[Paper Review]Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
Recommender System
Introduction
추천 시스템의 발전 방향은 다양한 특성을 수용하고 광범위한 응용 시나리오에 대응할 수 있는 종합적인 시스템을 지향하고 있음
추천시스템의 모델적 측면
CF(user-item 사이의 상호작용 데이터를 이용해서 사용자의 행동 패턴을 모델링 함) -> Contextual Informatoin (맥락 정보 e.g. 사용자 프로필, 아이템 데이터)가 통합되어 FM, GBDT와 같은 모델 등장 -> NN기반 모델들이 등장하여 represenation 측면에서 기존 방법론보다 성능이 높아짐
추천시스템 task적 측면
평점 예측, user-item 매칭 이외에도, 시퀀스 기반 추천, 대화형 추천, 설명 가능한 추천 등 추천 task의 종류가 다양해짐
transferable representation 학습에 대한 시도가 이루어지고 있음 -> task간 지식을 공유하고, 새로운 태스크에서의 일반화 능력을 높이려는 목적임
입
현재 추천 시스템의 한계
각기 다른 피처와 태스크들을 통합하여 처리하는 범용적 모델로 나아가기에 한계가 존재함
-> 대부분 추천 task는 동일한 user-item풀을 공유하고 있음, 관련된 맥락 정보도 상당 부분 중복됨
--> 이런 공통성을 기반으로, 여러 추천 task를 하나의 통합된 프레임웤 안에서 해결하는게 가능하다는 의견이 있음
---> task간의 간접적인 지식 전이 가능, 새ㅔ로운 task에 대한 일반화도 용이해짐
따라서 본 논문에서는 prompt-based multitask learning 연구에서 영감을 받아서, P5 프레임웤을 제안함
P5는 여러 추천 관련 task를 하나의 seq2seq framework안에서 통합적으로 학습할 수 있음
모든 문제는 프롬프트 기반 자연어 처리 task로 표현되며, 사용자 및 아이템 정보는 개인화된 프롬프트 템플릿을 통해 모델 입력에 통합됨
Method
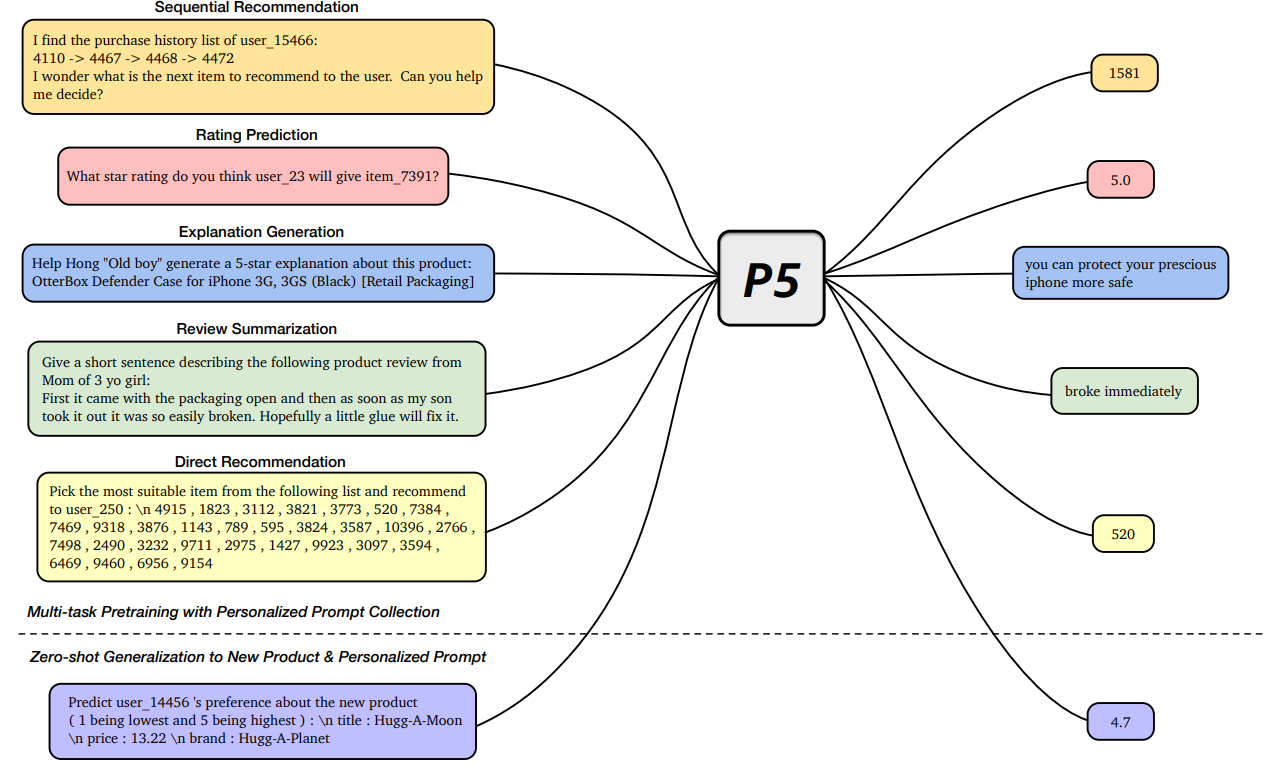
P5는 텍스트 입력을 받아서 목표 응답을 생성하는 encoder-decoder transformer model을 기반으로 사전학습 함
