[Paper Review] Stop Playing the Guessing Game! Target-free User Simulation for Evaluating Conversational Recommender Systems
Recommender System
Introduction
CRSs(Conversatoinal Recommender Systems) 는 개인화된 경험을 향상시키기 위해 대화적 상호작용을 통한 개인화된 추천을 제공함.
-> 단순히 아이템 추천에 그치지 않고, 사용자와 의미 있는 대화를 주고받으며, 사용자의 선호도를 자연스럽고 친숙한 방식으로 이해함.
상호작용을 하며 CRSs는 두 가지 작업을 수행해야 함.
- Preference elicitatoin(선호도 유도) - 대화를 통해 사용자가 좋아하는 것(like)/싫어하는 것(dislike)를 표현하도록 유도함으로써 사용자 선호도를 탐색하고 발견하는 것.
- Recommendation(추천) - 대화를 통해 파악된 선호도를 바탕으로 개인화된 아이템 추천
CRS 분야의 한계점
시스템의 성능을 자동으로 평가하는 것이 과제로 남아 있음
-> 평가 지표가 문맥에 민감한 사용자 선호도 및 만족도를 충분히 포착하지 못하고
-> 실제 사용자와의 상호작용을 통한 테스트는 비용이 많이 들고 시간이 오래걸림
최근 연구 동향
실제 사용자가 CRS와 대화하는 상황을 시뮬레이션하여 보다 현실적인 테스트 환경을 조성하려는 시도가 이루어짐.
-> llm을 활용하여 사람과 같이 반응을 생성하게 해서 CRS와의 대화를 실제처럼 할 수 있게 함.
--> 인간의 행동을 잘 반영하는 신뢰할 수 있는 llm 기반 사용자 시뮬레이터 설계가 떠오름
llm 기반 CRS 추천능력 평가 방법의 한계
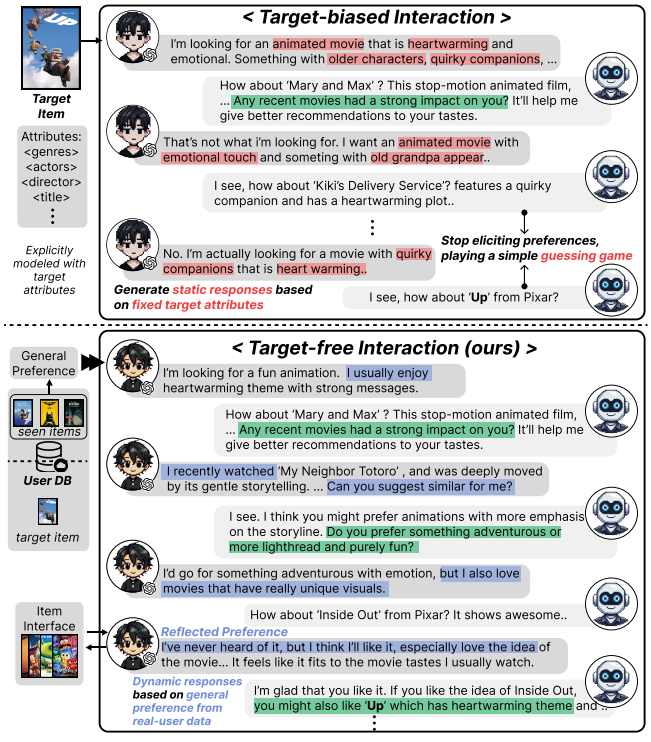
- Target-biased user simulation
- 기존 방식은 사용자가 사전에 명확한 선호도를 갖고 있다고 가정하며, 이를 통해 CRS가 특정 대상 아이템을 식별할 수 있도록 함.
-> 사용자 시뮬레이터가 target item 정보를 기방느로 작동하게 되어 CRS가 대화 중 목표 선호도로 쉽게 도달할 수 있게 함
--> 대화를 정적인 응답으로 단수화시킴 + 대화 도중 선호도가 커지는 특성을 반영하지 못함.
