Paper: End-to-End Object Detection with Transformers
🔍1. Introduction
객체 탐지(object detection)의 목표
: 이미지 내 객체의 bounding box와 category label을 예측 하는 것.
다만, 기존에는 이걸 다 복잡하게 풀어왔음.
어떻게?
다수의 anchor box를 생성하거나,
proposal을 만들고,
각각에 대해 분류(classification) 및 회귀(regression) 수행
=> 많은 후처리 단계 必 (ex. 중복 박스를 제거하기 위한 NMS (non-maximum suppression), anchor 디자인 등)
=> 결과적으로 모델 성능은 설계자의 사전 지식이나 설정에 크게 의존하게 됨.
본 논문에서는 객체 탐지를 직접적인 집합 예측(set prediction) 문제로 재정의함
=> 위에서 언급한 중간 단계들을 제거하고 전체 파이프라인을 간소화
DETR(Detection Transformer) 구조
- CNN backbone으로 이미지 feature 추출
- Transformer encoder-decoder 구조를 통해 global context 학습
- 고정된 개수의 object query를 사용해 병렬적으로 객체를 예측
- 예측 결과와 정답을 1:1로 매칭하는 Hungarian matching을 통해 loss 계산
= anchor box, NMS, proposal network 등 기존 탐지기의 구성 요소를 모두 제거하고도 동등한 성능
DETR 장점
- 기존 탐지기와 달리 구조가 단순함 (CNN + Transformer만으로 구성됨)
- 중복 제거가 모델 구조 내부에서 해결됨 (NMS 불필요)
- 동일 구조로 segmentation 등 복합 task에도 확장 가능함
-성능 측면에서도 COCO 데이터셋 기준으로 Faster R-CNN과 유사한 정확도를 기록(특히 큰 객체에 대해 더 뛰어난 성능 O. 다만, 작은 객체는 상대적으로 성능 ↓)
객체 탐지를 위한 새로운 end-to-end 접근 방식을 제안하고, 기존의 복잡한 구조와 수작업 설계를 줄일 수 있는 가능성을 보여줌!
✅2. Related work
DETR는 다음 several domains 기반으로 build된 모델.
- Set Prediction을 위한 Bipartite Matching Losses
- Transformer 기반의 Encoder-Decoder 구조
- Parallel Decoding
- 기존 객체 탐지 방법론들
Set Prediction
딥러닝에서 집합(set)을 직접 예측하는 표준적인 방법은 아직 존재 X.
가장 간단한 집합 예측 문제는 멀티라벨 분류(multilabel classification)
- 보통은 one-vs-rest 방식으로 각 클래스별로 독립적인 예측을 수행함.
- 하지만 객체 탐지처럼 예측 간 구조적 제약(structural constraints)이 있는 문제에는 적용하기 어려움.
(ex: 비슷한 위치에 겹쳐 있는 예측 박스 多)
<기존 탐지기 해결 방식>
: 후처리(postprocessing) 단계에서 해결
ex. NMS (Non-Maximum Suppression)
: 겹치는 박스 중 신뢰도 높은 것 하나만 남기고 나머지 제거
But, 이 방식은 모델 외부에서 작동 & 학습 과정에 통합되지 X.
→ end-to-end 학습이 어려움
그렇다면 중복 없이 한 번에 예측하려면 어떤 조건이 필요할까?
- 예측 간 상호작용을 고려할 수 있는 전역적 추론 구조(global inference)
- 예측 순서에 상관없는 Permutation-Invariant Loss
이런 조건을 만족시키기 위해 하기 시도들이 있었음.
- Dense fully connected network로 모든 예측 간 관계 모델링
: But,계산량이 크고 비효율적 - RNN 기반 autoregressive model 사용 → 예측을 순차적으로 생성하면서 중복 방지 가능
: But, 느리고 병렬화 어려움
<가장 보편적인 해결책: Hungarian Matching>
순서를 고려하지 않는 집합 예측 문제에서 가장 널리 쓰이는 접근
: Hungarian 알고리즘 기반의 matching loss
- Ground Truth와 예측 간의 최적의 1:1 대응 관계를 찾음
- 대응된 쌍들만 loss 계산에 사용함
- 덕분에 예측의 순서(permutation)에 영향을 받지 않음
DETR도 이 방식을 따르긴 하나, 기존과의 차이점은?
