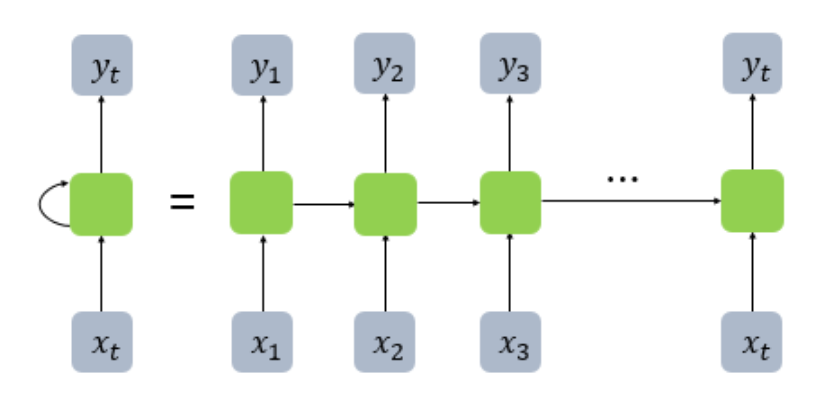
RNN(순환신경망)
순차 데이터나 시계열 데이터에 가장 기본적이면서 대표적인 인공 신경망
- 입력과 출력을 시퀀스 단위로 처리
- Cell은 이전 time step에서의 출력값을 기억하는 역할을 수행하므로 메모리 셀 또는 RNN Cell
- Cell이 값을 기억한다는 것은 이전 time step에서 Hidden Layer의 메모리 셀의 출력값을 자신의 입력값으로써 재귀적으로(recursively) 사용
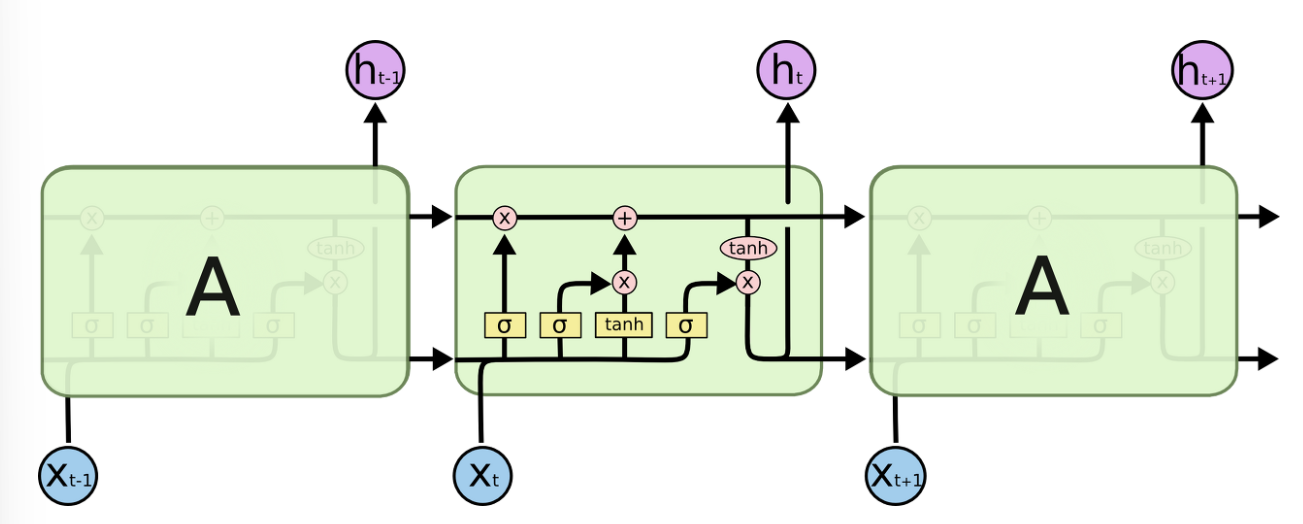
LSTM
RNN의 특별한 한 종류로, 긴 의존 기간의 문제 해결을 위해 설계된 인공 신경망
- Cell State가 셀의 값을 얼마나 기억할지 결정하는 것이 가능한 게이트를 가지고 있어서 필요한 정보만 기억하도록 억제할 수 있음
FinanceDataReader에서 한국 주식 Dataset 실습 RNN
1. 주식 데이터를 불러오기
pip install -U finance-datareader
df = fdr.DataReader('086520', start = '2021' ).reset_index()
df.tail()
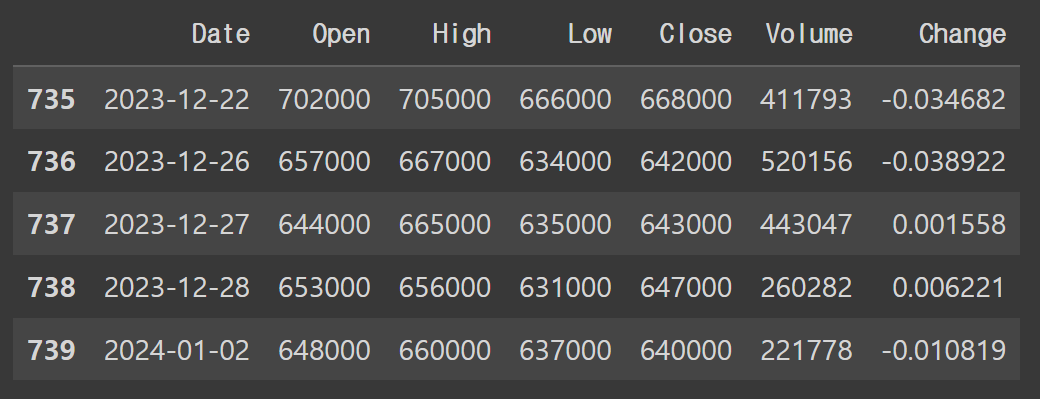 원하는 주식 종목의 코드 / 시작, 종료 시점을 정하여 데이터셋을 가져온다.
원하는 주식 종목의 코드 / 시작, 종료 시점을 정하여 데이터셋을 가져온다.
2. 데이터 전처리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
from sklearn.metrics import mean_squared_error
from matplotlib.dates import DateFormatter
data=df[['Volume']]
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
def generate_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
seq = data[i:i+seq_length]
label = data[i+seq_length]
X.append(seq)
y.append(label)
return np.array(X), np.array(y)
X, y = generate_sequences(data_scaled,10)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)필자는 Volume(=거래량)을 target 변수로 예측을 진행해 보았다
3.모델링
단순한 RNN모델 생성
model = Sequential()
model.add(SimpleRNN(50, activation='relu', input_shape=(10, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test))
y_pred = model.predict(X_test)y_test_original = scaler.inverse_transform(y_test)
