최근 llm을 이용한 recsys에 관심이 생겨 본격적으로 논문을 읽어보기 전에 survey paper로 현재 동향 및 역사를 읽어보고 전체적인 구조를 파악하고자 한다.
Introduction
llm을 추천에 이용하는 주요 이점은 아래와 같다
- 텍스트 특성의 고품질 표현 추출
- llm이 가지고 있는 방대한 지식 활용 가능성
기존의 추천시스템과 차이점
1. llm 기반 모델은 문맥 정보를 포착가능, 사용자 쿼리, 아이템 설명, 기타 텍스트 데이터를 더 효과적으로 이해 가능
--> llm 기반 추천은 accuracy와 relevance를 개선함.
- data sparsity problem -> zero shot/few shot 기법을 통하여 해결하고 있다.
--> 사전 학습의 데이터가 워낙 많다보니, 사실 정보, 도메인 전문 지식, 상식 추론 능력이 내포되어 특정 아이템이나 사용자에 대한 사전 정보가 없이도 합리적인 추천을 생성할 음수 있음.
---> discriminative model에서 잘 활용 되고 있음
그런데 패러다임이 generative model에 초점이 맞춰지고 있음
ex) Chat GPT
생성 모델과 추천 시스템의 결합이 새로운 국면을 찾아줌
ex1) 언어 생성 능력을 활용해 추천의 근거를 설명함으로써 추천 결과의 해석 가능성을 개선할 수 있음
2) 사용자 맞춤형 프롬프트를 활용한 대화형 추천 시스템을 통해 더 개인화되고 상황 인식된 추천을 제공할 수 있음
-> 사용자 참여도 및 만족도 높아짐
본 논문의 contribution은 다음과 같음
- 추천 분야에서 llm의 적용을 확장하기 위한 시스템적 서베이 제공
- 세 가지 모델링 패러다임으로 분류하여 구조화된 관점 제시
- 기존 방법들의 장단점 및 한계 분석, 향후 연구 방향 제안
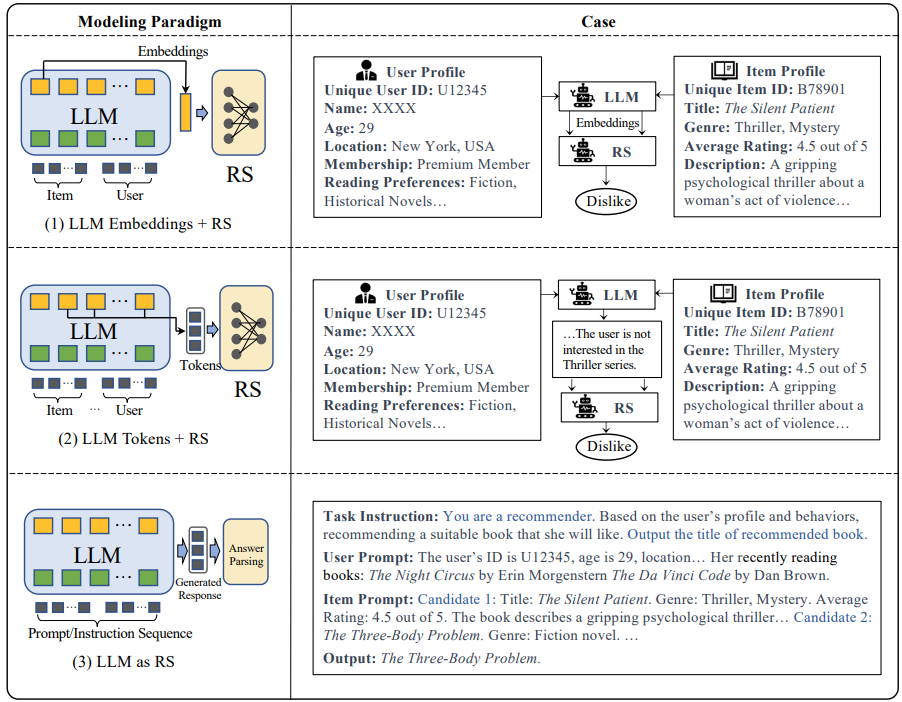
Modeling Paradigms
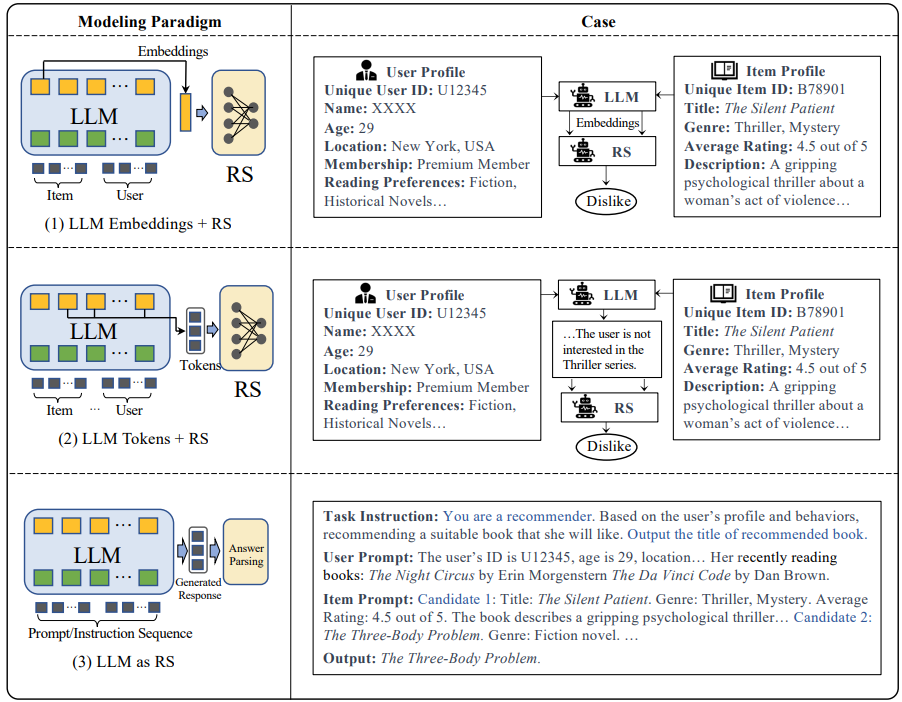
본 논문에서는 모델링 패러다임을 3가지로 구분한다.
- LLM Embeddings + RS
- LLM Tokens + RS
- LLM as RS
또한 본 논문에서는 LLM의 유형별 분류를 두 가지로 정의한다.
- Discriminative LLMs
- Generative LLMs
또한 본 논문에서는 학습 방식에 따른 세부 분류로 4 가지로 구분한다.
1. Fine-tuning
2. Prompting (In-context Learning)
3. Prompt Tuning
4. Instruction Tuning
1. LLM Embeddings + RS