P5는 multitask personalized prompts로 학습하여 다양한 추천 task에 사용할 수 있게 함
-> P5는 본적없는 개인화된 프롬프트나 새로운 item에 대해서도 zero-shot generalizatoin 능력을 갖추게 됨
개인화된 프롬프트 템플릿을 설계하여 input-target pair를 구성하기 쉽게 한다
-> 프롬프트 안의 공간을 raw 데이터에 있는 해당 정보로 대체만 하면 됨
P5의 다섯가지 task 계열에 해당하는 raw데이터는 rating, review, explanation으로부터 수집됨
프롬프트 a는 공통된 raw데이터를 사용함
Sequential Recommendation과 direct recommendation은 유사한 데이터를 사용함
그러나 seqeuntial recommendation은 user의 interaction history를 사용함
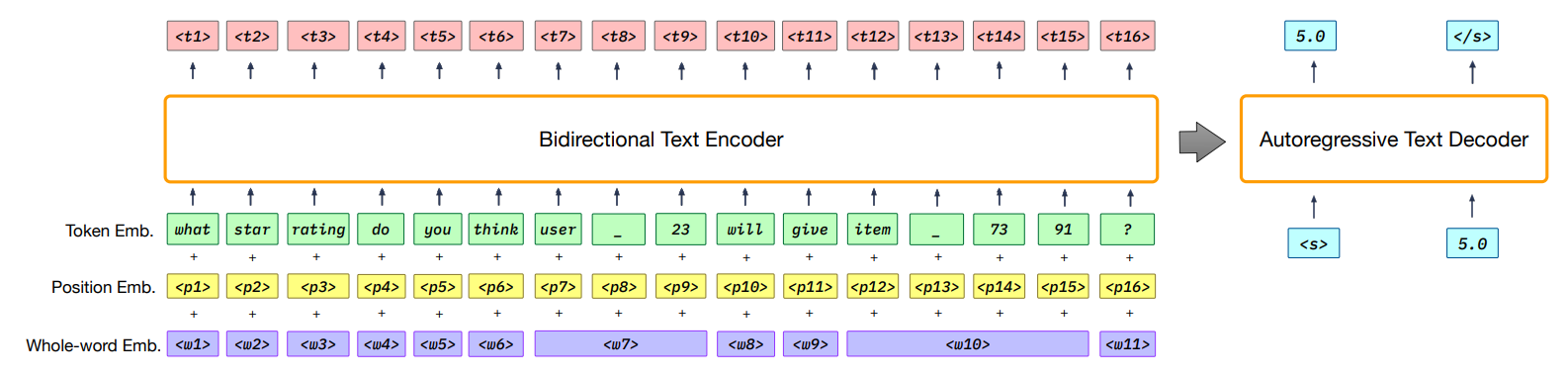
P3의 overall architecture임
e.g. user_23은 item_7931에 평점 몇을 줄것 같음? 과 같은 프롬프트 input에 대해서 P5는 encoder-decoder기반의 프레임웤을 사용함
1.input을 bidirectional text encoder로 encoding함
2. text decoder를 사용해서 autoregressively하게 응답을 생성함
기존의 task-specific recommendation model과 다르게 P5는 large personalized prompt를 활용한 multitask prompt based pretrained learning에 의존함
-> P5는 여러 추천 task에 적응할 수 있고, 새로운 형태의 개인화 프롬프트에 대해서도 일반화 할 수 있는 능력을 갖추게 됨
Personalized Prompt Collection
추천을 위한 멀티태스크 프롬프트 기반 사전학습을 위해서 개인화된 프롬프트 템플릿 collection을 생성함
5가지의 추천 task를 포함함
- 평점예측 (Rating)
- 순차 추천 (Sequenctial Recommendation)
- 설명 생성 (Explanation)
- 리뷰 관련 (Review)
- 직접 추천 (Direct Recommendation)