- RNN 대신 Transformer 사용
- 병렬 예측(parallel decoding)으로 성능과 학습 속도 모두 확보
즉, DETR은 이전 autoregressive 방식의 set prediction 연구들과는 다르게
Transformer 기반의 비순차적 예측 구조에 Hungarian loss를 결합한 첫 실용적 객체 탐지기라는 것!
Transformers and Parallel Decoding
Transformer는 원래 기계번역(machine translation)을 위해 제안된 구조.
핵심 구성요소: Self-Attention.
= 시퀀스의 모든 토큰이 서로를 바라보며 전역 정보를 통합할 수 있음.
= 구조적으로 Non-Local Neural Network와 유사
- Global Computation: 시퀀스 전체를 동시에 고려 가능
- Long-Term Memory 유지: RNN보다 긴 의존 관계를 잘 처리함
- 병렬 계산 가능: RNN과 달리 토큰 간 의존성이 없음
=> 기존 RNN을 대체하며 널리 쓰이게 됨.
다만, Transformer가 처음 쓰인 영역은 대부분 Autoregressive decoding 기반.
- 추론 속도가 느림
- 출력 길이에 따라 연산량 선형 증가
- Batch 처리 어려움
그래서 Parallel Decoding이 등장함
= 출력 시퀀스를 한 번에 예측하도록 설계
- 연산량 대비 성능의 효율적인 절충점을 제공함
- 전역 정보를 처리하면서도 병렬성이 확보됨
DETR은 Transformer의 global attention 구조를 그대로 활용하면서,
출력 단계를 Autoregressive가 아닌 Parallel 방식으로 처리
- N개의 object query를 병렬로 던져서 예측
-> 각 query는 한 객체 예측을 담당
-> 중복 없이 예측하도록 Hungarian Matching으로 제약
이 구조 덕분에, DETR은 순차적 디코딩 없이도
전역 정보를 이용한 세트 예측이 가능해짐!
Object detection
대부분의 기존 객체 탐지기는 초기 추정(initial guess)에 기반하여 예측함
Two-stage detector (ex. Faster R-CNN)
: Region Proposal Network(RPN)으로 후보 박스 생성 후 refinement
Single-stage detector (ex. RetinaNet, FCOS 등)
: 고정된 위치의 anchor box나 grid 중심점 기준으로 예측 수행
모델이 직접 bounding box를 예측하는 것 X,
사전에 정해진 기준(anchor, proposal 등)에 대해 상대적으로 offset을 예측함.
But, anchor나 proposal의 설계가 성능에 큰 영향을 줌.
- anchor의 크기, 비율, 위치를 어떻게 설정하는지에 따라 성능이 달라짐
- GT와 anchor 간 매칭 방식도 성능에 영향
- 대부분 hand-crafted 방식으로 설계됨
DETR은 상단 과정을 완전히 제거
입력 이미지 자체를 기준으로 절대적인 bounding box 좌표를 직접 예측함.
-> anchor, proposal, grid 설계 등 불필요
-> 학습 과정 자체가 더 간단하고 구조적으로 통일됨
탐지 과정을 처음부터 세트 예측(set prediction)으로 재구성함.
