[논문 리뷰] Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection
2024 하계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 하계 논문 세미나 활동입니다. 논문의 전문은 여기에서 확인 가능합니다.
Abstract
- Zero-shot anomaly detection (ZSAD)는 타겟 데이터셋에서 어떠한 학습 샘플 없이도 이상을 탐지할 수 있는 모델을 필요로 함
- 데이터 프라이버시가 중요한 분야에서 유용하게 사용될 수 있지만, 다양한 도메인에서 이상을 일반화하는 것은 어려운 문제임
- 최근 VLM이 다양한 비전 태스크에서 zero-shot 인식 능력을 보인다곤 하지만, 여전히 VLM은 이미지에서의 정상/이상보다는 foreground 객체의 범주 모델링에 더 집중함
- 제안하는 AnomalyCLIP은 일반적인 정상성, 이상성을 포착할 수 있는 object-agnostic 텍스트 프롬프트를 학습할 수 있음
1. Introduction
Zero-shoit anomaly detection (ZSAD)는 타겟 데이터셋에서의 어떠한 학습 샘플 없이 이상을 탐지할 수 있는 방법론을 연구하는 태스크이다.
해당 작업이 필요한 경우는, 데이터 프라이버시 정책에 위반해서 학습 데이터를 활용할 수 없는 경우, 타겟 도메인이 관련된 학습 데이터를 아직 갖고 있지 못한 경우 등이 있다.
ZSAD를 정확하게 하려면 다양한 도메인에서 일반화 성능을 보여야하는데 쉽지 않다.
제품 하나의 표현 결함도 있을 수 있고, 다른 제품들의 표현 결함도 있을 수 있고, 장기들에 종양도 예시가 될 수 있다.
사전 학습된 거대 vision-language 모델 (VLM)은 다양한 비전 태스크에서 강한 zero-shot 인식 능력을 보인다. 대표적인 예시로 CLIP이 있으며, WinCLIP 모델은 ZSAD 관점에서 연구되기도 했다.
하지만 VLM은 이미지에서의 정상성/이상성 보다는 foreground 객체의 범주 semantic에 align되도록 학습된다는 특징이 있으며, 이는 약한 ZSAD 성능으로 이어진다.

최근 프롬프팅 접근법은, 직접 사전에 정의한 텍스트 프롬프트를 활용하는 방법과 학습 가능한 프롬프트를 활용하는 방법 등이 있는데, 이는 위 그림 (d), (e)에서 볼 수 있듯 이상 영역보다는 객체 클래스 전체에 align 되는 경향이 있다.
그래서 저자들은 AnomalyCLIP 모델을 제안하며, 이는 foreground 객체와 상관없이 일반적인 정상성, 이상성을 포착할 수 있는 object-agnostic한 텍스트 프롬프트 학습을 목표로 한다.
해당 방법론은 간단하지만 보편적으로 효과적인 학습 가능한 프롬프트 탬플릿을 정상성, 이상성 클래스에 대해 고안하고, image-level & pixel-level 손실함수를 이용하여 전역적, 지역적으로 정상성과 이상성을 학습할 수 있도록 한다.
이에 따라 모델이 객체 의미보다는 비정상 영역에 집중할 수 있도록하고 임의의 데이터의 유사한 비정상 패턴을 인식할 수 있도록 했다.

위 그림 (a), (b)를 보면 타겟 도메인, 물체가 다르더라도 결함은 유사한 패턴을 보이는 것을 알 수 있다.
본 논문의 기여점을 정리하면 다음과 같다.
- 처음으로 정상성/이상성에 대한 학습 가능한 object-agnostic 텍스트 프롬프트를 제안하여 정확한 ZSAD가 가능하도록 하였다.
- 제안하는 AnomalyCLIP 모델은 object-agnostic 프롬프트 템플릿과 전역, 지역 손실함수의 조합인 glocal 비정상 손실 함수를 활용하여 일반화된 정상성/이상성 프롬프트를 학습할 수 있도록 하였다.
- 산업과 의료 도메인의 17가지 데이터셋에 대한 실험을 통해 AnomalyCLIP의 훌륭한 ZSAD 성능을 증명하였다.
2. Preliminary
CLIP은 텍스트 인코더와 비전 인코더로 구성되어 있다. 두 인코더 모두 ViT와 같은 mainstream multi-layer 네트워크이다. 텍스트 프롬프트를 사용하는 것이 zero-shot 인식에서 서로 다른 클래스를 임베딩하는 전형적인 방법이다.
