Paper: Emerging Properties in Self-Supervised Vision Transformers
🔍1. Introduction
ViT(Vision Transformer): 최근 CNN을 대체할 수 있는 대안으로 주목받고 있음.
NLP 분야처럼 대규모 사전학습(pretraining)과 파인튜닝(finetuning)을 통해 이미지 분류에서 경쟁력 있는 성능을 보임.
하지만 여전히 명확한 장점은 존재X.
Why?
연산량이 많고, 더 많은 학습 데이터가 필요하며, 학습된 피처에 뚜렷한 특성이 없음.
=> 본 논문
"왜 ViT는 NLP처럼 강력한 self-supervised 결과를 못 내는가?"라는 질문을 던짐.
NLP에서는 BERT나 GPT처럼 문장 내 단어 간 관계를 활용한 self-supervised 학습이 핵심이었음.
이 방식은 단일 라벨을 예측하는 supervised 방식보다 더 풍부한 학습 시그널을 제공함.
반면, 이미지에서는 이미지 하나를 단일 object category로만 학습시키는 한계 존재O.
=> ConvNet 기반 self-supervised 방법들을 참고해 ViT에 적용해봄.
그 결과 supervised ViT나 ConvNet에서는 안 보이던 특성들이 등장함.
어떤 특성?
self-supervised ViT는 scene layout과 object 경계가 self-attention에서 자연스럽게 드러남.
학습된 feature를 단순히 k-NN으로 분류해도 ImageNet top-1 정확도 78.3% 달성함.
(momentum encoder + multi-crop augmentation을 같이 써야만 나옴.)
ViT에서 작은 patch size(8×8 등)를 사용할수록 feature 품질이 더 좋음.

이런 발견들을 통해 저자들은 DINO라는 프레임워크를 제안함.
1) 라벨 없이 teacher의 출력을 student가 예측하게 하는 구조
2) loss는 단순 cross-entropy, teacher는 EMA(momentum encoder) 방식으로 업데이트
3) collapse 방지는 centering + sharpening 만으로 해결
중요한 점은, predictor나 contrastive loss 없이도 학습이 잘 된다는 것.
: BYOL이나 SimCLR에서 필요했던 복잡한 구성 없이 가능함
: ConvNet, ViT 모두 적용 가능하고 normalization도 따로 조정할 필요 없음
ViT-Base(작은 패치 사용) 기준 80.1% linear 성능,
ResNet-50 기반에서도 SoTA 수준 성능 도달함.
자원도 적게 듦 -> 8-GPU 3일이면 학습 가능.
결론적으로 DINO는 self-supervised ViT 학습의 새로운 가능성을 제시한 방식.
간단하지만 강력하고, 실제로 "emergent property"를 이끌어냄.
✅2. Related work
Self-Supervised Learning (SSL)
초기 SSL 연구는 대부분 discriminative 방식 기반.
: 각 이미지를 서로 다른 class로 간주하고, 데이터 증강을 통해 구분하도록 학습시키는 방식(instance classification).
(대표적으로 MoCo, SimCLR, CPC 등이 여기에 해당)
문제는 이 방식이 이미지 수가 많아질수록 확장성이 떨어진다는 것.
: 모든 이미지를 동시에 구분하려면 batch size가 커야 함...
이를 해결하기 위해 memory bank나 contrastive loss 기반 접근이 사용됨.
그래서 최근에는 이미지를 서로 구분하지 않고 학습하는 방법이 등장함.
- 대표적으로 BYOL: teacher의 피처를 student가 모방하게끔 학습
: contrastive loss 없이도 학습이 잘 된다는 점
: momentum encoder 없이도 작동은 하지만, 성능은 하락
본 논문에서 DINO는 BYOL에서 아이디어를 가져오되,
student와 teacher 아키텍처를 완전히 동일하게 사용하고
loss function은 cross-entropy 기반의 다른 방식으로 구성됨
=> self-distillation 관점에서 봤을 때, 라벨 없는 Mean Teacher 구조로 해석 가능.