- LLM Embeddings + RS의 방식은 LLM을 feature extractor로 단순히 사용하는 것임.
- 사용자 및 아이템의 텍스트 입력을 임베딩으로 변환함. -> 생성된 임베딩은 기존의 추천 모델 (FM, GCN 등)에 입력되어 추천 결과를 출력함
구조
텍스트 데이터 (e.g. 리뷰, 타이틀)
↓
사전학습된 LLM → 임베딩
↓
추천 모델 (CTR 예측 등)
장점
- 기존 RS 파이프라인에 쉽게 통합 가능하며 유연함
- LLM을 통해 텍스트 표현의 풍부한 의미적 정보는 임베딩으로 반영 가능
- 특히 도메인 지식을 잘 반영할 수 있어 context-aware 추천에 유리함
단점
- LLM이 단지 임베딩만 제공 -> 추천에 직접적 영향 X
- 결과 해석력이 낮고, 설명 기반 추천이 어려움
- 프롬프트 기반 인터페이스나 멀티턴 대화 지원에 한계가 있음
2. LLM Tokens + RS
- llm을 사용하여 사용자 및 아이템에 대한 설명가능한 텍스트 토큰 (e.g. 설명, 키워드)를 생성
- 생성된 텍스트는 선호도 정보 추출에 활용, 이후 추천 결정에 통합
- LLM이 직접 추천은 하지 않지만, 텍스트를 통해 의미적 정보 및 신호를 제공
구조
입력 (ex. 사용자 정보 + 쿼리)
↓
LLM이 텍스트 토큰 생성 (e.g. user representation, item caption)
↓
토큰 내 정보 추출 → 추천 모델 사용
장점
- 유저/아이템의 의미 기반 표현이 가능 -> 다양한 선호, 의도 반영 가능
- 사용자 쿼리나 리뷰 기반 텍스트 인터페이스와의 통합이 수월
- 프롬프트 조작을 통한 다양한 task에 대응 가능 (멀티태스킹 가능)
단점
- 생성된 텍스트의 일관성과 품질 보장 어려움
- 비정형 텍스트를 구조화해 추천 모델에 활용하는 과정이 복잡할 수 있음
LLM as RS
- LLM 자체가 추천 시스템 역할을 수행
- 입력으로 프로필, 행동 로그, 태스트 명령어 등을 받아서 LLM이 직접 추천 결과를 생성
- 완전한 End2end 추천 시스템 구조
구조
입력: 사용자 쿼리, 대화 이력, 선호, 명령어 등
↓
프롬프트 기반 LLM
↓
출력: 추천 결과 (e.g., 영화 목록, 제품 이름 등)
장점
- 매우 유연한 입력 및 출력 포맷 -> 다양한 task 적용 가능
- 자연어 기반의 대화형 인터페이스, 설명 가능 추천에 매우 적합
- 프롬프트를 조작하여 제로샷/퓨샷 추천이 가능함 -> Cold-start problem에 강함
- 도메인 전이, 이유 설명, 사용자 맞춤형 대응 등에서 높은 확장성
단점
- 추천 결과가 일관되지 않거나 신뢰성 낮을 수 있음