- Transformer의 self-attention으로 전역적 상호작용을 학습
- 직접적인 set-based loss만 사용
- 핸드메이드 구조/휴리스틱 없음
중복 제거와 상호작용 모두 모델 구조 내부에서 처리
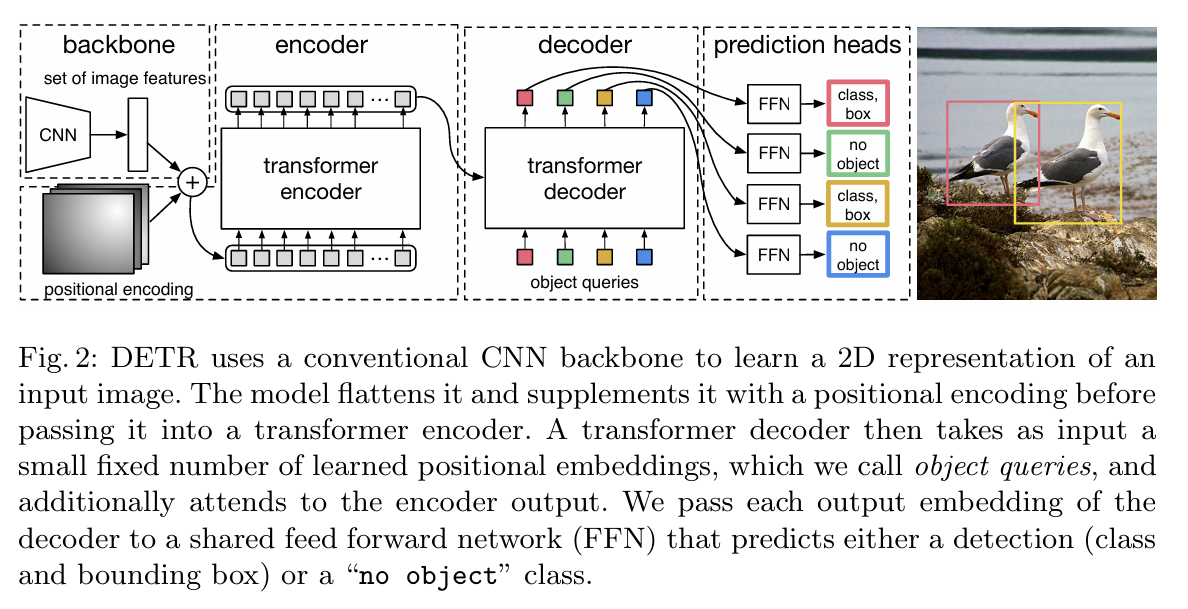
✅3. The DETR model
DETR은 객체 탐지를 집합 예측(set prediction)으로 정의
1. Set Prediction Loss
: 예측 결과와 정답 사이의 1:1 매칭을 강제하는 loss
2. Transformer 기반 아키텍처
: 한 번의 forward pass로 전체 객체를 동시에 예측
: 예측 간 관계를 전역적으로 모델링 가능
Object detection set prediction loss
DETR는 이미지마다 고정된 개수 N개의 객체 예측을 출력함.
: 일반적으로 N은 이미지 내 실제 객체 수보다 큼 (ex. N=100)
: 따라서 예측된 N개 중 일부는 실제 객체, 나머지는 "no object" (∅)
객체 탐지에서 중요한 건 중복 없이 정확한 예측과 GT의 대응 관계를 만드는 것.
기존 탐지기들은 anchor나 proposal과 GT 사이를 연결하기 위해
IoU 기반 휴리스틱, threshold, NMS 등을 사용했음.
DETR는 이런 복잡한 규칙 대신,
Hungarian Matching 알고리즘을 이용해 1:1 최적 매칭을 직접 계산함.
Hungarian Matching
예측과 GT 간 최소 비용으로 1:1 대응되는 permutation σ∈SN을 찾는 것
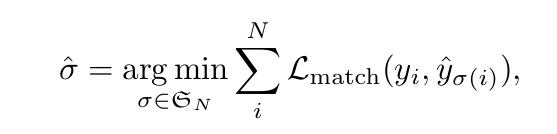
예측된 클래스의 확률과 예측된 box와 GT box의 거리로 Lmatch가 구성되는데, 이 두 값을 합쳐서 매칭 비용을 계산함.