Self-Training & Knowledge Distillation
Self-training은 원래 라벨이 적은 상황에서 시작해서, 예측 결과를 기반으로 unlabeled 데이터를 점점 pseudo-label로 학습시키는 방식임.
hard label 방식도 있고, soft label 기반으로 확장되면 knowledge distillation으로 이어짐.
Distillation은 원래 작은 모델이 큰 모델을 모방하게 하는 모델 압축 방식이었는데,
최근에는 soft pseudo-label을 unlabeled 데이터에 전파하는 self-training 파이프라인으로도 활용됨
이때 DINO는 더 나아가서!
아예 처음부터 라벨이 없는 상태에서의 distillation을 실현함.
: 기존 방법들처럼 pre-trained teacher를 쓰는 게 아니라,
학습 도중에 momentum 기반으로 teacher를 업데이트하면서 self-supervised objective로 distillation을 진행함
이때 중요한 건!
DINO는 distillation을 단순한 후처리가 아니라 학습 자체의 목적(objective)으로 사용함.
: codistillation과도 유사하지만, DINO는 teacher가 student 출력을 참조하지 않음
대신, teacher는 student의 moving average로 업데이트됨
∴
기존 SSL
- contrastive 방식에서 시작
- 최근 비대조 학습 방식(BYOL류)이 주류로 부상함
DINO
self-distillation 구조 + momentum teacher를 결합한 형태
기존 knowledge distillation과 달리, 라벨 없이 distillation을 학습 목적 자체로 활용
teacher가 학습 중에 생성된다는 점, 그리고 student와 구조가 완전히 동일하다는 것이 특징
✅3. Approach
3.1 SSL with Knowledge Distillation
DINO
:기존 SSL 구조(BYOL, SimCLR, SwAV 등)와
knowledge distillation 을 결합한 프레임 워크
핵심
: student 네트워크가 teacher 네트워크의 출력을 예측하게끔 학습
즉, 라벨 없이도 soft target을 이용한 self-distillation 구조
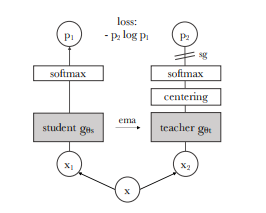
입력 이미지 x에 대해, student g_s(x), teacher g_t(x)가 각각 K차원 확률 분포 P_s, P_t를 출력함.
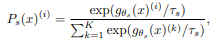
< Student softmax >
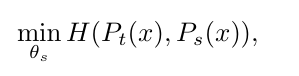
< Loss >
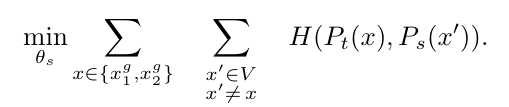
< 전체 view 조합에 대한 loss >
Teacher network
고정된 pre-trained teacher가 아니라, Student의 EMA(지수이동평균)으로 Teacher를 동적으로 업데이트:
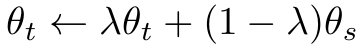
- λ: cosine 스케줄(0.996 → 1.0까지 증가)
- 기존 contrastive 방식의 queue 없이도 안정적인 학습 가능
Network architecture
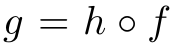
- f: Backbone (ViT or ResNet)
- h: Projection Head (3-layer MLP + L2정규화 + weight norm FC)
- ViT의 경우 BN 사용 안 하므로 projection head도 BN-free.
Avoiding collapse
Centering + Sharpening 기법으로 collapse 방지
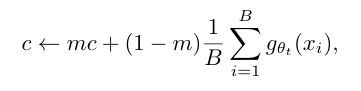
- Centering: Teacher 출력을 평균 중심으로 정규화 (EMA 기반)
- Sharpening: Teacher softmax 온도를 낮춰서 분포를 날카롭게 만듦
- Contrastive loss, BN, predictor 없이도 collapse 방지 가능.