y_pred_original = scaler.inverse_transform(y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
rmse- 스케일링 후 모델 학습을 진행했기 때문에 rmse값도 스케일링된 데이터로 구해야 한다
4. 실제 VS 예측 시각화
plt.figure(figsize=(12, 6))
plt.plot(df['Date'], data['Volume'], label='Actual', color='blue')
plt.plot(df['Date'][-len(y_test_original):], y_pred_original, label='Predicted', color='red')
plt.title('Stock Price Prediction - Entire Data Flow with Prediction')
plt.xlabel('Date')
plt.ylabel('Stock Price')
plt.legend()
plt.show()2023-08 / 2023-09 시기에는 예측을 잘 못했지만 나머지 부분에서의 경향성은 맞는것으로 보임
제주시 시간별 외식 인원 Dataset 실습 LSTM
- 제주특별자치도에서 제공하는 제주도내 시간대별 / 연령대별 / 성별 외식업 이용자 수 데이터
1.데이터 불러오기
# Load the provided CSV file
file_path = '/content/시간대별 외식업 이용자수.csv'
df = pd.read_csv(file_path, encoding='CP949')
# Displaying the first few rows of the dataset to understand its structure
df.head()2.시각화
import matplotlib.pyplot as plt
import seaborn as sns
# Converting 'base_year_month' to a datetime format for time series analysis
df['base_year_month'] = pd.to_datetime(df['base_year_month'], format='%Y%m')
# Grouping the data by 'base_year_month' and summing the 'user_count' for each month
monthly_data = df.groupby('base_year_month')['user_count'].sum().reset_index()
# Plotting the time series data
plt.figure(figsize=(12, 6))
sns.lineplot(x='base_year_month', y='user_count', data=monthly_data)
plt.title('Monthly User Count Over Time')
plt.xlabel('Year-Month')
plt.ylabel('User Count')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
3.전처리
- Target = user_count (이용자 수)
