{A}[N-1] + \frac{\sigma_A^2}{(N+1) \sigma_A^2 + \sigma^2} \left( x[N] - \hat{A}[N-1] \right) A ^ [ N ] = A ^ [ N − 1 ] + ( ( N + 1 ) σ A 2 + σ 2 N σ A 2 + σ 2 − 1 ) A ^ [ N − 1 ] + ( N + 1 ) σ A 2 + σ 2 σ A 2 x [ N ] = A ^ [ N − 1 ] + ( N + 1 ) σ A 2 + σ 2 σ A 2 ( x [ N ] − A ^ [ N − 1 ] ) (correct the old estimate A ^ [ N − 1 ] \hat A[N-1] A ^ [ N − 1 ]
With gain or scaling factor K [ N ] K[N] K [ N ] A ^ [ N ] = A ^ [ N − 1 ] + K [ N ] ( x [ N ] − A ^ [ N − 1 ] ) K [ N ] = σ A 2 ( N + 1 ) σ A 2 + σ 2 = 1 σ 2 Bmse ( A ^ [ N − 1 ] ) + 1 = Bmse ( A ^ [ N − 1 ] ) Bmse ( A ^ [ N − 1 ] ) + σ 2 (decreases with N ) Bmse ( A ^ [ N ] ) = σ 2 σ A 2 ( N + 1 ) σ A 2 + σ 2 = N σ A 2 + σ 2 ( N + 1 ) σ A 2 + σ 2 Bmse ( A ^ [ N − 1 ] ) = ( 1 − K [ N ] ) Bmse ( A ^ [ N − 1 ] ) \hat{A}[N] = \hat{A}[N-1] + K[N] \left( x[N] - \hat{A}[N-1] \right)\\[0.2cm] K[N] = \frac{\sigma_A^2}{(N+1) \sigma_A^2 + \sigma^2} = \frac{1}{\frac{\sigma^2}{\text{Bmse}(\hat{A}[N-1])} + 1} =\frac{\text{Bmse}(\hat A[N-1])}{\text{Bmse}(\hat A[N-1])+\sigma^2} \quad \text{(decreases with } N\text{)}\\[0.2cm] \text{Bmse}(\hat{A}[N]) = \frac{\sigma^2 \sigma_A^2}{(N+1) \sigma_A^2 + \sigma^2} = \frac{N \sigma_A^2 + \sigma^2}{(N+1) \sigma_A^2 + \sigma^2} \text{Bmse}(\hat{A}[N-1])\\[0.2cm] = (1 - K[N]) \text{Bmse}(\hat{A}[N-1]) A ^ [ N ] = A ^ [ N − 1 ] + K [ N ] ( x [ N ] − A ^ [ N − 1 ] ) K [ N ] = ( N + 1 ) σ A 2 + σ 2 σ A 2 = Bmse ( A ^ [ N − 1 ] ) σ 2 + 1 1 = Bmse ( A ^ [ N − 1 ] ) + σ 2 Bmse ( A ^ [ N − 1 ] ) (decreases with N ) Bmse ( A ^ [ N ] ) = ( N + 1 ) σ A 2 + σ 2 σ 2 σ A 2 = ( N + 1 ) σ A 2 + σ 2 N σ A 2 + σ 2 Bmse ( A ^ [ N − 1 ] ) = ( 1 − K [ N ] ) Bmse ( A ^ [ N − 1 ] )
S-LMMSE Estimation : Vector Space Approach
Vector space approach
Given two observations x [ 0 ] , x [ 1 ] x[0],x[1] x [ 0 ] , x [ 1 ]
We want to find A ^ [ 1 ] , A ^ [ 1 ] = A ^ [ 0 ] + Δ A ^ [ 1 ] , Δ A ^ [ 1 ] \hat{A}[1], \hat{A}[1] = \hat{A}[0] + \Delta \hat{A}[1], \Delta \hat{A}[1] A ^ [ 1 ] , A ^ [ 1 ] = A ^ [ 0 ] + Δ A ^ [ 1 ] , Δ A ^ [ 1 ] A ^ [ 0 ] \hat A[0] A ^ [ 0 ]