---> 선호도 유도를 단순한 추측 게임 수준으로 격하시키고 CRS의 능력을 제대로 평가하지 못하게 됨
- 신뢰할 수 있는 지표 부족
- 현재의 평가지표는 single-turn recall 정도만 있음
-> 대화 도중 서호도를 유도하는 과정을 반영하지 앟음
--> CRS가 사용자의다양한 취향을 얼마나 잘 이끌어내는지를 평가하기 어렵게 만듦
따라서 본 논문에서는 이러한 문제를 해결하기 위하여 CRS의 개인 선호도 유도 및 추천 능력을 평가하기 위한 PEPPER(Protocol for Evaluating Personal Preference Elicitation and Recommendatoin)을 제안함
PEPPER는 목표 항목 기반 상호작용의 문제를 해결하기 위해, 실제 사용자 상호작용 이력과 리뷰에서 도출된 다양한 선호도를 기바으로 한 target-free 사용자 시뮬레이터를 도입 함.
이 시뮬레이터는 고정된 target item attribute 대신 리뷰 기반 사용자 프로필을 바탕으로 초기 행동을 개인화 함.
특히, 사용자가 CRS와의 대화를 통해 스스로 선호도를 점차 발견하도록 유도하고, 대화 중 나타나는 아이템들에 대해 일반적인 선호도를 방녕하여 암묵적인 선호도를 대화 맥락에 지속적으로 통합함으로써 사용자 시뮬레이션을 더욱 풍부하게 만듦.
-> 사용자가 자신의 선호도를 지속적으로 조정해나갈 수 있는 맥락 중심 시뮬레이션 환경은 CRS가 사용자의 선호를 능동적으로 유도해야마 정확하게 목표 지점에 도달 할 수 있게 함
추가적으로 본 논문에서는 선호도 유도 과정을 평가하기 위한 정량적, 정성적 측정 방법을 함께 제안하여 CRS의 능력을 보다 포괄적으로 평가하게 함
CRS의 선호도 유도 능력은 대화를 자연스럽고 흥미롭게 이끌며 사용자가 자신의 다양한 선호를 발견하고 만족스러운 경험에 도달하도록 안내하는 능력으로 정의함
-> 정량적 지표로 Preference Coverage를 제안하여 대화 도중 얼마나 효과적으로 사용자의 다양한 선호도를 끌어냈는지를 평가함
-> 정성적 지표로 score rubrics를 제안하여 선호도 유도 과정의 세 가지 측면 (능동성, 일관성, 개인화)를 평가하는 평가기준을 제안 함
--> 이러한 두 가지의 접근방식은 CRS의 기능적 성능과 섬세한 대화 능력도 포괄적으로 평가할 수 있도록 하고, CRS 평가를 위한 신뢰성 높은 프로토콜을 제공함.
Contributions
- 실제 사용자 데이터에 기반한 target-free 사용자 시뮬레이터를 활용한 새로운 CRS 평가 프로토콜 PEPPER를 제안함
- PEPPER는 단순한 추측 게임에 빠지지 않는 현실적인 대화형 상호작용을 가능하게 하고, 사용자와의 대화를 통해 선호도를 점차적으로 발견할 수 있게 함
- PEPPER는 CRS의 선호도 유도 능력을 Preference Coverage(정량적 지표), 정성적 평가 기준(능동성, 일관성, 개인화)을 통해 정교하게 평가할 수 있도록 설계 됨
- 다양한 실험을 통해, PEPPER의 시뮬레이션 환경의 타당성을 입증하고, 기존 CRS가 선호도 유도 및 추천에 얼마나 효과적인지를 분석 함.