결론적으로,
- Pretext task 없이, 라벨 없이도 강력한 표현 학습 가능
- Teacher를 Student의 EMA로 구성해 안정성과 성능 향상
- 다양한 view 조합 및 BN-free 설계로 실용성과 확장성 우수
3.2. Implementation and evaluation protocols
ViT
- DINO는 ViT(Vision Transformer) 아키텍처 기반으로 학습 진행
- 입력 이미지를 비중첩(non-overlapping) 패치로 나눔 (보통 16×16 또는 8×8 크기)
- 각 패치는 linear projection을 통해 embedding으로 변환됨
- 여기에 learnable class token([CLS])을 추가해서 전체 시퀀스 정보를 통합
- 이 [CLS] 토큰의 출력을 projection head에 연결해 feature를 생성함
->실제 라벨이 없는 SSL에서는 [CLS]는 학습 목적일 뿐, label과 연결되진 않음 - Transformer는 pre-norm 구조의 self-attention + feed-forward layer로 구성됨
Implementation Details
- Pretraining 데이터: 라벨 없이 ImageNet 전체 데이터 사용
- Batch size: 1024
- Learning rate: Linear scaling rule 적용
- Learning rate schedule: 10 epoch 동안 warm-up ->이후 cosine decay
- Weight decay: 0.04 → 0.4로 cosine 스케줄 적용
- Softmax temperature:
Student: 고정값 0.1
Teacher: 0.04에서 0.07까지 30 epoch 동안 선형 warm-up - Augmentation: BYOL 방식
- Positional Embedding: 해상도 변경 대응 위해 bicubic interpolation 사용
Evaluation protocols
1) Linear Evaluation (선형 분류기)
Freeze된 feature 위에 선형 분류기 학습
2) Finetuning
pretrained 모델 전체를 downstream task에 맞게 학습
3) k-NN 기반 평가 (Weighted k-Nearest Neighbor)
하이퍼파라미터 없이 빠르고 간단한 성능 측정 -> 20-NN이 best
✅4. Main Results
4.1. Comparing with SSL frameworks on ImageNet
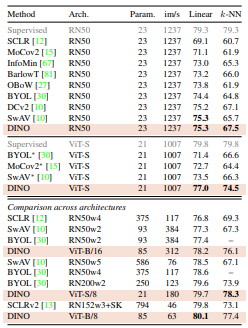
1) 동일한 아키텍처(ResNet-50, ViT-S)를 사용하는 기존 방법들과 비교
ResNet-50 기준: DINO는 BYOL, MoCoV2, SwAV 등 다른 대표 SSL 프레임워크들과 동급 수준의 성능을 보이며, 기존 방식들과 동일한 조건에서 안정적으로 동작함을 보여줌.
ViT-Small 기준:
ViT-S와 ResNet-50: parameter 수(21M vs 23M), 연산량, supervised accuracy에서 유사.
DINO는 ViT-S에 적용했을 때 다른 SSL보다 압도적인 성능 향상을 보임:
-Linear classifier 기준 +3.5% 향상
-k-NN 평가 기준 +7.9% 향상
특히 k-NN 성능이 거의 Linear 수준에 근접한다는 점.
일반적으로 k-NN은 linear보다 성능 낮은데, DINO + ViT에서는 둘이 유사
-> feature quality가 매우 높음을 의미
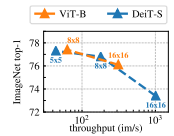
2) 다양한 ViT 아키텍처 규모 변화에 따른 성능 분석 (cross-architecture)
ViT 구조를 더 크고 복잡하게 만들수록 성능이 상승함은 명확.
단, 단순히 파라미터를 늘리는 것보다 patch size를 줄이는 것(예: ViT-S/16 → ViT-S/8)이 더 큰 성능 향상을 줌.
patch size 작아지면 더 fine-grained한 spatial 정보 확보 가능.
결론
: 모델 크기를 키우는 것보다 patch size를 줄이는 것이 더 효과적
결국 DINO는 비교적 작은 ViT 구조로도, 효율성과 성능을 동시에 확보하는 self-supervised 학습 가능성을 증명함.