Let x ^ [ 1 ∣ 0 ] \hat x[1|0] x ^ [ 1 ∣ 0 ] x [ 1 ] x[1] x [ 1 ] x [ 0 ] x[0] x [ 0 ] x ~ [ 1 ] = x [ 1 ] − x ^ [ 1 ∣ 0 ] ⊥ x [ 0 ] \tilde{x}[1] = x[1] - \hat{x}[1|0] \perp x[0] x ~ [ 1 ] = x [ 1 ] − x ^ [ 1 ∣ 0 ] ⊥ x [ 0 ]
Now we can think it as estimation based on orthogonal vectors x [ 0 ] x[0] x [ 0 ] x ~ [ 1 ] \tilde x[1] x ~ [ 1 ] → Δ A ^ [ 1 ] \rightarrow\;\Delta\hat A[1] → Δ A ^ [ 1 ] A A A x ~ [ 1 ] \tilde x[1] x ~ [ 1 ]
θ ^ = C θ x C x x − 1 x \hat \theta=C_{\theta x}C^{-1}_{xx}\text{x} θ ^ = C θ x C x x − 1 x x ^ [ 1 ∣ 0 ] = E ( x [ 0 ] x [ 1 ] ) E ( x 2 [ 0 ] ) x [ 0 ] = E ( ( A + w [ 0 ] ) ( A + w [ 1 ] ) ) E ( ( A + w [ 0 ] ) 2 ) x [ 0 ] = σ A 2 σ A 2 + σ 2 x [ 0 ] \hat{x}[1|0] = \frac{\mathbb{E}(x[0] x[1])}{\mathbb{E}(x^2[0])} x[0] = \frac{\mathbb{E}((A + w[0])(A + w[1]))}{\mathbb{E}((A + w[0])^2)} x[0] = \frac{\sigma_A^2}{\sigma_A^2 + \sigma^2} x[0] x ^ [ 1 ∣ 0 ] = E ( x 2 [ 0 ] ) E ( x [ 0 ] x [ 1 ] ) x [ 0 ] = E ( ( A + w [ 0 ] ) 2 ) E ( ( A + w [ 0 ] ) ( A + w [ 1 ] ) ) x [ 0 ] = σ A 2 + σ 2 σ A 2 x [ 0 ]
x ~ [ 1 ] = x [ 1 ] ⊥ x ^ [ 1 ∣ 0 ] \tilde x[1]=x[1]\perp\hat x[1|0] x ~ [ 1 ] = x [ 1 ] ⊥ x ^ [ 1 ∣ 0 ] innovationThe projection of A A A Δ A ^ [ 1 ] = ( A , x ~ [ 1 ] ∥ x ~ [ 1 ] ∥ ) x ~ [ 1 ] ∥ x ~ [ 1 ] ∥ = E ( A x ~ [ 1 ] ) E ( x ~ 2 [ 1 ] ) x ~ [ 1 ] , K [ 1 ] = E ( A x ~ [ 1 ] ) E ( x ~ 2 [ 1 ] ) A ^ [ 1 ] = A ^ [ 0 ] + K [ 1 ] ( x [ 1 ] − x ^ [ 1 ∣ 0 ] ) = A ^ [ 0 ] + K [ 1 ] ( x [ 1 ] − A ^ [ 0 ] ) ( x ^ [ 1 ∣ 0 ] = A ^ [ 0 ] + w ^ [ 1 ∣ 0 ] = A ^ [ 0 ] ) → x ~ [ 1 ] = x [ 1 ] − x ^ [ 1 ∣ 0 ] = x [ 1 ] − A ^ [ 0 ] = x [ 1 ] − σ A 2 σ A 2 + σ 2 x [ 0 ] K [ 1 ] = E [ A ( x [ 1 ] − σ A 2 σ A 2 + σ 2 x [ 0 ] ) ] E [ ( x [ 1 ] − σ A 2 σ A 2 + σ 2 x [ 0 ] ) 2 ] = σ A 2 σ A 2 σ A 2 + σ 2 σ A 2 + σ 2 − 2 σ A 4 σ A 2 + σ 2 + ( σ A 2 σ A 2 + σ 2 ) 2 ( σ A 2 + σ 2 ) K [ 1 ] = σ A 2 σ A 2 2 σ A 2 + σ 2 \Delta \hat{A}[1] = \left( A, \frac{\tilde{x}[1]}{\|\tilde{x}[1]\|} \right) \frac{\tilde{x}[1]}{\|\tilde{x}[1]\|} = \frac{\mathbb{E}(A \tilde{x}[1])}{\mathbb{E}(\tilde{x}^2[1])} \tilde{x}[1],\;K[1]=\frac{E(A\tilde x[1])}{E(\tilde x^2[1])}\\[0.2cm] \hat{A}[1] = \hat{A}[0] + K[1] \left( x[1] - \hat{x}[1|0] \right)=\hat A[0]+K[1](x[1]-\hat A[0])\\[0.2cm] (\hat x[1|0]=\hat A[0]+\hat w[1|0]=\hat A[0])\\[0.2cm] \rightarrow \tilde x[1]=x[1] - \hat{x}[1|0] = x[1] - \hat{A}[0] = x[1] - \frac{\sigma_A^2}{\sigma_A^2 + \sigma^2} x[0]\\[0.2cm] K[1] = \frac{\mathbb{E} \left[ A \left( x[1] - \frac{\sigma_A^2}{\sigma_A^2 + \sigma^2} x[0] \right) \right]} {\mathbb{E} \left[ \left( x[1] - \frac{\sigma_A^2}{\sigma_A^2 + \sigma^2} x[0] \right)^2 \right]} = \frac{\frac{\sigma_A^2 \sigma_A^2}{\sigma_A^2 + \sigma^2}}{\sigma_A^2 + \sigma^2 - \frac{2\sigma_A^4}{\sigma_A^2 + \sigma^2} + \left( \frac{\sigma_A^2}{\sigma_A^2 + \sigma^2} \right)^2 (\sigma_A^2 + \sigma^2)}\\[0.2cm] K[1] = \frac{\sigma_A^2 \sigma_A^2}{2\sigma_A^2 + \sigma^2} Δ A ^ [ 1 ] = ( A , ∥ x ~ [ 1 ] ∥ x ~ [ 1 ] ) ∥ x ~ [ 1 ] ∥ x ~ [ 1 ] = E ( x ~ 2 [ 1 ] ) E ( A x ~ [ 1 ] ) x ~ [ 1 ] , K [ 1 ] = E ( x ~ 2 [ 1 ] ) E ( A x ~ [ 1 ] ) A ^ [ 1 ] = A ^ [ 0 ] + K [ 1 ] ( x [ 1 ] − x ^ [ 1 ∣ 0 ] ) = A ^ [ 0 ] + K [ 1 ] ( x [ 1 ] − A ^ [ 0 ] ) ( x ^ [ 1 ∣ 0 ] = A ^ [ 0 ] + w ^ [ 1 ∣ 0 ] = A ^ [ 0 ] ) → x ~ [ 1 ] = x [ 1 ] − x ^ [ 1 ∣ 0 ] = x [ 1 ] − A ^ [ 0 ] = x [ 1 ] − σ A 2 + σ 2 σ A 2 x [ 0 ] K [ 1 ] = E [ ( x [ 1 ] − σ A 2 + σ 2 σ A 2 x [ 0 ] ) 2 ] E [ A ( x [ 1 ] − σ A 2 + σ 2 σ A 2 x [ 0 ] ) ] = σ A 2 + σ 2 − σ A 2 + σ 2 2 σ A 4 + ( σ A 2 + σ 2 σ A 2 ) 2 ( σ A 2 + σ 2 ) σ A 2 + σ 2 σ A 2 σ A 2 K [ 1 ] = 2 σ A 2 + σ 2 σ A 2 σ A 2