Proposed Method
CRS의 Preference elicitation과 recommendatoin ability를 포괄적으로 평가하기 위해 설계된 새로운 평가 프로토콜인 PEPPER를 소개 함
PEPPER는 두 가지 핵심 구성 요소를 포함 함
1. 실제 사용자 상호작용 이력과 리뷰에서 추출한 다양한 선호도를 반영한 target-free 사용자 시뮬레이터
2. CRS가 사용자 선호를 얼마나 잘 유도하고 정확한 추천을 제공하는지를 측정할 수 있는 선호도 유도 평가 지표
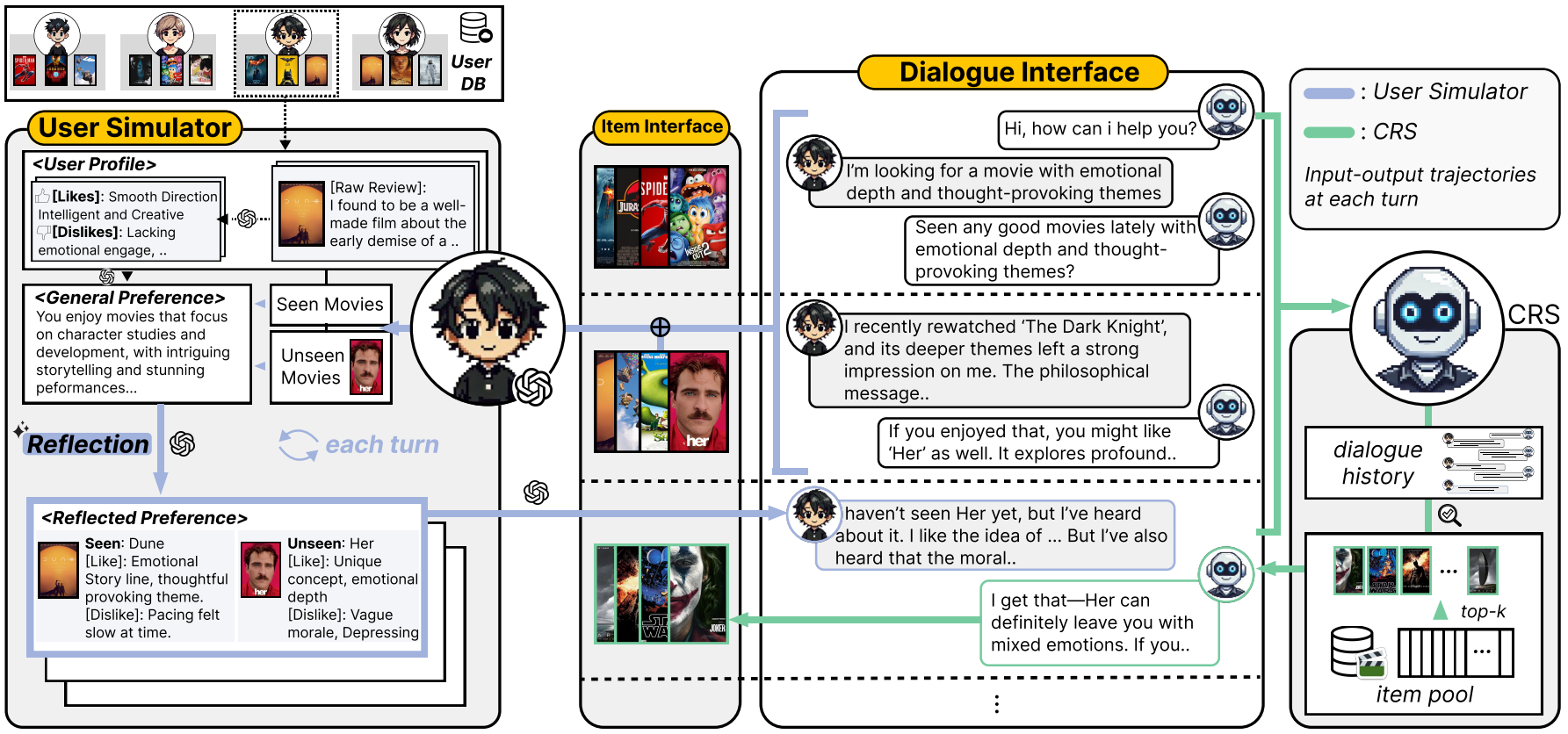
Interaction Environment
전체 프레임워크는 두 개의 생성 에이전트로 구성됨
target-free user simulator, CRS
두 에이전트는 대화 인터페이스와 아이템 인터페이스를 통해 상호작용 함
-> 대화 인터페이스는 사용자와 CRS 간의 커뮤니케이션을 연결
-> 아이템 인터페이스는 각 턴에서 tok-k개의 추천 아이템과 관련 메타데이터를 보여줌
--> 사용자가 실제로 추천 아이템에 대한 상세 정보를 확인할 수 있는 현실적인 환경 모사
사용자 시뮬레이션의 과정
- 사용자 리뷰에서 대표적인 특성 추출 -> binary preference로 변환
- 해당 선호도를 텍스트로 변환하여 사용자 시뮬레이터의 일반 선호도를 구성
- 사용자 시뮬레이터는 일반 선호도에 부합하는 추천을 요청하며 대화 시작
- CRS는 응답과 함께 아이템 인터페이스를 통해 상위 K개 아이템을 제시
- 사용자 시뮬레이터는 seen item에 대해 회고하거나 unseen에 대해 선호 여부를 표현하며 선호도를 점진적으로 정제해 나감.
Target-free User Simulator
기존 방법론과는 다르게, 사전 정의된 target item 없이, 실제 사용자 데이터에서 도출한 다양한 선호도를 기반으로 시뮬레이터를 설계함.