CLIP에서 사용하는 일반적인 텍스트 프롬프트 템플릿은 다음과 같이 A photo of a [cls] 로 되어있고, [cls]가 타겟 클래스 이름이다. CLIP은 텍스트, 비전 임베딩 간의 유사도를 측정하여 zero-shot 인식을 수행한다. 어쨌든 결론적으로 클래스를 예측하는 Anomaly score는 다음과 같다.
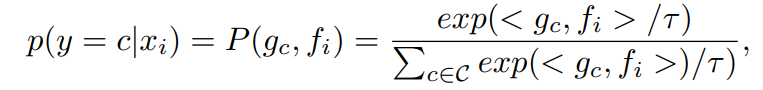
<.,.>이 cosine 유사도이다. CLIP을 사용해서 ZSAD한다면 [cls]는 정상/이상이다.
3. AnomalyClip: Object-Agnostic Prompt Learning
3.1 Approach Overview
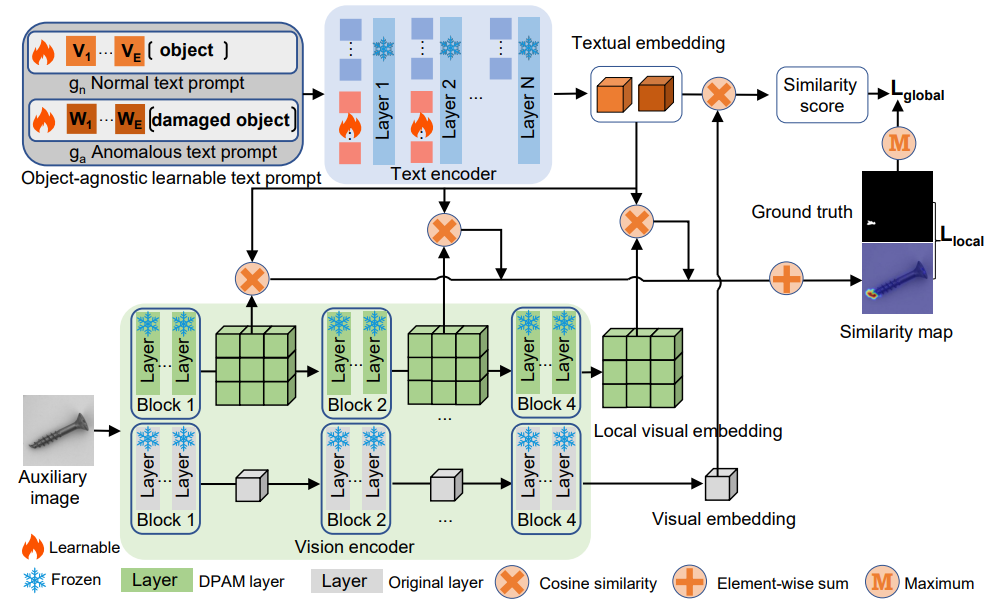
위 그림이 전체적인 모델 프레임워크이다. AnomalyCLIP은 두 개의 일반적인 object-agnostic 텍스트 프롬프트 템플릿인 , 를 고안해서 정상과 이상 클래스에 대한 일반화된 임베딩을 학습한다.
이러한 일반화된 텍스트 프롬프트 템플릿을 학습하기 위해 전역적, 지역적 context 최적화를 사용한다.
추가로 textual prompt tuning과 DPAM을 사용해서 CLIP의 textual & local visual 공간을 학습한다.
최종적으로 multiple 중간층을 결합하여 더욱 많은 지역적 visual detail을 제공한다.
학습 시에는, 모든 모듈이 전역적, 지역적 context 최적화에 의해 함께 최적화되며, 추론 시에는, textual과 global/local visual 임베딩 간의 misalignment를 측정하여 anomaly score와 anomaly score map을 획득한다.
3.2 Object-Agnostic Text Prompt Design
기존 CLIP에서의 텍스트 프롬프트는 객체 의미에 집중할 뿐 정상/이상 의미를 포착하는 textual 임베딩을 생성하지는 못한다.
Anomaly-discriminative 텍스트 임베딩을 학습하기 위해, 텍스트 프롬프트 템플릿에 prior anomaly semantic을 통합하는 것을 목표로 했다.