- 다른 Feature들은 정확도에 부정적 영향을 미치기에 제거
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
# 데이터 전처리
# 'user_count' 열만 사용합니다.
data = df['user_count'].values
data = data.reshape(-1, 1)
# 데이터 정규화
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data)
# LSTM에 사용할 데이터 형태로 변환하는 함수
def create_dataset(dataset, look_back=1):
X, Y = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
X.append(a)
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
# 데이터셋 분할
look_back = 1
X, Y = create_dataset(data, look_back)
train_size = int(len(X) * 0.67)
test_size = len(X) - train_size
trainX, testX = X[0:train_size], X[train_size:len(X)]
trainY, testY = Y[0:train_size], Y[train_size:len(Y)]4.모델링
# LSTM 모델 구축
model = Sequential()
model.add(LSTM(4, input_shape=(look_back, 1)))
model.add(Dense(1))
# 모델 컴파일
model.compile(loss='mean_squared_error', optimizer='adam')
# 모델 요약 출력
model.summary()
# 모델 학습
model.fit(trainX, trainY, epochs=20, batch_size=1, verbose=2)
# 학습된 모델 저장
model_path = '/mnt/data/lstm_user_count_model.h5'
model.save(model_path)
model_path5. 결과 vs 예측 시각화
import pandas as pd
import matplotlib.pyplot as plt
from keras.models import load_model
import numpy as np
# LSTM 모델 로드
model = load_model('/mnt/data/lstm_user_count_model.h5')
# Test 데이터셋을 사용하여 예측
test_predict = model.predict(testX)
# 예측값과 실제값의 역정규화
test_predict = scaler.inverse_transform(test_predict)
testY_inverse = scaler.inverse_transform([testY])
# 시각화
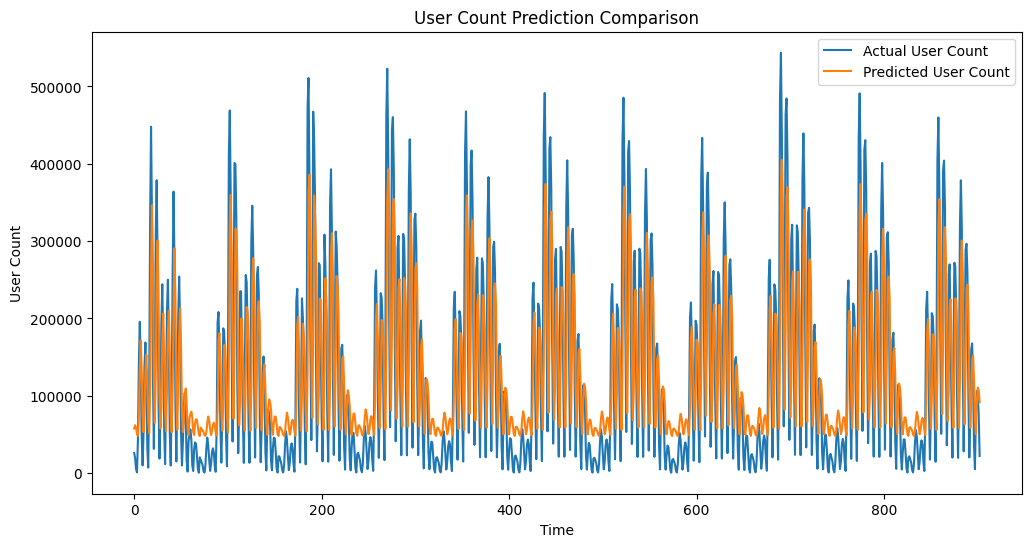
plt.figure(figsize=(12, 6))
plt.plot(testY_inverse[0], label='Actual User Count')
plt.plot(test_predict[:, 0], label='Predicted User Count')
plt.title('User Count Prediction Comparison')
plt.xlabel('Time')
plt.ylabel('User Count')
plt.legend()
plt.show()