각 task는 P5가 사용자와 아이템에 대해서 다양한 측면을 학습하도록 하는 여러가지 개인화 프롬프트를 포함함
프롬프트는 imput template, target template, metadata로 구성됨
본 논문에서는 personalized fields가 포함된 프롬프트를 personalized prompt라고 정의함
e.g. 사용자의 선호는 ID 번호로 나타낼 수 있고, 이름, 성별, 나이등으로 서술 될 수 있음
개인화 프롬프트의 예상 출력은 해당 아이템 필드에 따라서 달라지고
-> 사용자의 선호가 아이템에 따라 변화함
--> 아이템 필드는 단순 Id, 아이템에 대한 상세한 설명이 포함된 metadata일 수 있음
각 태스크 계열별 P5 프롬프트 구성 방식
✦ 평점 예측 (Rating Prediction)
세 가지 유형의 프롬프트로 구성된다:
사용자와 아이템 정보를 바탕으로, 1~5 범위의 평점 점수를 직접 예측.
사용자가 아이템에 특정 평점을 줄 것인지 예측 → 출력: Yes / No
사용자가 아이템을 좋아하는지(like) 싫어하는지(dislike)를 예측
별점이 4 이상이면 like, 미만이면 dislike로 간주.
✦ 순차 추천 (Sequential Recommendation)
세 가지 유형의 프롬프트:
사용자의 상호작용 이력(interaction history)을 바탕으로 다음에 소비할 아이템을 직접 예측.
사용자의 이력을 바탕으로 주어진 후보 목록 중에서 정답 아이템을 선택.
사용자 이력을 바탕으로 지정된 아이템이 다음 상호작용 대상일지를 예측.
✦ 설명 생성 (Explanation)
P5가 사용자가 특정 아이템을 선호하는 이유를 설명하는 문장을 생성해야 한다.
두 가지 유형:
사용자와 아이템 정보를 바탕으로 직접 설명 문장 생성
특징 단어(feature word)를 힌트로 주어 이를 기반으로 설명 생성 ([31] 참고)
각 유형에서는 리뷰 제목, 평점 등의 보조 정보가 포함될 수 있다.
✦ 리뷰 관련 태스크 (Review)
두 가지 유형:
리뷰 본문을 짧은 제목으로 요약.
리뷰만 보고 평점 점수를 예측.
✦ 직접 추천 (Direct Recommendation)
두 가지 유형:
특정 아이템을 사용자에게 추천할지 예측 → 출력: Yes / No
후보 아이템 리스트 중에서 가장 적합한 아이템을 선택하여 추천.