Sequence of innovations x [ 0 ] , x [ 1 ] − x ^ [ 1 ∣ 0 ] , x [ 2 ] − x ^ [ 2 ∣ 0 , 1 ] , ⋯ x[0],x[1]-\hat x[1|0],x[2]-\hat x[2|0,1],\cdots x [ 0 ] , x [ 1 ] − x ^ [ 1 ∣ 0 ] , x [ 2 ] − x ^ [ 2 ∣ 0 , 1 ] , ⋯ A ^ [ N ] = ∑ n = 0 N − 1 K [ n ] ( x [ n ] − x ^ [ n ∣ 0 , 1 , … , n − 1 ] ) K [ n ] = E ( A ( x [ n ] − x ^ [ n ∣ 0 , 1 , … , n − 1 ] ) ) E ( ( x [ n ] − x ^ [ n ∣ 0 , 1 , … , n − 1 ] ) 2 ) \hat{A}[N] = \sum_{n=0}^{N-1} K[n] \left( x[n] - \hat{x}[n|0, 1, \dots, n-1] \right)\\[0.2cm] K[n] = \frac{\mathbb{E}\left( A \left( x[n] - \hat{x}[n|0, 1, \dots, n-1] \right) \right)} {\mathbb{E}\left( \left( x[n] - \hat{x}[n|0, 1, \dots, n-1] \right)^2 \right)} A ^ [ N ] = n = 0 ∑ N − 1 K [ n ] ( x [ n ] − x ^ [ n ∣ 0 , 1 , … , n − 1 ] ) K [ n ] = E ( ( x [ n ] − x ^ [ n ∣ 0 , 1 , … , n − 1 ] ) 2 ) E ( A ( x [ n ] − x ^ [ n ∣ 0 , 1 , … , n − 1 ] ) )
In sequential form,A ^ [ N ] = A ^ [ N − 1 ] + K [ N ] ( x [ N ] − x ^ [ N ∣ 0 , 1 , ⋯ , N − 1 ] ) \hat A[N]=\hat A[N-1]+K[N](x[N]-\hat x[N|0,1,\cdots,N-1]) A ^ [ N ] = A ^ [ N − 1 ] + K [ N ] ( x [ N ] − x ^ [ N ∣ 0 , 1 , ⋯ , N − 1 ] )
Since x [ n ] = A + w [ n ] x[n]=A+w[n] x [ n ] = A + w [ n ] A A A w [ n ] w[n] w [ n ] x ^ [ N ∣ 0 , 1 , … , N − 1 ] = A ^ [ N ∣ 0 , 1 , … , N − 1 ] + w [ N ∣ 0 , 1 , … , N − 1 ] = A ^ [ N − 1 ] K [ N ] = E ( A ( x [ N ] − A ^ [ N − 1 ] ) ) E ( ( x [ N ] − A ^ [ N − 1 ] ) 2 ) \hat{x}[N | 0, 1, \dots, N-1] = \hat{A}[N | 0, 1, \dots, N-1] + w[N | 0, 1, \dots, N-1] = \hat{A}[N-1]\\[0.2cm] K[N] = \frac{\mathbb{E}\left( A \left( x[N] - \hat{A}[N-1] \right) \right)} {\mathbb{E}\left( \left( x[N] - \hat{A}[N-1] \right)^2 \right)} x ^ [ N ∣ 0 , 1 , … , N − 1 ] = A ^ [ N ∣ 0 , 1 , … , N − 1 ] + w [ N ∣ 0 , 1 , … , N − 1 ] = A ^ [ N − 1 ] K [ N ] = E ( ( x [ N ] − A ^ [ N − 1 ] ) 2 ) E ( A ( x [ N ] − A ^ [ N − 1 ] ) )
E ( A ( x [ N ] − A ^ [ N − 1 ] ) ) = E ( ( A − A ^ [ N − 1 ] ) ( x [ N ] − A ^ [ N − 1 ] ) ) = Bmse ( A ^ [ N − 1 ] ) E ( ( x [ N ] − A ^ [ N − 1 ] ) 2 ) = E ( ( w [ N ] + A − A ^ [ N − 1 ] ) 2 ) = σ 2 + Bmse ( A ^ [ N − 1 ] ) → K [ N ] = Bmse ( A ^ [ N − 1 ] ) σ 2 + Bmse ( A ^ [ N − 1 ] ) Bmse ( A ^ [ N ] ) = E ( ( A − A ^ [ N ] ) 2 ) = E ( ( A − A ^ [ N − 1 ] − K [ N ] ( x [ N ] − A ^ [ N − 1 ] ) ) 2 ) = E ( ( A − A ^ [ N − 1 ] ) 