간단한 방법으로는 템플릿을 특정한 이상 타입과 함께 디자인하는 거고, 예시로 A photo of a [cls] with scratches가 있다.
하지만 이상 패턴은 일반적으로 알려져있지 않고 다양하기 때문에 모든 가능한 이상 타입을 나열하는 것은 어렵다.
따라서 일반화된 anomaly semantic으로 텍스트 프롬프트 템플릿을 규정할 필요가 있었고 damaged [cls] 로 모든 anomaly semantics을 커버할 수 있었다. 하지만 해당 텍스트 프롬프트를 사용하면 여전히 anomaly-discriminating 텍스트 임베딩을 생성하는 데는 무리가 있었다. 그 이유는 CLIP의 원래 사전 학습은 object semantic에 align되는 걸 집중하기 때문이다.
이러한 한계를 극복하고자 학습 가능한 텍스트 프롬프트 템플릿을 도입하고 임의의 AD-관련된 데이터로 튜닝하는 방법을 도입했다. Fine-tuning 시에 학습 가능한 템플릿은 broad/detailed anomaly semantics을 통합할 수 있었고 결과적으로 정상/이상에 대해 더욱 분별력있는 텍스트 임베딩을 얻을 수 있었다. 이는 수동으로 정의가 필요한 텍스트 프롬프트 템플릿의 필요성을 피할 수 있었다.
이러한 텍스트 프롬프트는 object-aware text prompt templates으로 정의했다.
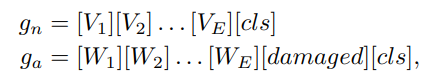
여기서 와 가 각각 정상/이상에 대한 학습 가능한 단어 임베딩이다.
ZSAD 태스크는 보지 못한 타겟 데이터셋에서도 이상을 탐지해야한다. 이러한 데이터셋은 서로 다른 객체여서 object semantics가 상당히 다양하다. 저자가 여기서 주목한 것은 object semantics가 상당히 다르더라도, 이상 패턴은 유사할 수 있다는 것이다. ZSAD를 정확히 하기 위해서는 서로 다른 객체의 다양한 semantic과는 상관없이 일반적인 이상 패턴을 잘 식별해야한다는 것이다.
따라서 object-aware text prompt에서 object semantics를 넣는 것은 ZSAD에서는 불필요하고, 오히려 제거해야지 이상 특성을 포착하는데 더 유용하다는 것이다. 그래서 object-agnostic text prompt templates을 제안한다.
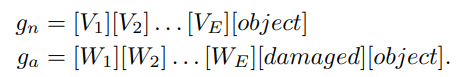
3.3 Learning Generic Abnormality and Normality prompts
Glocal context optimization
Object-agnostic text prompts를 효과적으로 학습하기 위해 전역적, 지역적 관점 모두로부터 정상성/이상성을 학습할 수 있도록 하는 joint optimization 방법을 고안한다.
global context 최적화는 다양한 객체 이미지의 전역적인 비전 임베딩을 텍스트 임베딩과 매치되도록하는게 목적이다. local context 최적화는 비전 인코더의 M개의 중간층으로부터의 fine-grained 지역적 이상 영역에 집중하도록 한다.
결론적으로 제안하는 텍스트 프롬프트는 아래 glocal 손실함수를 최소화하는 방향으로 학습된다.
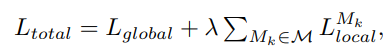
는 전역과 지역 손실의 균형을 위한 하이퍼파라미터이다. 은 object-agnostic textual 임베딩과 비전 임베딩간의 코사인 유사도를 매칭하는 cross-entropy loss 이다.
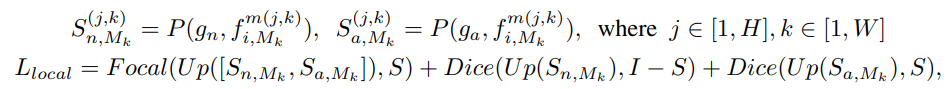
는 세그멘테이션 작업의 정답이고, 일 때가 해당 픽셀이 이상이라는 것이다.
Focal과 Dice는 각각 세그멘테이션에서 사용되는 손실함수이다. Focal loss를 사용해서 정상과 이상의 불균형 문제를 다루고자 했다. 추가로 모델이 정확한 decision boundary를 만들 수 있도록 하기 위해, Dice loss를 사용했다.