4.2. Properties of ViT trained with SSL
DINO로 학습된 Vision Transformer(ViT)가 정확도 뿐 아니라, 특징 추출 측면에서도 강력한 표현력을 가지는지 확인
4.2.1 Nearest neighbor retrieval with DINO ViT
Self-supervised feature가 유사 이미지 검색(retrieval)이나 복사본 탐지(copy detection) 같은 유사도 기반 태스크에 강한지 평가
A)Image Retrieval
- feature를 freeze 시키고, k-NN 기반으로 Mean Average Precision (mAP) 평가
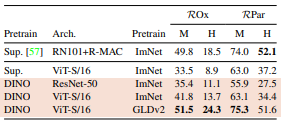
결과적으로,
- DINO로 학습된 ViT feature가 supervised 모델보다 높은 mAP 달성
- 특히 GLDv2 (Google Landmarks v2)에서 학습한 DINO는, 오히려 일반 supervised보다 landmark에 더 강한 표현력 보임
- Annotation 없이 학습했음에도 retrieval 전용 feature보다 강력한 성능
B)Copy Detection
[CLS] 토큰 + patch 토큰 pooled → 1536-d feature 구성 → cosine similarity + whitening 적용
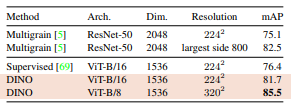
결과적으로,
- 기존 copy detection 방법보다 경쟁력 있는 성능 확보
- 전처리 없이 feature 자체만으로 강건한 표현력 보여줌
4.2.2 Discovering the semantic layout of scenes
ViT의 self-attention map이 장면의 semantic 구조를 이해할 수 있는지 (segmentation 수준 정보 포함 여부)

A)Video Instance Segmentation
영상 내 연속 프레임 간 patch token 기반 recent neighbor 매칭으로 segmentation (fine-tune 없이 사용)
결과적으로,
- ViT 구조는 dense prediction용이 아님에도 의외로 의미 있는 성능 달성
- 특히 patch size가 작은 구조(ViT-B/8)에서 +9.1% (J&F)m 성능 향상
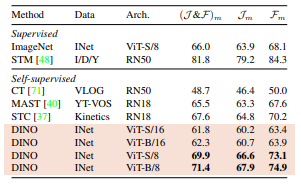
B)Self-Attention map

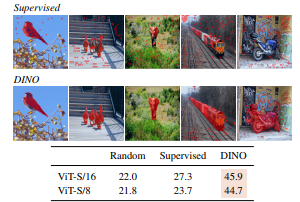
결과적으로,
- Attention head별로 서로 다른 object 영역에 집중
- Supervised ViT와 비교해 DINO는 object 중심 attention 분포가 더 명확
- Jaccard 유사도(Jaccard similarity) 평가에서도 DINO가 supervised보다 월등
4.2.3 Transfer learning on downstream tasks
DINO로 사전학습된 feature가 다양한 downstream task에 잘 전이되는지
비교 대상: 동일한 ViT 구조 + supervised ImageNet 학습 feature
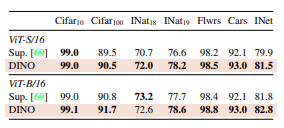
결과적으로,
- ViT 구조에서는 self-supervised(DINO)가 supervised보다 consistently 더 좋은 전이 성능을 보임
- ImageNet에서도 +1~2% 수준의 성능 향상
- ConvNet에서도 관찰됐던 self-supervised의 전이학습 장점이 ViT에도 동일하게 유효
✅5. Ablation Study of DINO
5.1. Importance of the Different Components
DINO를 구성하는 주요 컴포넌트들에 대해 하나씩 제거하거나 추가하면서, 각 요소가 학습 성능에 어떤 영향을 미치는지 실험.
결론적으로,
- DINO에서 가장 중요한 요소는 momentum encoder + cross-entropy loss + multi-crop training
- BYOL에서 필수였던 predictor는 DINO에서는 그다지 중요하지 않음 → DINO는 보다 안정적인 구조
5.2. Impact of the choice of Teacher Network
DINO는 self-distillation 기반의 프레임워크인데, 여기서 핵심은 student가 teacher의 출력을 따라가며 학습한다는 점임.
근데 이때 “teacher를 어떻게 만들 것인가?”는 성능에 꽤 중요한 영향을 줄 수 있음.