2 ) − 2 K [ N ] E ( ( A − A ^ [ N − 1 ] ) ( x [ N ] − A ^ [ N − 1 ] ) ) + K [ N ] 2 E ( ( x [ N ] − A ^ [ N − 1 ] ) 2 ) = Bmse ( A ^ [ N − 1 ] ) − 2 K [ N ] Bmse ( A ^ [ N − 1 ] ) + K [ N ] 2 ( σ 2 + Bmse ( A ^ [ N − 1 ] ) ) = Bmse ( A ^ [ N − 1 ] ) ( 1 − 2 K [ N ] + K [ N ] 2 ) + K [ N ] 2 σ 2 = ( 1 − K [ N ] ) Bmse ( A ^ [ N − 1 ] ) \mathbb{E}\left( A (x[N] - \hat{A}[N-1]) \right) = \mathbb{E}\left( (A - \hat{A}[N-1])(x[N] - \hat{A}[N-1]) \right) = \text{Bmse}(\hat{A}[N-1])\\[0.2cm] \mathbb{E}\left( (x[N] - \hat{A}[N-1])^2 \right) = \mathbb{E}\left( (w[N] + A - \hat{A}[N-1])^2 \right) = \sigma^2 + \text{Bmse}(\hat{A}[N-1])\\[0.2cm] \rightarrow K[N] = \frac{\text{Bmse}(\hat{A}[N-1])}{\sigma^2 + \text{Bmse}(\hat{A}[N-1])}\\[0.2cm] \text{Bmse}(\hat{A}[N]) = \mathbb{E}\left( (A - \hat{A}[N])^2 \right) = \mathbb{E}\left( (A - \hat{A}[N-1] - K[N](x[N] - \hat{A}[N-1]))^2 \right)\\[0.2cm] = \mathbb{E}\left( (A - \hat{A}[N-1])^2 \right) - 2K[N] \mathbb{E}\left( (A - \hat{A}[N-1])(x[N] - \hat{A}[N-1]) \right)\\ + K[N]^2 \mathbb{E}\left( (x[N] - \hat{A}[N-1])^2 \right)\\[0.2cm] = \text{Bmse}(\hat{A}[N-1]) - 2K[N] \text{Bmse}(\hat{A}[N-1]) + K[N]^2 (\sigma^2 + \text{Bmse}(\hat{A}[N-1]))\\[0.2cm] = \text{Bmse}(\hat{A}[N-1]) \left( 1 - 2K[N] + K[N]^2 \right) + K[N]^2 \sigma^2\\[0.2cm] = (1 - K[N]) \text{Bmse}(\hat{A}[N-1]) E ( A ( x [ N ] − A ^ [ N − 1 ] ) ) = E ( ( A − A ^ [ N − 1 ] ) ( x [ N ] − A ^ [ N − 1 ] ) ) = Bmse ( A ^ [ N − 1 ] ) E ( ( x [ N ] − A ^ [ N − 1 ] ) 2 ) = E ( ( w [ N ] + A − A ^ [ N − 1 ] ) 2 ) = σ 2 + Bmse ( A ^ [ N − 1 ] ) → K [ N ] = σ 2 + Bmse ( A ^ [ N − 1 ] ) Bmse ( A ^ [ N − 1 ] ) Bmse ( A ^ [ N ] ) = E ( ( A − A ^ [ N ] ) 2 ) = E ( ( A − A ^ [ N − 1 ] − K [ N ] ( x [ N ] − A ^ [ N − 1 ] ) ) 2 ) = E ( ( A − A ^ [ N − 1 ] ) 2 ) − 2 K [ N ] E ( ( A − A ^ [ N − 1 ] ) ( x [ N ] − A ^ [ N − 1 ] ) ) + K [ N ] 2 E ( ( x [ N ] − A ^ [ N − 1 ] ) 2 ) = Bmse ( A ^ [ N − 1 ] ) − 2 K [ N ] Bmse ( A ^ [ N − 1 ] ) + K [ N ] 2 ( σ 2 + Bmse ( A ^ [ N − 1 ] ) ) = Bmse ( A ^ [ N − 1 ] ) ( 1 − 2 K [ N ] + K [ N ] 2 ) + K [ N ] 2 σ 2 = ( 1 − K [ N ] ) Bmse ( A ^ [ N − 1 ] ) Winer Filtering