Hungarian Loss 계산
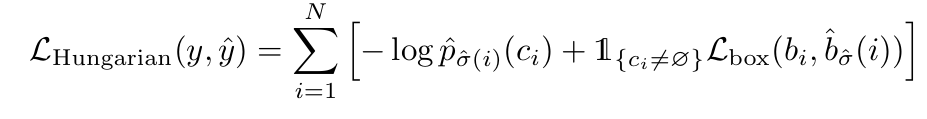
매칭이 완료되면, 최종 손실 L_hungarian은 위와 같이 계산됨.
클래스가 ∅일 경우에는 log 확률 항의 가중치를 낮춤 (10배 down-weight)
: 배경 클래스가 전체 학습을 지배하지 않도록 조정
클래스 예측에는 log가 아닌 확률 값 p^ 사용
: 박스 손실과 스케일을 맞추기 위함 (실험적으로 성능 향상 확인됨)
Bounding box loss
DETR는 anchor offset이 아닌, 절대 좌표 기반의 box 예측을 수행함.
: 박스 손실의 스케일 문제를 해결하기 위해 두 가지를 조합함
- L1 Loss: 박스 좌표 차이
- GIoU Loss: 스케일 불변 성질을 가지는 IoU 기반 손실 (Rezatofighi et al., 2019)
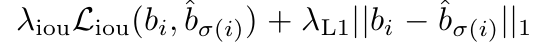
최종 box loss는 위와 같이 계산됨.
DETR는 객체 예측 결과와 GT 간의 최적 매칭을 Hungarian 알고리즘으로 찾고, 각 매칭에 대해 클래스 손실 + 박스 손실을 계산하여 학습함. anchor나 NMS 없이도 중복 없는 정확한 예측이 가능해짐.
DETR architecture
DETR의 전체 구조는 매우 단순!
: 복잡한 anchor 설정이나 region proposal module 없이 하단 3개의 컴포넌트로 구성됨.
1) CNN Backbone
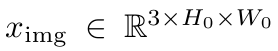
상단 입력 이미지 수식
-> 일반적인 ResNet 등의 CNN을 사용하여 feature map
f∈R^(C×H×W) 추출
-> 해당 feature map은 Transformer 입력으로 사용됨
2) Transformer Encoder-Decoder
2-1) Encoder
CNN 출력 feature map f를 1×1 convolution으로 차원 축소 →
d차원의 z_0 ∈R^(d×H×W) 생성
-> flatten하여 길이 HW의 시퀀스로 변환
이후 standard Transformer Encoder에 입력
각 layer는 multi-head self-attention + FFN 구조
위치 정보 손실 방지를 위해 fixed positional encoding 추가됨 (2D -> 1D 사인/코사인 인코딩)
이 단계에서 feature map의 모든 위치가 서로 전역적으로 정보를 주고받음
2-2) Decoder
Decoder의 입력은 N개의 학습 가능한 object queries
: 각각은 하나의 객체 예측을 담당
크기: R^(N×d)
- 각 query는 positional encoding 역할을 하며, 서로 다른 출력을 유도함.
- 모든 object query는 병렬적으로 처리됨
(기존 Transformer와 달리 autoregressive 아님)
Decoder는
- self-attention: query 간 상호작용
- encoder-decoder attention: image feature와 상호작용
=> 각 query가 이미지 전체를 참고하면서 객체 정보 추출
3) Feed-Forward Network (FFN) for prediction
각 decoder 출력 embedding은 공통된 FFN을 통과함
→ 클래스 + bounding box 예측
구조: 3-layer MLP + ReLU, 최종 Linear 출력
출력:
- 클래스 확률 (softmax)
- bounding box 좌표 (center_x, center_y, width, height) → [0,1] 정규화된 값
N개의 예측 중 실제 객체가 아닌 것들은 “no object” (∅) 클래스로 분류됨
→ 일반적인 detector에서의 배경(background) 클래스에 해당
+) Auxiliary decoding losses
학습을 안정화하고 더 나은 성능을 위해
: 각 decoder layer 출력마다 동일한 FFN + Hungarian loss를 적용함
모든 layer의 FFN은 파라미터 공유
각 층에서 예측한 결과에 대해 보조 손실 계산
-> Decoder가 더 빠르게 수렴하고, 정답 개수 예측이 안정적으로 됨
LayerNorm도 각 층 입력을 정규화하는 데 사용됨
DETR는 CNN으로 이미지 feature를 추출하고,
Transformer로 전역 관계를 학습한 후,
object query를 통해 객체 위치/클래스를 직접 예측하는 구조.