Refinement of the textual space
더욱 분별력 있는 텍스트 공간을 학습하도록 촉진하기 위해 CLIP의 원본 텍스트 공간에 추가적인 학습 가능한 토큰 임베딩을 더했다. 이는 랜덤하게 초기화된 학습 가능한 토큰 임베딩 이며 원본 토큰 임베딩 에 concatenate되어 입력된다.
입력시에 , 다 입력하며 각각의 결과가 , 이라고 할 때, 이 결과는 버린다. 하지만 self-attention으로 인해 역전파시 영향은 미치게 된다. 이걸 반복하면 원본 텍스트 공간을 refine할 수 있다.
Refinement of the local visual space
CLIP의 비전 인코더는 global object semantics에 align되도록 사전학습 되었기 때문에 CLIP에서 사용되는 contrastive loss는 클래스 인식에만 도움이 된다. Self-attention 매커니즘을 사용하면 특정 토큰에만 집중하는 것을 볼 수 있고 이는 global object 인식에는 도움이 될 수 있으나, local visual semantic에는 방해가 된다. 아래 그림의 (b)에서의 빨간색 네모가 그 예시이다.
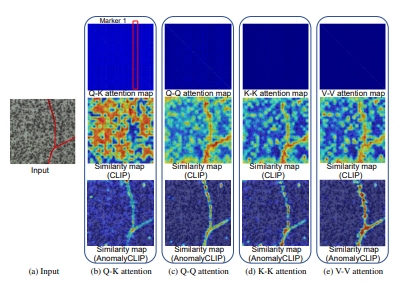
그래서 저자들은 경험적으로 diagonally prominent attention map이 다른 토큰으로부터의 방해를 줄이고 더 향상된 local visual semantics을 획득할 수 있다는 것을 증명해냈다.
저자는 이를 DPAM으로 부르고 쉽게 말해, Q-Q, K-K, V-V self attention 을 하는 것이다. 그 중 V-V self-attention이 성능이 제일 좋아서, 이를 택했다고 한다.
각각은 위 그림에서 (c), (d), (e)에서 살펴볼 수 있으며 AnomalyCLIP의 semantic map을 통해 훨씬 이상에 대한 local visual semantics을 잘 획득하는 것을 알 수 있다.
4. Experiments
4.1 Experiment setup
Datasets and Evaluation Metrics
총 17가지의 공공 오픈 데이터셋을 활용했고, 이는 산업에서의 검사 시나리오, 의료 이미지 도메인을 포함한다.
- MVTec AD / VisA / MPDD / BTAD / SDD / DAGM / DTD-Synthetic
- ISIC / CVC-ClinicDB / CVC-ColonDB / Kvasir / Endo / TN3k / HeadCT / BrainMRI / Br35H / COVID-19
비교한 SOTA 모델은 CLIP, CLIP-AC, WinCLIP, VAND, CoOp이 있다.
이상 탐지 성능은 AUROC / AP (average precision)를 사용했고,
이상 세그멘테이션 성능은 AUPRO를 사용했다
Implementation details
공공으로 사용 가능한 CLIP 모델을 백본으로 활용했다.
CLIP의 모델 파라미터는 frozen 시켰다.
학습 가능한 단어 임베딩 는 12로 설정했으며, 텍스트 인코더의 처음 9개 층에 부착했다.
AnomalyCLIP을 MVTec AD 테스트셋을 통해 fine-tune했으며, 다른 데이터셋으로 ZSAD 성능을 평가했다.
MVTec AD 데이터셋 성능 평가시에는 VisA 데이터셋을 통해 fine-tune했다.
4.2 Main results
ZSAD performance on diverse industrial inspection domains
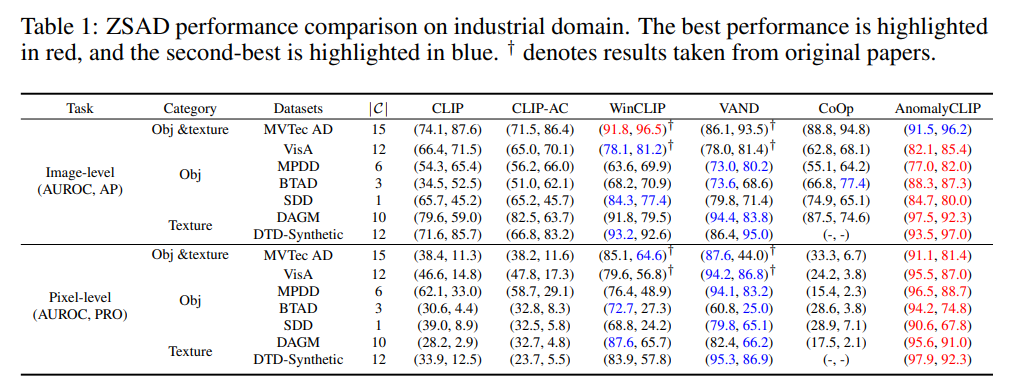
다양한 foreground objecs, background, anomaly types에서 좋은 성능을 보였다.