Signal Model:x [ n ] = s [ n ] + w [ n ] x[n] = s[n]+w[n] x [ n ] = s [ n ] + w [ n ]
Problem Statement : Process x [ n ] x[n] x [ n ] de-noised version of the signal that has minimum MSE relative to the desired signal→ \rightarrow →
Assuming that the data x [ 0 ] , x [ 1 ] , ⋯ , x [ N − 1 ] x[0],x[1],\cdots,x[N-1] x [ 0 ] , x [ 1 ] , ⋯ , x [ N − 1 ] N × N N\times N N × N C x x C_{xx} C x x C x x = [ r x x [ 0 ] r x x [ 1 ] ⋯ r x x [ N − 1 ] r x x [ 1 ] r x x [ 0 ] ⋯ r x x [ N − 2 ] ⋮ ⋮ ⋱ ⋮ r x x [ N − 1 ] r x x [ N − 2 ] ⋯ r x x [ 0 ] ] = R x x \mathbf{C}_{xx} = \begin{bmatrix} r_{xx}[0] & r_{xx}[1] & \cdots & r_{xx}[N-1] \\ r_{xx}[1] & r_{xx}[0] & \cdots & r_{xx}[N-2] \\ \vdots & \vdots & \ddots & \vdots \\ r_{xx}[N-1] & r_{xx}[N-2] & \cdots & r_{xx}[0] \end{bmatrix} = \mathbf{R}_{xx} C x x = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ r x x [ 0 ] r x x [ 1 ] ⋮ r x x [ N − 1 ] r x x [ 1 ] r x x [ 0 ] ⋮ r x x [ N − 2 ] ⋯ ⋯ ⋱ ⋯ r x x [ N − 1 ] r x x [ N − 2 ] ⋮ r x x [ 0 ] ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = R x x r x x [ k ] r_{xx}[k] r x x [ k ] x [ n ] x[n] x [ n ] R x x R_{xx} R x x θ \theta θ
Filtering : estimate θ = s [ n ] \theta = s[n] θ = s [ n ] x [ m ] = s [ m ] + w [ m ] , m = 0 , 1 , ⋯ , n x[m]=s[m]+w[m],\;m=0,1,\cdots,n x [ m ] = s [ m ] + w [ m ] , m = 0 , 1 , ⋯ , n Smoothing : estimate θ = s [ n ] , n = 0 , 1 , ⋯ , N − 1 \theta = s[n],\;n=0,1,\cdots,N-1 θ = s [ n ] , n = 0 , 1 , ⋯ , N − 1 x [ 0 ] , x [ 1 ] , ⋯ , x [ N − 1 ] x[0],x[1],\cdots,x[N-1] x [ 0 ] , x [ 1 ] , ⋯ , x [ N − 1 ] x [ n ] = s [ n ] + w [ n ] x[n]=s[n]+w[n] x [ n ] = s [ n ] + w [ n ] Prediction : estimate θ = x [ N − 1 + l ] ( l > 0 ) \theta = x[N-1+l]\;(l>0) θ = x [ N − 1 + l ] ( l > 0 ) x [ 0 ] , x [ 1 ] , ⋯ , x [ N − 1 ] x[0],x[1],\cdots,x[N-1] x [ 0 ] , x [ 1 ] , ⋯ , x [ N − 1 ]