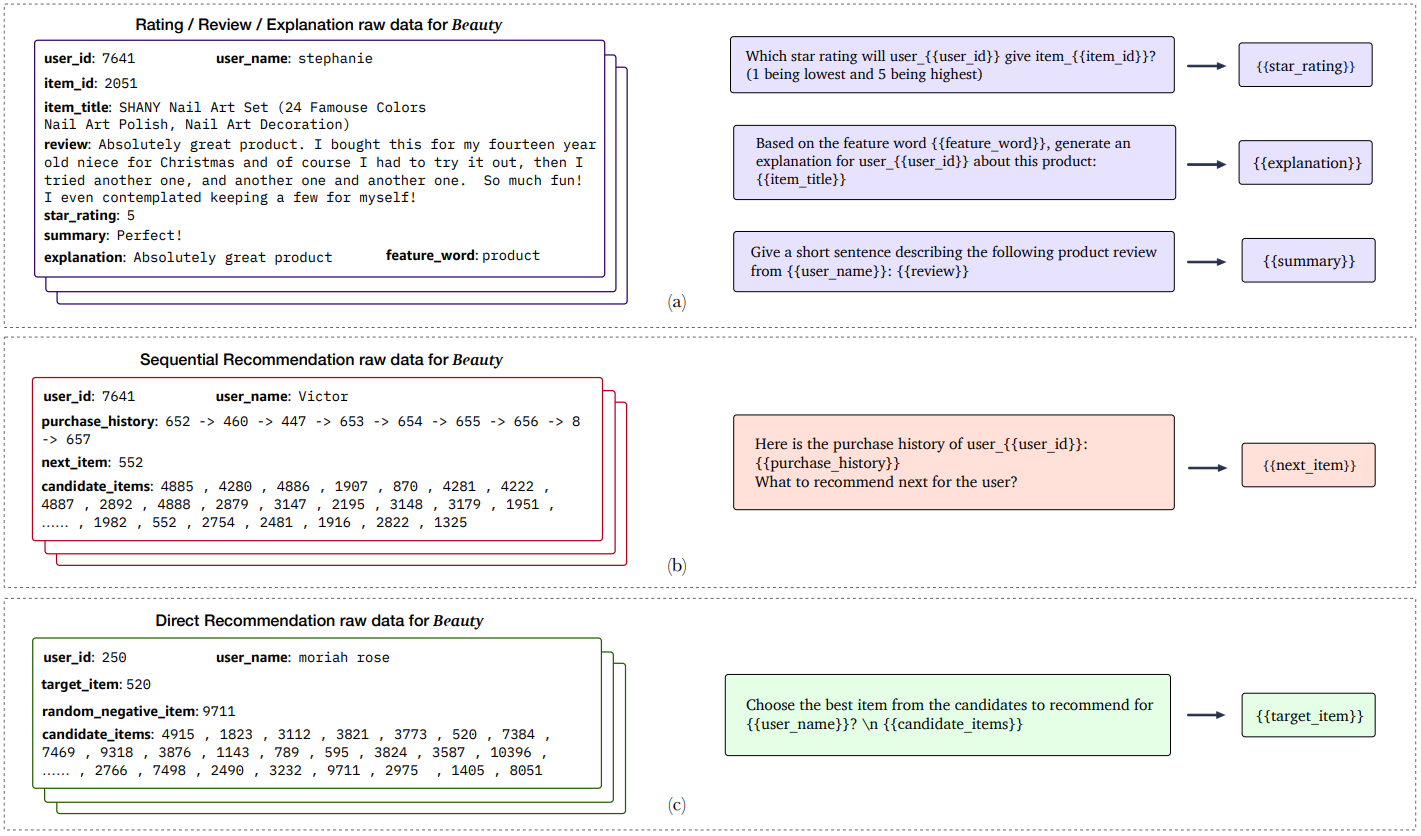
프롬프트를 활용한 입력–출력 쌍 생성
프롬프트를 활용하면, raw 데이터로부터 직접 입력–출력 쌍(input–target pairs)을 생성할 수 있음
Figure 2에서 보듯이, 프롬프트 안의 중괄호({}) 부분을 raw 데이터의 해당 정보로 단순히 치환(substitute)하면 됨
이러한 방식으로 학습용 입력–출력 쌍이나 제로샷 테스트용 개인화 프롬프트를 만들 수 있음.
학습 데이터 구성 방식 및 전처리 전략
학습 데이터와 사전학습 태스크를 통해, 다양한 모달리티에서 나오는 풍부한 의미 정보를 사용자/아이템 토큰에 내재화하여 개인화를 학습함
raw 데이터는 세 가지로 나뉨:
평점/리뷰/설명 태스크는 같은 raw 데이터를 공유하고 순차 추천과 직접 추천은 유사한 데이터를 사용하지만, 순차 추천은 상호작용 이력을 반드시 사용한다는 점에서 차이가 있음
사전학습 시, 서로 다른 태스크 계열의 입력–출력 쌍을 섞어서(multitask mix) 학습 데이터로 사용함
모델의 견고성 및 제로샷 일반화 성능 향상을 위해, 각 raw 데이터에 대해 모든 프롬프트가 아닌 일부만 샘플링하여 사용함
특히, 순차 추천 및 직접 추천 계열에서는 후보 리스트가 필요한 프롬프트에 대해 음성 아이템(negative items)을 무작위로 선택하여 구성함.