CLIP이나 CLIP-AC는 object semantics에 align하는데 집중해서 anomaly semantics을 잘 못했다.
WinCLIP이나 VAND는 잘하긴 했는데, global anomaly semantics 학습에 집중하고 fine-grained local anomaly semantics은 무시해서 이상 세그멘테이션에서는 그닥 잘하지 못했다.
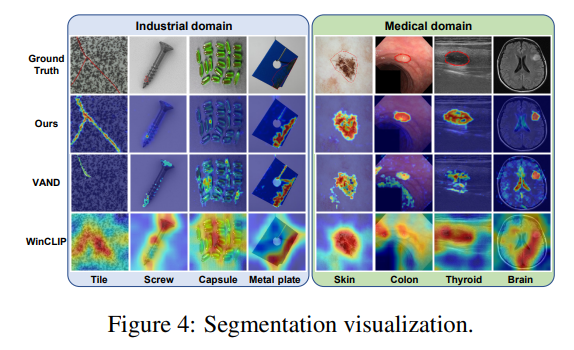
시각적으로 살펴보면 훨씬 뚜렷하게 그 차이를 알 수 있다.
Generalization from defect datasets to diverse medical domain datasets
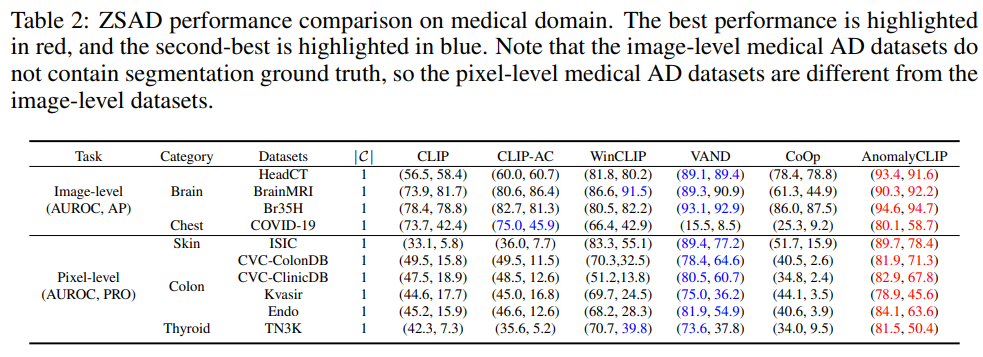
의료 이미지에서도 상당히 잘하는 모습을 볼 수 있는데, 괄목할만한 점은 fine-tune한 데이터셋이 결함 탐지 데이터셋임에도 불구하고 의료 도메인 이미지에서도 이상을 잘 찾아낸다는 점이다. Figure 4에서의 시각화 이미지를 보면 더 뚜렷하게 와닿는다.
Can we obtain better ZSAD performance if fine-tuned using medical image data?
산업 데이터셋에 비해 의료 데이터셋에서 성능이 살짝 낮은걸 볼 수 있는데, fine-tune을 산업 데이터셋을 활용했기 때문이다. 그렇다면 의료 데이터셋으로 fine-tune하면 성능이 좋지 않을까 싶지만, 산업 데이터셋과 달리 image-level과 pixel-level annotation을 포함하는 대규모 2D 의료 데이터셋이 존재하지 않은게 문제였다.
그래서 저자는 ColonDB 데이터셋을 기반으로 데이터셋을 새롭게 만들어서 평가를 해보았다.
