유사 화장품 추천 프로젝트
자카드 계수 🌗🌑🌓
📝 목차
- 자카드 계수 소개
1-1. 기대효과- 유사도 측정
- 결과
1. 자카드 계수 소개
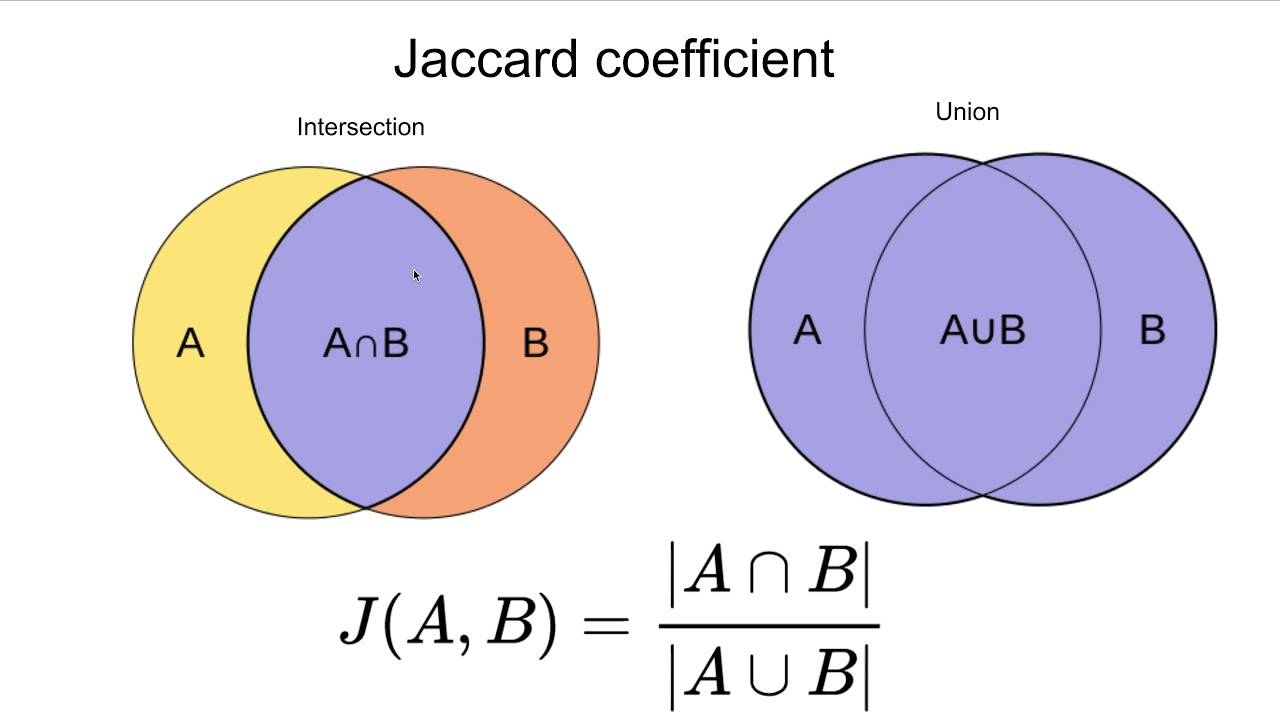
자카드 지수(Jaccard index)는 두 집합 사이의 유사도를 측정하는 방법 중 하나이다. 자카드 계수(Jaccard coefficient) 또는 자카드 유사도(Jaccard similarity)라고도 한다. 자카드 지수는 0과 1 사이의 값을 가지며, 두 집합이 동일하면 1의 값을 가지고, 공통의 원소가 하나도 없으면 0의 값을 가진다. 자카드 지수는 아래의 식으로 정의된다.
