KNN의 정의
- K-Nearest Neighbor(KNN): 기존의 데이터 중 가장 가까운 k개를 바탕으로 새로운 데이터를 예측하고 분류하는 알고리즘
- 판별하려는 데이터와 인접한 데이터 k개를 찾아 그중 빈도수가 가장 높은 데이터를 범주로 분류한다.
- 거리를 측정할 때에는 주로 Euclidian distance를 사용한다.
- 이미지 처리, 영상 속 글자 인식, 얼굴 인식, 암 진단, 개인 선호 예측 및 추천 기술 등
K 정하기
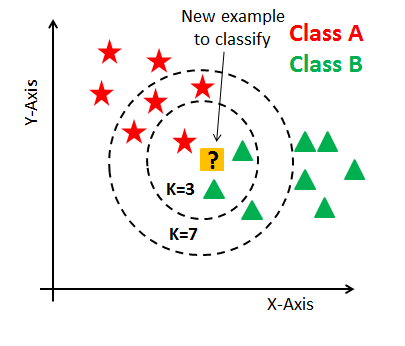
그림에서는 변수가 2개이지만 더욱 많은 변수들이 관여하기도 한다.
- k=3일 때: 새로운 샘플이 Class B로 분류됨
- k=7일 때: 새로운 샘플이 Class A로 분류됨
- 동점이 되지 않도록 k값은 홀수로!!
- k값이 너무 클 때: 미세한 경계부분 분류 X
-> Underfitting - k값이 너무 작을 때: 이상치의 영향 많이 받고 패턴이 직관적이지 X
-> Overfitting
다양한 시도와 경험을 통해 적절한 k값을 찾자!!
거리 구하기
Euclidian distance
n차원 공간에서 두 점간의 거리를 알아내는 공식이다. 2차원에서의 피타고라스 정리를 생각하면 쉽다.

거리에 반비례하는 가중치를 줘서 더 가까운 이웃일수록 평균에 더 많이 기여하도록 한다.
- 이웃까지의 거리가 d일 때 각 이웃에게 1/d의 가중치를 주는 방법이 대표적이다.
KNN의 장단점
장점
- 단순하고 효율적이다.
- 훈련 단계가 빠르다.
- 기저 데이터 분포에 대한 가정을 하지 않는다.
- 수치 기반 데이터 분류 작업에서 성능이 우수하다.
특별한 훈련이 없기에 lazy learning(게으른 학습)이라고도 불린다.
단점
- 모델을 생성하지 않아 특징과 클래스간 관계를 이해하는데 제한적이다.
- 적절한 k의 선택이 중요하다.
- 데이터가 많아지면 분류 단계가 느리다.
- 명목 특징 및 누락 데이터를 위한 추가 처리가 필요하다.
더미코딩: 명목 특징을 수치 형식으로 변환하는 코딩- 수치 형식으로 변환하여 유클리디안 거리 공식에 대입한다.
위의 그림은 더미코딩의 예시이다. - KNN 자체가 데이터 분석에서 중요한 변수를 파악하는 것이 아니라 데이터 분석가가 직접 중요하다고 여기는 변수를 선정하고 알고리즘을 적용하기에 사전 분석 작업이 많이 요구된다.
- 훈력 단계는 짧지만 예측 단계는 상대적으로 느리다.
- 수치 형식으로 변환하여 유클리디안 거리 공식에 대입한다.
KNN 사용방법
각 column의 데이터마다 scale이 다를 것이기에 수치 형식의 데이터들의 값을 모두 0~1 사이로 변환시키는 정규화(Normalization) 과정을 거쳐야 한다.
예를 들어 class A는 데이터 분포가 0~10, class B는 데이터 분포가 0~100000일 수도 있기에 이런 경우 각 변수들의 차이를 해석하기 어렵다.
Min-Max Normalization
최소-최대 정규화는 모든 feature에 대해 각각 최솟값을 0, 최댓값을 1로, 다른 값들은 0~1 사이의 값으로 변환하는 정규화를 말한다.