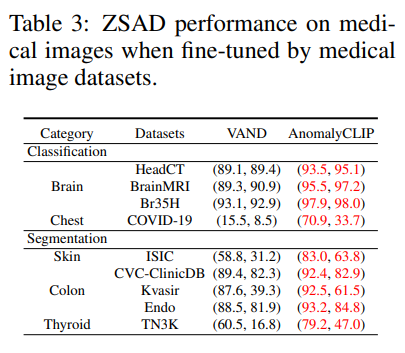
그랬더니 훨씬 좋은 성능을 얻는 것을 볼 수 있었다. 특히 visual 유사도가 높은 colon polyps나 brain tumors 쪽에서 성능 향상의 폭이 컸다.
Object-agnostic vs. object-aware prompt learning
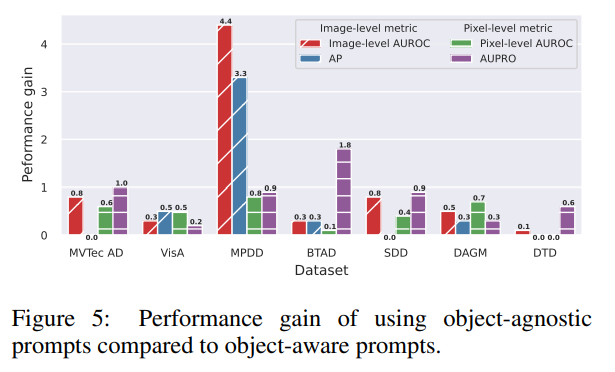
AnomalyCLIP은 object-agnostic prompt 학습을 사용했고 object-aware prompt를 사용하는 것에 비해 어느 정도 성능 향상이 있었는지는 위 그림을 통해 살펴볼 수 있다.이를 통해 ZSAD 태스크에 있어서 object semantics은 종종 도움이 되지 않고 오히려 noisy feature가 될 수 있다는 것을 확인할 수 있다.
4.3 Ablation study
Module ablation
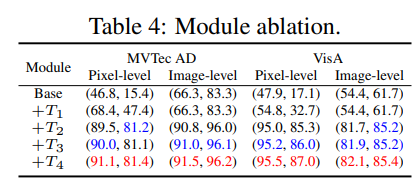
DPAM (T1), object-agnostic text prompts (T2), added learnable tokens in text encoders (T3), and multi-layer visual encoder features (T4)
에 대한 Ablation study 결과는 위와 같다.
성능 향상 폭 기여도 1등은 object-agnostic text prompts (T2) 이 친구.
Context optimization
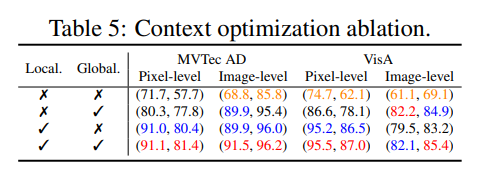
Glocal loss 대신에 Local이나 Global loss를 사용했을 시에는 어느 정도 성능 하락 폭이 있었는지에 대한 Ablation study
DPAM strategy ablation
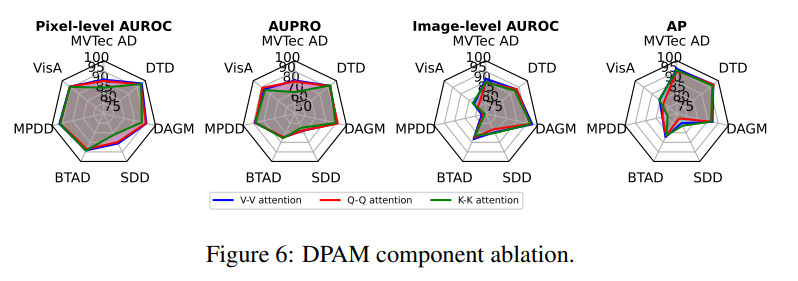
V-V attention, Q-Q attention, K-K attention 사용했을 시에 뭐가 제일 좋은지에 대한 실험.
앞서 언급했듯 V-V attention이 제일 좋긴하지만 사실 큰 차이는 없어보인다.
6. Conclusion
본 논문은 학습을 위해 타겟 데이터셋에 사용 가능한 데이터가 없는 상황에서 이상 탐지하는 ZSAD 분야를 정복하기 위해 AnomalyCLIP을 활용하였다.
이는 object-agnostic 프롬프트를 제시하여 정상성/이상성에 대한 text 프롬프트를 잘 학습할 수 있도록 했다. 또한 global/local anomaly semantics를 잘 통합하여 최적화시에도 효과를 거뒀다.
17개의 데이터셋을 통해 ZSAD 성능이 우수함을 증명하였다.
