few-shot의 철학
인간은 사진 몇 장만 가지고 대충 감을 잡아서 예측을 한다. 그러면 인공지능도 수백장을 사용한 fine-tuning없이도 그러한 것을 할 수 있지 않을까? 이러한 철학에서 연구되는 분야가 few-shot learning이다.
정의
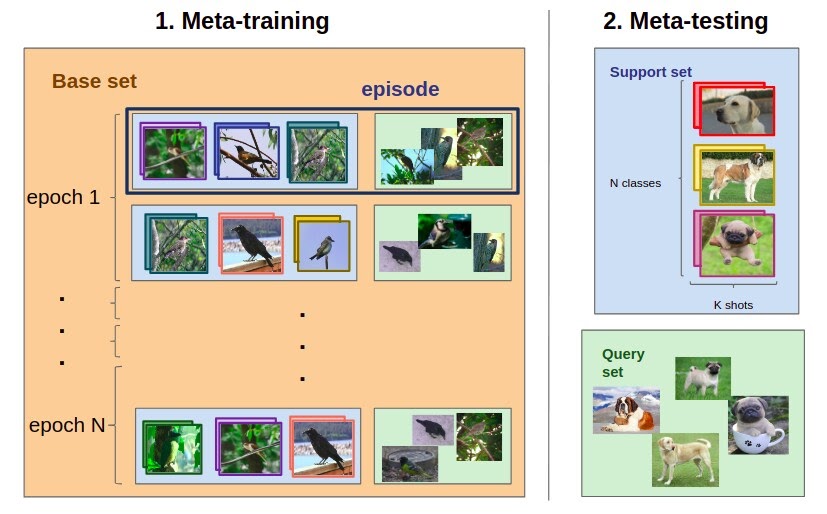
Training set, Support set, Query image가 필요하다. training set을 통해 구분하는 법을 배우고, query가 들어왔을 때, 그 이미지가 support set 중 어떤 것과 같은 종류인지 구분하도록 학습하는 것을 few-shot learning이라고 한다. query이미지 클래스는 training set에 없다는 점이 지도학습과는 다른 점이다. 성능이 좋으려면, 클래수의 개수가 적어야 하고, support의 개수가 많은 것이 좋다.
contrastive loss의 궤도
- Max margin contrastive loss (Hadsell et al. 2006)
- Triplet loss (Weinberger et al. 2006)
- Lifted Structure Loss
- Multi-class N-pair loss (Sohn 2016)
- Angular Loss
- Divergence Loss
학습 방법
-
학습을 하는 경우(vision)
클래스를 구분하는 것이 아닌 유사도나 좋은 representation을 배우도록 학습을 한다. 일종의 contrastive learning으로 metric learning(metric이란 유사도 측정 지표들을 지칭한다.)의 일종이다. 그리고 그 모델을 가지고 query를 돌리고 support set도 돌린 다음에, 유사도 측정지표로 비교 후 가장 가까운 이미지를 클래스로 뱉는다. -
학습O/학습x (NLP)
학습을 하는 경우는 pattern-exploiting training(PET)방법[roberta 기반]이 있다. finetuning을 사용하여 학습을 하고, 미리 few-shot sample들을 주고, 그 뒤에 그 sample들이 긍정인지(good) 부정인지(bad) 판단하는 답을 준다. 그리고 good, bad 부분만 mask 처리를 하고 그것을 맞추는 bert 학습 기법을 사용한다. 대신 기존 finetuning 방법론과 달리 이러한 방법은 새로운 fc layer를 추가할 필요가 없이 기존의 네트워크를 그대로 사용한다는 장점을 가지고 있다.학습하지 않는 방법 중에 GPT-3가 대표적이며, 이러한 학습법을 in context learning이라고 표현한다. 이 경우는 backpropagation 과정이 없고 feed-forward로만 예측한다. 이 때 예측시에 few-shot sample들이 주어지고 query를 넣어 답을 찾는 방법이다. 이 때 description과 few-shot sample을 미리 구성하고 query를 동시에 넣어주어서 few-shot sample들은 hidden state 정보에 녹아들게 된다. 이 때 few-shot sample들은 prompt or context라고 부른다.