본 논문의 방법론은 크게 두 가지 step으로 나뉨
P5 Architecture
개인화된 프롬프트 모음은 다양한 추천 관련 태스크를 포함하는 대규모 사전 학습 데이터를 쉽게 생성할 수 있게 해주는 것 임
-> 모든 사전학습 데이터는 input-target token sequence의 통일된 형식을 따름
--> 서로 다른 task간의 경계를 허물 수 있음 (간섭 가능하다고 생각됨)
본 논문에서는 다양한 추천 task를 conditional generation 기반의 통합된 framework 에서 pretrain하여 모든 관련된 task의 학습 효율이 향상된다고 함
이는 P5를 pretrain 단계에서 완전히 language 환경에 넣어서 본적없는 개인화된 프롬프트와 상세한 item description에 대해서도 이해할 수 있는 zero-shot generalization capability를 갖추게 됨
P5는 기본적으로 인코더-디코더 프레임웤을 기반으로 설계됨
transforemr를 써서 인코더와 디코더를 구성함
중요 포인트는 bidirectional text encoder에 임베딩 시퀀스를 입력하기 전에 입력 시퀀스에 포함된 개인의 정보를 P5가 인식할 수 있게 sub-word 토큰들이 동일한 원 단어에서 나왔는지 나타내는 whole-word임베딩도 함께 적용함
예를 들어, 아이템 ID 7391을 “item7391”로 표현하면, SentencePiece 토크나이저 [54]에 의해
“item”, “”, “73”, “91”로 네 개의 토큰으로 분리된다.
공유된 whole-word 임베딩의 도움을 받아서 P5는 개인화 정보가 포함된 중요한 필드를 더 잘 인식할 수있게 함
또 다른 대안은 각 사용자/아이템을 별도의 독립 토큰(예: ⟨item_7391⟩)으로 표현하는 것이지만, 사용자나 아이템 풀이 매우 큰 경우에는 막대한 수의 추가 토큰이 발생함
->따라서 본 논문에서는 사용자와 아이템을 여러 개의 서브워드 단위로 표현하는 방식을 채택함
후에 인코더는 세 가지 임베딩(토큰, 위치, whole-word)의 임베딩의 컨캣인 임베딩을 받아서, 문맥화된 표현을 출력함
디코더는 인코더 출력과 이전에 생성된 토큰에 어텐션을 적용하여 다음 토큰의 확률 분포를 예측함
Pretrain 단계에서 P5는 입력 텍스트에 조건화된 출력 토큰의 negative log-likelihood 를 최소화 하도록 파라미터를 학습함
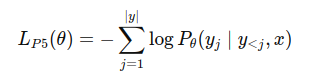
로스는 P5가 수행하는 모든 추천 태스크에서 동일하게 사용됨
-> 하나의 모델, 하나의 로스, 하나의 데이터 형식 (통일하긴 했지만..) 으로 모든 추천 task를 통합함.
Recommendation with Pretrained P5
사전학습 이후에 P5는 이전에 본적 있거나 없었던 개인화된 프롬프트에 대해 다양한 task를 수행할 수 있음
Rating, Explanation, Review task
-> greedy decoding을 사용하여 응답 생성
Sequential Recommendatoin 및 Direct Recommendation task
-> 아이템 리스트를 출력으로 요구함
--> Sequential Recommendation은 beam search를 활용하여 다음 아이템 후보 리스트를 생성하고, 이를 all-item setting 기준으로 평가함
--> Direct Reommendatoin task는 후보 집합 중 하나의 아이템만이 positive인 상황에서 추천할 아이템을 예측 함, 여기서도 beam search를 사용해서 가장 점수가 높은 후보 아이템 리스트를 디코딩하고 평가를 수행함