구조는 단순하지만, Transformer + Matching Loss의 결합을 통해,
기존 객체 탐지기의 많은 복잡성을 제거함
✅4. Experiments
DETR은 COCO 벤치마크에서 Faster R-CNN과 비교해도 손색없는 성능을 보임.
또한 구성요소에 대한 ablation 실험, 그리고 panoptic segmentation으로의 확장성도 검증했음.
Comparison with Faster R-CNN
Faster R-CNN과의 성능 비교.
DETR는 Transformer 기반 구조이기 때문에, 일반적으로 AdamW, dropout, 그리고 긴 학습 스케줄이 필요함.
반면, Faster R-CNN은
SGD로 학습되고, 간단한 augmentation만 사용하는 것이 일반적임
실제로 Adam이나 dropout을 적용한 예시는 거의 없음
Faster R-CNN을 DETR과 비교하기 위해 튜닝 추가
- box loss에 Generalized IoU(GIoU) 적용
- DETR과 동일한 random crop augmentation 적용
- 기존보다 더 긴 학습 스케줄 사용 (9x schedule = 109 epoch)
=> 이 튜닝을 적용한 결과, 기존보다 1~2 AP 향상
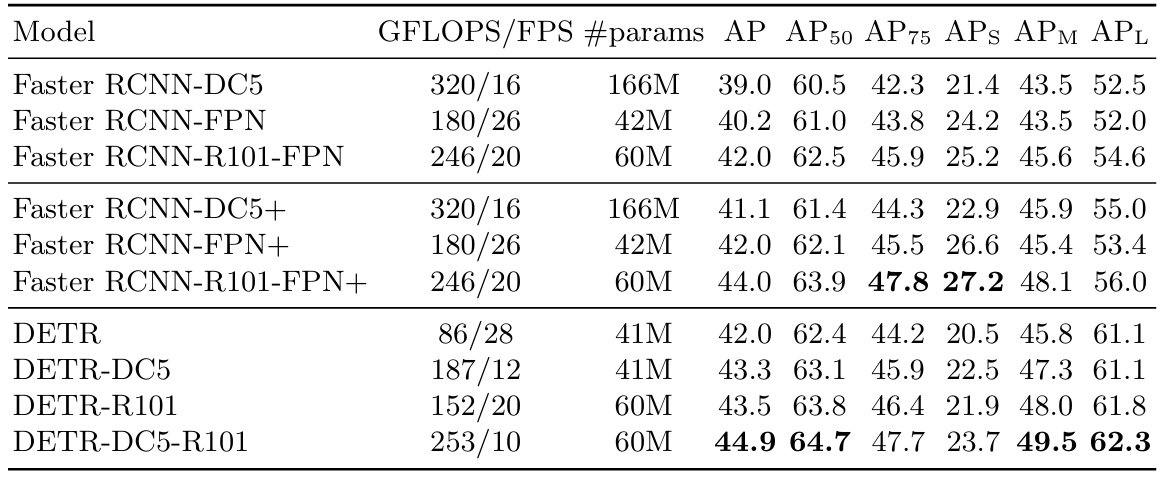
DETR는 전체적으로 Faster R-CNN과 유사한 수준의 성능을 달성함
특히, 작은 객체보다 큰 객체(AP_L)에 강함.
(FPN이나 multi-scale 구조가 없는 DETR의 구조적 특성 때문)
Ablations
DETR에서 핵심적인 역할을 하는 건 Transformer decoder의 attention mechanism임.