X라는 값에 대해 Min-Max Scaling을 하면
(X - MIN) / (MAX-MIN)
와 같은 수식을 사용할 수 있다.
def min_max_normalization(lst):
normalized = []
for value in lst:
normalized_num = (value - min(lst)) / (max(lst) - min(lst))
normalized.append(normalized_num)
return normalized위의 코드는 파이썬으로 최소-최대 정규화 함수를 작성한 것이다.
Min-Max Normalization에는 몇가지 단점들이 있다.
- 이상치(outlier)에 너무 많은 영향을 받는다.
예를 들어 1000개의 값들 중 999개는 0~300 사이에 있고, 나머지 하나는 1000이라면 정규화를 했을 때 999개의 값들은 0~0.3 사이에 있고 나머지 하나만 1로 변환된다. - 예측할 데이터셋에서 최솟값과 최댓값이 범위를 벗어나는 경우가 생긴다.
train set에서 최댓값이 100이었다고 할 때 예측할 미래의 데이터가 그 범위를 벗어나는 문제가 생길 수도 있다.
=> KNN에서는 주변 값들이 Max보다 클 경우 등의 상황에서 발생한다.
Z-Score Normalization
Z-점수 정규화는 이상치(Outlier) 문제를 피할 수 있는 데이터 정규화 전략이다. X라는 값을 Z-Score로 바꾸어준다.
고등학교 확통시간에 열심히 썼던 "그 공식"
(X - 평균) / 표준편차
feature의 값이 평균과 같다면 0, 평균보다 작으면 음수, 평균보다 크면 양수로 정규화된다. 표준편차가 크다는 것은 값들이 널리, 고르게 분포해 있다는 뜻이고, 그럴수록 분모가 커져서 정규화되는 값들은 0에 가까워진다.
def z_score_normalize(lst):
normalized = []
for value in lst:
normalized_num = (value - np.mean(lst)) / np.std(lst)
normalized.append(normalized_num)
return normalized위의 코드는 파이썬으로 Z-Score Normalization 함수를 만든 것이다.
예제
Scikit-Learn의 iris data set에서 knn을 적용해 보았다.
Scikit learn은 파이썬에서 머신러닝을 실행할 수 있도록 하는 패키지이다.
- 속성은 꽃받침 길이(sepal length), 꽃받침 폭(sepal width), 꽃잎 길이(petal length), 꽃잎 폭(petal width)로, 네가지이다.
- label이 꽃의 종류로, 꽃의 종류를 예측하는 분류(Classification) 문제이다.
https://colab.research.google.com/drive/1Cknt2JPIpiiO4QDCe1KXlXw71b0yH8-g?usp=sharing
위의 링크에 iris 데이터셋을 knn classifier로 분류한 예제를 작성해 놓았다.
출처
http://hleecaster.com/ml-normalization-concept/
https://blog.naver.com/PostView.nhn?blogId=bsw2428&logNo=221388885007&proxyReferer=https:%2F%2Fwww.google.com%2F
https://ko.wikipedia.org/wiki/K-%EC%B5%9C%EA%B7%BC%EC%A0%91_%EC%9D%B4%EC%9B%83_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98#cite_ref-2
https://john-analyst.medium.com/knn-%EC%B5%9C%EA%B7%BC%EC%A0%91-%EC%9D%B4%EC%9B%83-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-b397a0b2030e
https://velog.io/@gr8alex/KNN-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98#euclidean-distance
https://velog.io/@guns/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EC%8A%A4%ED%84%B0%EB%94%94-3%EC%9D%BC%EC%B0%A8-K-NN-K-Nearest-Neighbor
https://www.youtube.com/watch?v=8gd0QeQ9ilQ
https://dheldh77.tistory.com/entry/Python-Iris-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D
https://woolulu.tistory.com/1

안녕하세요 머신러닝에 관심이 있는 학생입니다 혹시 knn관련 코드 질문 하나만 드려도 될까요..?