- 실제 추천 시스템처럼 ranking 이나 filtering이 어렵거나 부정확할 수 있음
- Inference 비용이 큼 (속도, 리소스)
LLM의 유형별 분류
1. Discriminative LLMs (판별형 LLM)
- 입력 텍스트(e.g. 사용자 리뷰, 프로필 등)에 대해 라벨이나 점수와 같은 결과 예측
- 주요 목적: 이진 분류, 순위 예측, 유사도 계산
- 일반적으로 BERT, RoBERTa, DeBERTa 등의 encoder-only 구조 사용
- 사용방식: 임베딩 추출 -> 기존 추천 모델에 입력
- NLU 중심
- Fine-tuning이나 Prompt tuning을 통해 추천 시스템에 적용
e.g.) 사용자 리뷰 -> BERT -> 사용자 임베딩 -> RS 모델 입력
장점
- 빠르고 정확한 예측 가능
- 기존 RS 구조와 통합에 용이함
단점 - 생성 기능 X --> 설명 불가능
- 입력 구조에 제한 있음
2. Generative LLMs (생성형 LLM)
- 목적: 입력 텍스트로부터 자연어로 직접 결과를 생성 (예: 추천 아이템, 이유, 요약)
- 구조: Decoder-only 또는 Encoder-Decoder
- 사용방식: 자연어 기반 입력 -> 추천 결과 문장 생성
- NLG 중심
- Prompting, In-Context Learning, Instructoin Tuning등 다양한 적용 방식
장점
- 설명 가능성 높음: 이유 포함된 추천 문장 생성 가능
- 유연성 높음 (제로샷/퓨샷/멀티태스크)
- Cold-start 상황에 강함
단점
- 생성 결과 통제 어려움
- 느린 추론, 비용 높음
- 리스트 추천/정확한 랭킹 어려움
Discriminative LLMs for Recommendation
Discriminvative LLMs는 주로 BERT 계열의 encoder-only 모델을 의미함
추천 시스템에서 입력(텍스트)로부터 점수, 라벨, 순위 등의 판별 결과를 추출하는 데 쓰임
추천에서는 사용자/아이템 임베딩, 클릭 예측(CTR), Reranking, sequence modeling에 활용됨
Fine-tuning 기반 방법
PLM을 초기화하고, 추천 태스트 뎅디터셋 (user-item interaction, review, profile)등으로 fine-tuning 함
일반적으로 추천 도메인에 특화된loss로 학습됨
input: 사용자 행동 로그, 아이템 설명, 리뷰
학습대상: 추천 점수 / 랭킹 / 다음 행동 예측 등
장점
- domain adaptive 함
- 문맥 이해 및 복잡한 상호작용 모델링 가능
단점 - 전체 모델 파라미터를 학습함 -> 비용이 큼
- 태스크 별로 재학습 필요함
e.g.