=> 이 실험에서는 다양한 teacher 생성 전략을 비교 분석
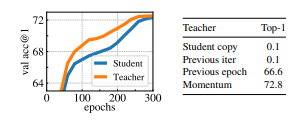
결과적으로, momentum teacher가 가장 안정적이고 성능도 뛰어남
다만 이전 epoch 기반 teacher도 collapse는 안 하고, ㄱㅊ은 수준의 성능을 보여줌 -> teacher 설계 대안 가능성 있음.
그리고 momentum teacher가 왜 잘 작동하는지를 학습 중 동적 변화 관찰을 통해 분석함.
DINO의 momentum teacher는 단순한 EMA가 아님. 일종의 Polyak-Ruppert Averaging*으로 해석 가능.
* Polyak-Ruppert Averaging
원래는 훈련 마지막에 여러 모델을 평균내어 성능을 올리는 기법임
근데 DINO에서는 훈련 내내 평균 모델을 유지하고, 이걸 guidance 역할의 teacher로 활용함
이게 지속적인 ensemble 효과를 갖는 self-distillation이 되어버림
5.3. Avoiding collapse
Self-supervised learning에서의 collapse:
1)Uniform collapse
출력 분포가 모든 차원에서 거의 동일 (정보가 없음)
2)Mode collapse
출력이 특정 차원 하나에 몰림 (한 feature만 활성화됨)
이런 collapse가 일어나면 모델은 아무리 많은 데이터를 줘도 의미 있는 표현을 학습하지 못함.
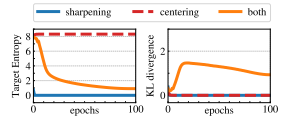
=>Centering + Sharpening
Centering
: teacher의 출력을 평균 중심으로 정렬해줌
-특정 차원에 몰리는 mode collapse 방지
-단, 출력을 너무 평탄하게(uniform) 만들어버릴 수 있음
Sharpening:
: 출력 분포를 더 sharp하게 만들어줌 (즉, confidence 높임)
-uniform collapse 방지
-단, 특정 차원만 살아남을 위험 있음
그래서 DINO는 둘을 같이 씀, 즉 서로 상호보완적으로 작용하게 함
5.4. Compute requirements
DINO가 Vision Transformer에서 멀티 크롭 학습 방식(multicrop training)을 통해 학습 속도와 정확도 간 효율적인 trade-off를 달성할 수 있는지 평가
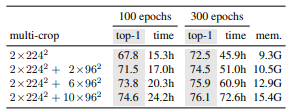
결과적으로,
멀티크롭(multicrop)을 쓰면, 학습 시간은 절반인데 정확도는 오히려 더 좋아짐.
즉, 더 짧은 시간에, 더 높은 정확도를, 상대적으로 적은 리소스로 달성 가능함.
5.5. Training with small batches
DINO가 소규모 batch size 환경에서도 안정적으로 학습 가능한지를 실험

결과적으로,
batch size가 작아질수록 정확도는 떨어지지만, 여전히 학습은 수렴 가능
🔚6. Conclusion
Vision Transformer(ViT) 모델을 기반으로 한 self-supervised 학습 프레임워크 DINO를 제안했음.
DINO는 사전 정의된 라벨 없이도 ViT를 효과적으로 사전학습할 수 있음
-> 성능은 label 기반 학습된 최상급 convnets와 유사한 수준까지 도달함
특히 ViT에 self-supervised 방식을 적용했을 때
1) k-NN classification 성능이 매우 높음
: ViT 기반의 이미지 검색 시스템(image retrieval)에 바로 활용 가능함
2) scene layout 정보(객체 경계, 구조 등)가 feature 안에 내재
: 약지도(weakly-supervised) semantic segmentation 같은 downstream task에 유리함
중요한 점은,
elf-supervised 방식이 BERT처럼 범용적인 비전 백본을 만드는 열쇠가 될 수 있다는 가능성을 보여줬다는 것임
: NLP의 BERT처럼, label 없이도 강력한 표현을 갖는 시각 모델이 충분히 가능하다는 점을 실험적으로 입증
실제로, 이 모델은 downstream fine-tuning 없이도 의미 있는 성능을 보이고 있으며, 추론 속도나 아키텍처 제한 없이도 폭넓게 적용 가능하다는 장점 존재.