1-1. 기대 효과
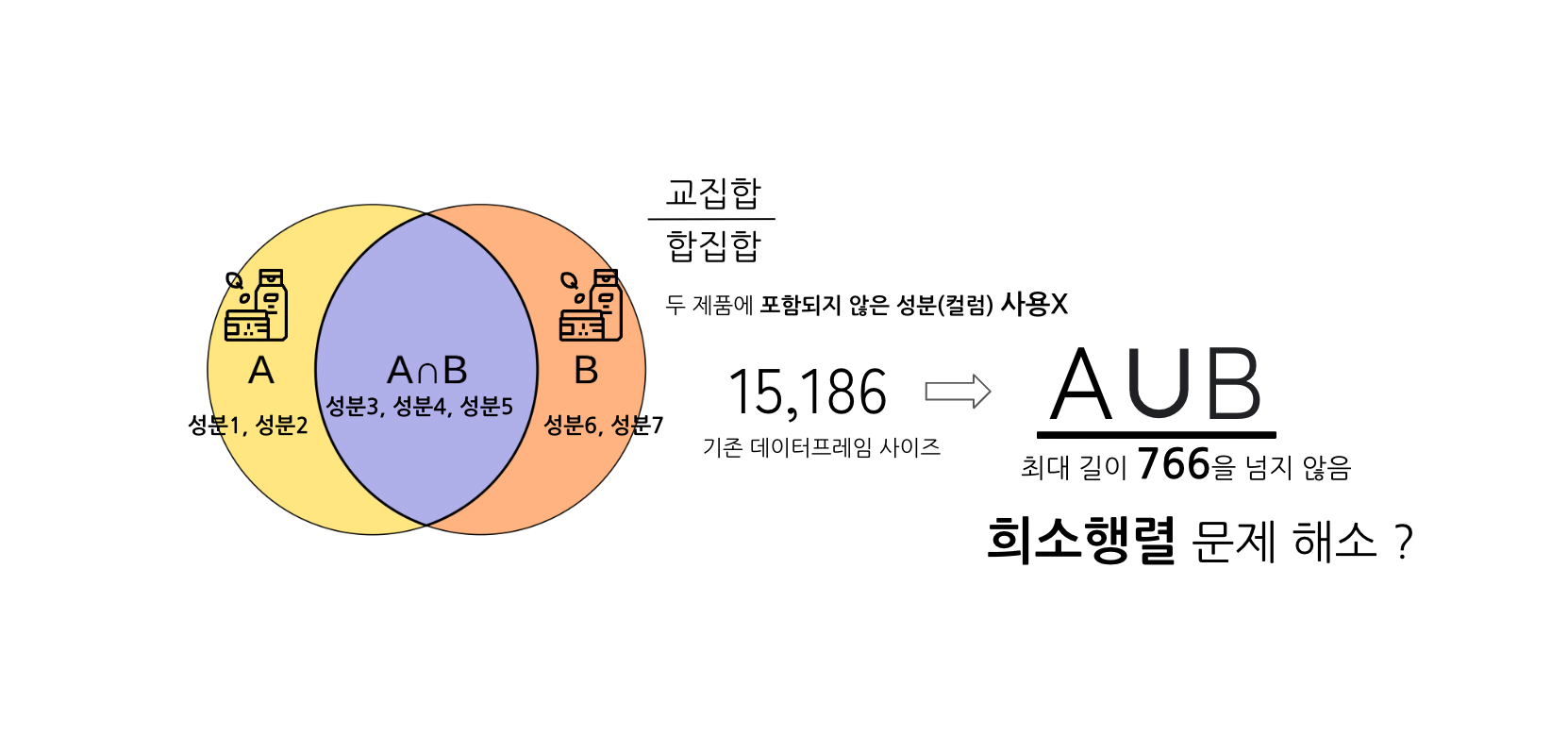
이전 유사도 측정에서 문제가 됐던 점은 데이터프레임의 사이즈(희소행렬)
- 로컬 리소스 대비 비대한 데이터프레임의 사이즈
- 리소스 낭비
- 유사도 측정 연산 수행시간 과도하게 오래걸림
자카드 계수를 사용하면?
비교 대상에 쓰인 두 제품에 포함되지 않은 성분은 연산에 사용되지 않는다.
본 프로젝트에서는 다음과 같이 적용된다.
2. 유사도 측정
특정 화장품에 어떤 성분이 들어있는지를 표시한 테이블을 활용하여, 전성분표와 같이 특정 화장품에 포함된 성분들로 구성된 세트를 추출
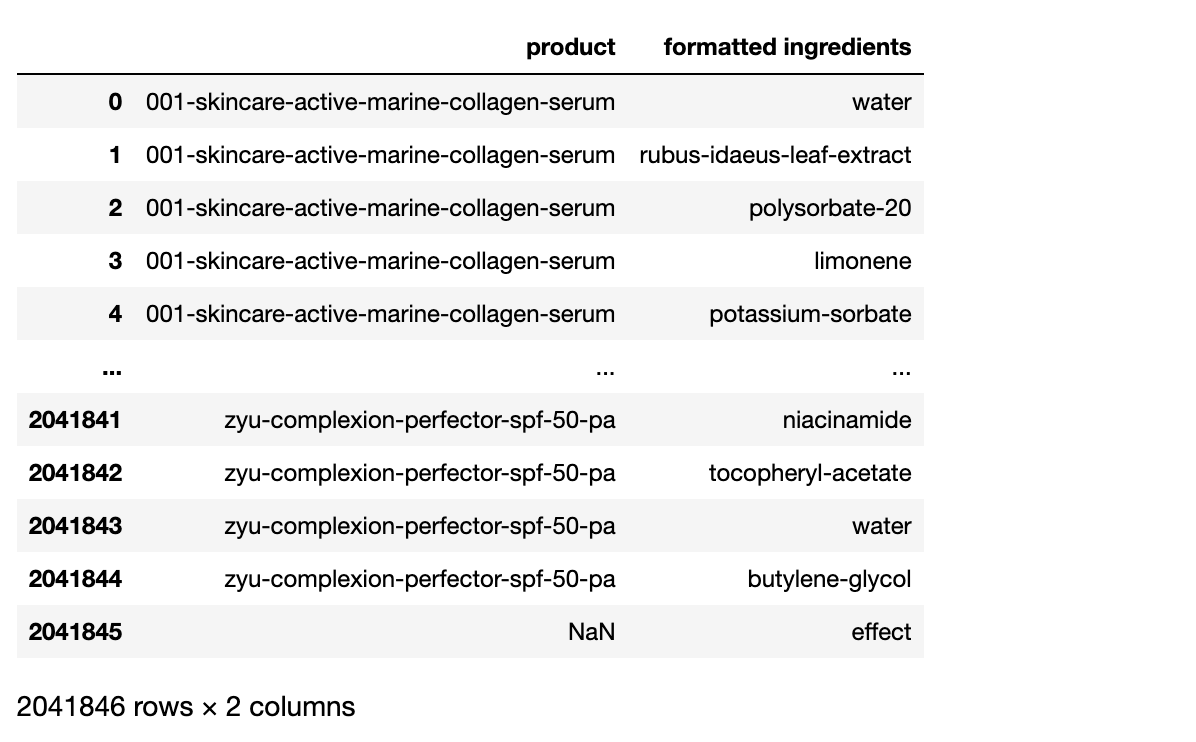
데이터베이스 내 모든 화장품에 대한 세트를 추출한 후,
하나의 화장품(base_name)에 대해서 루프를 돌면서 모든 Pair에 대한 자카드 유사도 측정
base_name = 'cover-fx-natural-finish-foundation'
# 첫 번째 화장품(비교 기준)
base = dual_list[dual_list['product'] == base_name]
ings1 = set(base['formatted ingredients'])
# 기준이 될 데이터프레임 만들기
main_prod = pd.DataFrame(columns = {'product','jacc_ing','jacc_eff','jacc_sum','jacc_mult'})
sub_prod=[]
for j in tq(range(len(items_list))):
if base_name == items_list[j]:
continue
# 두 번째 화장품(비교 대상)
comp = dual_list[dual_list['product']==items_list[j]]
ings2 = set(comp['formatted ingredients'])
# 자카드 첫 번째
jacc_1 = len(ings1&ings2)/len(ings1|ings2)
a_raw = ings1 - ings2
# 세트 버전으로 만들기 : 중복 있는 버전은 너무 번거로움
# ingredient 말고 effect를 통해 중복 감정
a_list = set()
while a_raw:
try:
eff = effect_list.loc[a_raw.pop(), 'what-it-does']
for m in eff.split(','):
m = m.replace('[','').replace(']','').replace("\'",'').strip()
a_list.add(m)
except:
continue
b_raw = ings2 - ings1
b_list = set()
while b_raw:
try:
eff = effect_list.loc[b_raw.pop(), 'what-it-does']
for n in eff.split(','):
n = n.replace('[','').replace(']','').replace("\'",'').strip()
b_list.add(n)
except:
continue
# 자카드 두 번째 : effect 기반
jacc_2 = len(a_list&b_list)/len(a_list|b_list)
jacc_total = jacc_1 + jacc_2
jacc_weighted = jacc_1 * jacc_2
# 데이터프레임에 데이터 더하기
sub_prod.append([items_list[j],jacc_1, jacc_2, jacc_total, jacc_weighted])
main_prod = pd.DataFrame(sub_prod, columns={'product','jacc_ing','jacc_eff','jacc_sum','jacc_mult'})📌 코드 부연 설명
-
자카드 유사도를 구할 땐, intersection과 union을 구한 후 전자를 후자로 나누었다. (100을 곱하는 과정은 생략)
-
다음으로는 두 제품의 전성분표에서 intersection에 포함되는 성분들을 제외한 후, 남아있는 성분들을 모두 effect로 치환
-
여기서는 기존에 성분들과 그에 상응하는 효과들로 구성된 테이블을 활용했다. Effect로 치환한 후 세트 처리하여 중복을 제거한 이후, 위에서와 같이 intersection, union을 구해 전자를 후자로 나누어 주었음.
Effect에 대해서 자카드 유사도를 다시 구해준 것 -
마지막으로는 성분에 대한 자카드 유사도, 나머지 성분의 효과에 대한 자카드 유사도를 더한 값, 그리고 곱한 값을 구했다. 일종의 가중 자카드 유사도
결과
Good Case

Count-Based Matrix의 유사도 테스트 때 사용한 제품을 동일하게 사용했음.
같은 Peel-off Mask는 아니었지만, 성분 면에서 모두 일치하는 결과값을 도출
Bad Case

반면, Foundation 제품과 유사한 제품을 Cleansing Oil이라고 도출하는 부적절한 케이스도 다수 존재했음.
특히 성분 면에서 공통으로 4개만을 함하고 있음.
📌 결론
1. 희소행렬로 인한 과도한 연산 수행시간을 줄이고자 했던 시도였지만? 제품 하나의 연산을 수행하는데 20분이 소요됨. 77,000(전체 제품 수) X 20m .. ?
2. 성분이 나열된 순서를 고려하지 못함. 이로 인해 부적절한 케이스가 나왔다고 생각
3. 희소행렬 문제, 성분 순서 고려를 모두 해결할 수 있는 방안은 ..?