- U-BERT
- UserBERT
- BECR
- BERT4Rec
- UniSRec
Prompt Tuning 기반 방법
LLM은 freeze, 입력에 추가되는 하드/소프트 프롬프트만 학습함
프롬프트는 템플릿 형태로 구성되며 [USER] + [CANDIDATE] + [MASK]등의 구조로 입력됨
장점
- 모델 경량화 <- 파라미터 업데이트 거의 없음
- 다양한 태스크에 전이 학습 가능
- 빠른 도메인 적용
단점
- 프롬프트 자체 설계가 일단 어려움
- Fine-tuning 보다 정확도 떨어질 수 있음
e.g.
- Prompt-BERT4Rec
- dapter Tuning
- Prompt4NR
Generative LLMs for Recommendation
Generative LLM은 주로 GPT, T5, ChatGPT, LLaMA 등 decoder or encoder-decoder 구조를 가진 모델들이고, 자연어 생성 능력을 활용하여 추천 결과 자체를 생성하거나 설명을 생성할 수 있는 것이 특징임
NON-Tuning Paradigm (모델 파라미터 고정)
Prompting
학습없이 프롬프트만 구성해서 LLM의 추천 능력을 유도함
e.g.
Chat GPT 이용 추천 태스크 (평점 예측, 순차 추천, 설명 생성)에 적용
ChatgPT의 ranking 성능을 이용하여 point/pair/list-wise로 평가하고 프롬프트 최적화
Item only / Language Only / Combined 방식 프롬프트 비교
MINT - InstructGPT로 사용자 히스토리를 요약하고 추천 질의 생성
장점
- 빠르고 비용 적음, 다양한 태스크에 대응 가능
- Cold-start에 유리 (도메인 지식 내장)
단점
- 결과 일관성/정확도 낮음
- 성능이 전통 모델보다 떨어지는 경우 많음
In-context Learing
e.g.
입력 시퀀스를 prefix + 후속 행동 쌍으로 나누어 예시 생성
장점
- 제로/퓨샷 학습 가능 -> 유연성 높음
- 모델 재학습 없이 추천 성능 개선 가능
단점 - 예시 선택 및 개수 조절이 어렵고 성능에 큰 영향
- 연구된 사례가 아직 적음
Tuning Paradigm (파라미터 학습 포함)
Fine-tuning
GPT-2, T5등 generative LLM에 전체 또는 일부 파라미터를 재학습
언어 생성 능력 + 추천 태스크 학습 동시 활용
e.g.
GPTRec - GPT2 기반 Sequential RS, memory-efficient tokenization 적용
FLAN-T5를 활용한 fine-tuned 모델
GPT3, ChatGPT -> text-based collaborative filtering에 활용
closed LLM -> 아이템 설명 보완, Open LLM(LLaMA 등) -> 유저/아이템 임베딩
장점
- 성능 우수 (task 최적화)
- zero-shot 대비 고성능 가능
단점 - 비용 높고, task 바뀔 때 마다 다시 학습 필요
Prompt Tuning
LLM 파라미터 고정, soft prompt또는 adapter 모듈만 학습
task-specific prompt vector 훈련
e.g.
prompt를 통한 의미 있는 토큰 생성 -> 임베딩 매칭으로 실제 아이템 정렬
ID-based RS와 통합 -> user/item ID를 확장 vocab으로 포함, hybrid prompting
text + 행동 기반 토큰을 결합, projection을 통한 token alignmnet
장점
- 경량화, 빠른 도메인 적용
- 다양한 하이브리드 전략과 통합 가능
단점
- 프롬프트 성능에 의존
- task 일반화 어려움
Instruction Tuning
다양한 태스크 instruction을 포함한 데이터로 LLM 전체를 다태스크 학습
multitask LLM 기반 추천시스템 구축
e.g.
P5 - instruction 기반으로 다양한 추천 task 학습 (P5기반)
FLAN-T5활용 - instruction 기반 multi-task RS
잡 추천, 행동 그래프 기반 설명형 추천 등에도 확장
장점
- 높은 zero/few-shot 성능 가능
- Instruction 기반 task 전이 유리
단점
- instructoin 설계에 민감
- 멀티 태스크 학습 시 데이터 및 자원 소모 큼