시뮬레이터는 대화 속에서 선호하는 것을 구체화 하며, 실제 사용자처럼 자연스럽게 자신의 관심사를 표현하도록 함
-> 두 가지 핵십요소를 도입하여 이를 수행함
1. General Preferences
2. Reflected Preferences
General Preferences
- 사용자 시뮬레이터의 General Preferences는 상호작용 이력 및 리뷰가 포함된 실제 사용자 데이터베이스를 기반으로 구축됨
-> 단순한 아이템 속성 이상으로, 줄거리, 전개속도, 감정 등 복잡한 의견을 capture할 수 있음 - 리뷰는 noise나 애매한게 있어서 ChatGPT를 활용하여 Likes/Dislikes로 이진 분류 함
- 상호작용 이력을 seen item과 target item으로 구분하여 seen item의 정보만을 기반으로 대표적 특성만 포함한 서술가능한 선호도를 생성함
- 생성된 일반 선호도는 시뮬레이터 초기화에 활용되어, 각 시뮬레이터가 고유 사용자 사례를 모사하도록 설계됨.
Reflected Preferences
현실의 사용자는 명시적 선호도, 암묵적 평가, 기대치에 따라 아이템을 판단하는데, Reflected Preferences는 동적이고 적응적인 행동을 시뮬레이션 하는 기능을 함.
- CRS는 각 턴에서 top-k개의 아이템을 예측해 제안함.
- 이를 seen item/unseen item 으로 분리함
- seen item은 시뮬레이터가 과거 리뷰를 회상함. unseen item은 일반 선호도에 기반한 이진 선호 설명을 생성하게 함
-> 선호 표현은 다음 턴의 응답 입력에 반영되어 대화 맥락을 풍부하게 함.
Quantitative Metric for Preference Elicitation.
CRS의 선호도 유도 능력은 “CRS가 얼마나 능동적으로, 자연스럽고 흥미로운 대화를 통해 사용자로 하여금 다양한 선호도를 발견하고 만족스러운 경험에 도달하도록 유도하는가.”로 정의 됨
-> CRS의 선호도 유도 능력을 평가하기 위해 4가지 측면을 고려함
- Preference Coverage
- CRS가 사용자 선호도를 얼마나 다양하게 파악하고 반영했는지를 평가
- Proactiveness
- CRS가 얼마나 능동적으로 대화를 주도하며, 선호도를 밝히기 위한 제안/질문을 수행했는지
- Coherence
- 대화가 얼마나 자연스럽고 유기적으로 유지되었는지, 맥락에 어울리는 응답 제공 여부
- Personalization
- CRS가 얼마나 사용자의 선호에 맞춘 정보 및 추천을 제공했는 지
Preference Coverage
PC는 대화중 CRS가 얼마나 맣은 target item을 발견했는지 누적 평가함
PCₜ = (1 / |U|) ∑[𝑢∈𝑈] |(∪ₓ=1ᵗ Pᵤₓ) ∩ 𝑌(𝑢)| / |𝑌(𝑢)|
- PC는 t턴까지 예측된 아이템 집합과 실제 목표 아이템의 교집합 비율을 측정함
-> PCIR (Preference Coverage 증가율)도 정의
PCIRₜ = PCₜ − PCₜ₋₁- PCIR은 매 턴마다 새로 발견된 선호도의 비율을 나타내며, 대화 중 CRS가 얼마나 맣ㄴ은 새로운 선호를 유도했는지를 측정할 수 있음
Qualitative Metric for Preference Elicitation
GPT-4.0과 같은 LLM을 평가자로 활용함
- 1~5점의 rubric을 주어 llm이자동 평가를 수행하도록 함.
- 평가 대상은 IMDBRedial과 IMDBOpenDialKG 데이터 셋. 각 1000명의 시뮬레이터를 사용함
- 입력은 생성된 대화 내용과 시뮬레이터의 일반 선호도
llm의 평가기준
- Proactiveness, Coherence
-> 전체 대화 히스토리를 기반으로 CRS가 얼마나 능동적으로 대화를 이끌고 유창하게 유지했는지 분석 - Personalization
-> CRS의 응답이 사용자의 일반 선호도와 얼마나 잘 일치했는지를 평가. 시스템의 추천, 설명, 응답이 사용자의 명시적/암묵적 선호와 얼마나 일치하는지를 판단.