General LMMSE estimationθ ^ = C θ x C x x − 1 x M θ ^ = C θ θ − C θ x C x x − 1 C x θ \hat\theta=C_{\theta x}C^{-1}_{xx}\text{x}\\[0.2cm] M_{\hat \theta}=C_{\theta\theta}-C_{\theta x}C^{-1}_{xx}C_{x\theta} θ ^ = C θ x C x x − 1 x M θ ^ = C θ θ − C θ x C x x − 1 C x θ
Filtering problem : assuming signal and noise are uncorrelated,C x x = R s s + R w w C θ x = E ( s [ n ] [ x [ 0 ] x [ 1 ] … x [ n ] ] ) = E ( s [ n ] [ s [ 0 ] s [ 1 ] … s [ n ] ] ) = [ r s s [ n ] r s s [ n − 1 ] … r s s [ 0 ] ] : = r s s T → s ^ [ n ] = r s s T ( R s s + R w w ) − 1 x , a = ( R s s + R w w ) − 1 r s s \mathbf{C}_{xx} = \mathbf{R}_{ss} + \mathbf{R}_{ww}\\[0.2cm] \mathbf{C}_{\theta x} = \mathbb{E}(s[n] [x[0] \, x[1] \, \dots \, x[n]]) = \mathbb{E}(s[n] [s[0] \, s[1] \, \dots \, s[n]])\\ = [r_{ss}[n] \, r_{ss}[n-1] \, \dots \, r_{ss}[0]] := \mathbf{r}_{ss}^T\\[0.2cm] \rightarrow \hat{s}[n] = \mathbf{r}_{ss}^T (\mathbf{R}_{ss} + \mathbf{R}_{ww})^{-1} \mathbf{x}, \quad \mathbf{a} = (\mathbf{R}_{ss} + \mathbf{R}_{ww})^{-1} \mathbf{r}_{ss} C x x = R s s + R w w C θ x = E ( s [ n ] [ x [ 0 ] x [ 1 ] … x [ n ] ] ) = E ( s [ n ] [ s [ 0 ] s [ 1 ] … s [ n ] ] ) = [ r s s [ n ] r s s [ n − 1 ] … r s s [ 0 ] ] : = r s s T → s ^ [ n ] = r s s T ( R s s + R w w ) − 1 x , a = ( R s s + R w w ) − 1 r s s
If we think it as a filter with impulse response h [ k ] , h [ k ] = a n − k h[k],\;h[k]=a_{n-k} h [ k ] , h [ k ] = a n − k s ^ [ n ] = ∑ k = 0 n a k x [ k ] = ∑ k = 0 n h [ n − k ] x [ k ] = ∑ k = 0 n h [ k ] x [ n − k ] ( R s s + R w w ) a = r s s ⟹ ( R s s + R w w ) h = r s s [ r x x [ 0 ] r x x [ 1 ] ⋯ r x x [ n ] r x x [ 1 ] r x x [ 0 ] ⋯ r x x [ n − 1 ] ⋮ ⋮ ⋱ ⋮ r x x [ n ] r x x [ n − 1 ] ⋯ r x x [ 0 ] ] [ h [ 0 ] h [ 1 ] ⋮ h [ n ] ] = [ r s s [ 0 ] r s s [ 1 ] ⋮ r s s [ n ] ] \hat{s}[n] = \sum_{k=0}^n a_k x[k] = \sum_{k=0}^n h[n-k] x[k] = \sum_{k=0}^n h[k] x[n-k]\\[0.2cm] (\mathbf{R}_{ss} + \mathbf{R}_{ww}) \mathbf{a} = \mathbf{r}_{ss} \quad \implies \quad (\mathbf{R}_{ss} + \mathbf{R}_{ww}) \mathbf{h} = \mathbf{r}_{ss}\\[0.2cm] \begin{bmatrix} r_{xx}[0] & r_{xx}[1] & \cdots & r_{xx}[n] \\ r_{xx}[1] & r_{xx}[0] & \cdots & r_{xx}[n-1] \\ \vdots & \vdots & \ddots & \vdots \\ r_{xx}[n] & r_{xx}[n-1] & \cdots & r_{xx}[0] \end{bmatrix} \begin{bmatrix} h[0] \\ h[1] \\ \vdots \\ h[n] \end{bmatrix} = \begin{bmatrix} r_{ss}[0] \\ r_{ss}[1] \\ \vdots \\ r_{ss}[n] \end{bmatrix} s ^ [ n ] = k = 0 ∑ n a k x [ k ] = k = 0 ∑ n h [ n − k ] x [ k ] = k = 0 ∑ n h [ k ] x [ n − k ] ( R s s + R w w ) a = r s s ⟹ ( R s s + R w w ) h = r s s ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ r x x [ 0 ] r x x [ 1 ] ⋮ r x x [ n ] r x x [ 1 ] r x x [ 0 ] ⋮ r x x [ n − 1 ] ⋯ ⋯ ⋱ ⋯ r x x [ n ] r x x [ n − 1 ] ⋮ r x x [ 0 ] ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ h [ 0 ] h [ 1 ] ⋮ h [ n ] ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ r s s [ 0 ] r s s [ 1 ] ⋮ r s s [ n ] ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ → ∑ k = 0 n h [ k ] r x x [ l − k ] = r s s [ l ] , l = 0 , 1 , … , n As n → ∞ , ∑ k = 0 ∞ h [ k ] r x x [ l − k ] = r s s [ l ] , l = 0 , 1 , … h [ n ] ∗ r x x [ n ] = r s s [ n ] ⟹ H ( f ) = P s s ( f ) P x x ( f ) = P s s ( f ) P s s ( f ) + P w w ( f ) \rightarrow \sum_{k=0}^n h[k] r_{xx}[l-k] = r_{ss}[l], \quad l = 0, 1, \dots, n\\[0.2cm] \text{As } n \to \infty, \quad \sum_{k=0}^\infty h[k] r_{xx}[l-k] = r_{ss}[l], \quad l = 0, 1, \dots\\[0.2cm] h[n] * r_{xx}[n] = r_{ss}[n] \quad \implies \quad H(f) = \frac{P_{ss}(f)}{P_{xx}(f)} = \frac{P_{ss}(f)}{P_{ss}(f) + P_{ww}(f)} → k = 0 ∑ n h [ k ] r x x [ l − k ] = r s s [ l ] , l = 0 , 1 , … , n As n → ∞ , k = 0 ∑ ∞ h [ k ] r x x [ l − k ] = r s s [ l ] , l = 0 , 1 , … h [ n ] ∗ r x x [ n ] = r s s [ n ] ⟹ H ( f ) = P x x ( f ) P s s ( f ) = P s s ( f ) + P w w ( f ) P s s ( f )
All Content has been written based on lecture of Prof. eui-seok.Hwang in GIST(Detection and Estimation)