:예측 간 관계를 모델링하고, 중복 없이 객체를 구분하게 해줌
다음 요소들이 성능에 어떻게 영향을 미치는지 분석함
- Encoder layer 수
- Decoder layer 수
- Auxiliary loss와 NMS의 역할
- Attention 시각화 분석
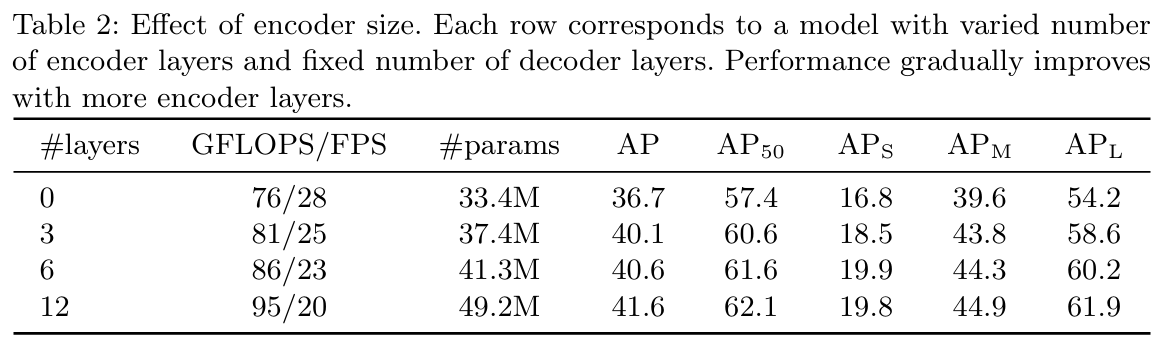
- Encoder를 제거하면 성능이 3.9 AP 하락, 특히 큰 객체(AP_L)는 6.0 하락
- Attention map 시각화 결과: Encoder가 이미 인스턴스 구분을 상당히 수행함
즉, global context 학습이 객체 분리에 핵심적 역할을 함

Decoder attention map을 예측된 객체마다 시각화함
- Attention은 객체의 경계 또는 말단 부분(head, leg 등)에 집중됨
Encoder가 인스턴스를 전체적으로 분리한 상태이기 때문에
Decoder는 세부 정보만 추출하면 됨
→ 전체적으로 Encoder가 "누구냐"를 구분하고,
→ Decoder는 "어디까지냐"를 다듬는 구조라고 볼 수 있음
Analysis
DETR는 고정된 수의 object query (ex. 100개)를 사용함.
→ 각 query는 decoder에서 독립적으로 하나의 객체를 예측함.
실험 결과,
각 query slot은 특정 위치나 box 크기에 특화된 행동 모드(modes)를 보임
ex. 어떤 slot은 상단 영역, 어떤 slot은 좌하단, 어떤 slot은 큰 박스 전용 등
대부분의 slot은 image-wide box 예측 모드를 하나씩 내장함
→ 이미지 중앙을 가로지르는 큰 박스를 자주 예측함 (시각화에서 수평 붉은 점으로 보임)
이건 COCO 데이터셋의 객체 분포 특성과 관련 있는 현상으로 해석됨
→ 즉, DETR는 object query마다 역할 분담(specialization)을 학습함
또한, COCO 학습셋에는 같은 클래스 객체가 다수 등장하는 이미지가 드묾
ex. 기린(giraffe)은 한 이미지에 최대 13마리까지만 등장
이 실험에서는 기린 24마리를 배치한 합성 이미지를 만들어
DETR가 이러한 out-of-distribution 상황에 일반화할 수 있는지 평가함
결과적으로, DETR는 24마리 모두 정확히 탐지함
-> query slot들이 클래스에 특화되지 않고 역할 유연성이 있음을 확인함
DETR는 단순히 "slot 1 = 고양이", "slot 2 = 사람"처럼 학습하는 것이 아님
→ 대신 query들은 공간적 영역, 크기, 위치 패턴에 기반해 역할을 자율적으로 나눈다는 것.
DETR for panoptic segmentation
Mask R-CNN처럼 DETR도 간단한 구조 확장으로 segmentation까지 처리 가능하다...
기존 DETR의 decoder 출력에 mask head만 추가함.
각 object query embedding을 활용하여 binary mask 예측 수행
과정
1. confidence < 85%인 예측 제거
2. 남은 마스크 중, pixel-wise argmax를 통해 pixel 단위 마스크 결정
3. 같은 stuff category의 마스크는 하나로 병합
4. 너무 작은 마스크(< 4 pixel)는 제거
이 방식은 마스크 간 중첩이 없음
→ 기존 방법에서 필요한 중첩 조정 휴리스틱 불필요
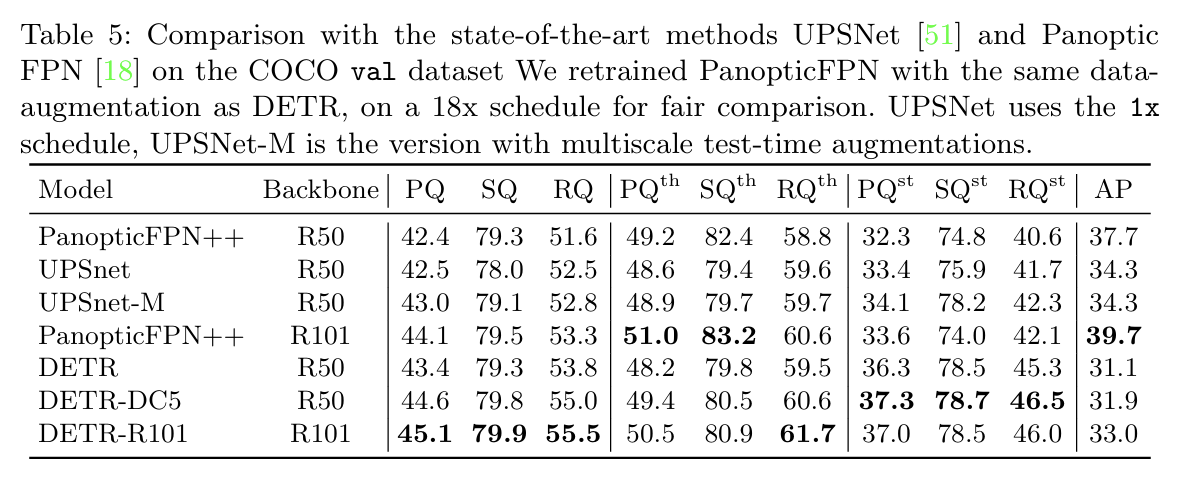
- 구조적으로 thing/stuff 클래스를 구분하지 않고 통합된 방식 사용
- 기존 방법처럼 복잡한 post-processing 없이도 경쟁력 있는 성능 달성
특히 stuff 영역에서 강력한 성능을 보이며, Transformer encoder의 전역 reasoning 능력이 강점으로 작용
“완전히 통합된 객체+배경 예측 모델”로 가는 방향을 제시!
🔚5. Conclusions
DETR는 객체 탐지(object detection)를 완전히 새로운 방식으로 정의함.
Transformer + Bipartite Matching Loss → 직접적인 Set 예측 방식
- 기존 방식은 anchor, NMS, proposal 등 복잡한 후처리와 구조적 제약에 의존
DETR는 이를 제거하고, 단순하고 깔끔한 end-to-end 구조를 제안
- 단순한 구현 구조
: CNN + Transformer만 있으면 수십 줄로 구현 가능 - 큰 객체에서 강한 성능
: Global attention 덕분에 large object 인식에 뛰어남 - Panoptic Segmentation 확장도 자연스러움
: 마스크 헤드만 추가하면 통합된 segmentation까지 가능
다만, 학습 시간 길고 최적화 어려움.
작은 객체(small object) 성능도 약하고, 기존 detector들이 수년간 개선을 거친 만큼, DETR도 후속 연구 필요함.
