Ensemble의 정의
- 앙상블의 사전적 의미: 조화, 통일
- 데이터의 값을 예측할 때 하나의 모델만 사용하지 않고, 여러 개의 모델을 '조화'롭게 학습시켜 예측의 정확도를 높이는 방법이다.
- 모델 결합(model combining)이라고도 한다.
- 하나의 모델로 원하는 성능X -> 앙상블 학습 -> 일반화 성능 향상
- 여러 개의 약 분류기(Weak Classifier)를 결합하여 강 분류기(Strong Classifier)를 만드는 과정
앙상블 학습에는 크게 배깅(Bagging)과 부스팅(Boosting)이 있다.
배깅(Bagging)
Bagging은 Bootstrap Aggregation의 약자이다. 배깅은 샘플을 여러 번 뽑는 Bootstrap을 통해 각 모델을 학습시켜 결과물을 집계(Aggregation)하는 방법이다.

위의 그림처럼 데이터를 부트스트랩한 후 부트스트랩한 데이터로 모델을 학습시키고, 각 모델들의 결과를 집계하여 최종 결과값을 구한다.
이 때 각 Decision Tree 모델들의 결과 예측은 독립적으로 시행된다.
부트스트랩(Bootstrap)
기존에 있는 표본에서 추가적으로 표본을 복원 추출하고 각 표본에 대한 통계량을 다시 측정하는 방식이다.
ex) 1억개의 모집단에서 200개의 표본을 추출했다고 가정하자.
- 200개의 표본 중 하나를 복원 추출하여 기록한다.
- 이를 n번 반복한다.
- n번 재표본추출한 값의 평균을 구한다.
- 1~3단계를 R번 반복한다.(R: 부트스트랩 반복 횟수)
- 평균에 대한 결과 R개로 신뢰구간을 구한다.
=> 모수에서 균등하게 뽑은 표본의 분포 사이사이를 메워서 더 정확한 추정이 가능해진다.
R값이 클수록 신뢰구간의 추정이 더 정확해진다.
결정 트리(Decision Tree)
의사결정 트리라고도 하며, 분류(Classification)과 회귀(Regression) 모두 가능한 지도 학습 모델이다. 특정 기준이나 질문에 따라 데이터를 구분하는 모델을 결정 트리 모델이라고 한다.
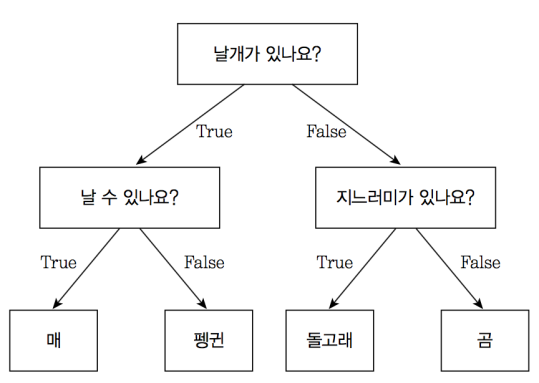
위의 그림은 결정 트리 모델의 예시이다.O / X로 나뉘도록 설계되어 있다.
처음의 분류 기준이나 질문을 Root Node, 마지막 노드들을 Terminal Node 또는 Leaf Node라고 한다. 위의 예시에서는 '날개가 있나요?'가 Root Node, '매', '펭귄, '돌고래', '곰'이 Terminal Node라고 볼 수 있다.
결정 트리 알고리즘 과정

이처럼 데이터를 가장 뚜렷하게 구분할 수 있는 기준으로 먼저 데이터를 분류해준다.
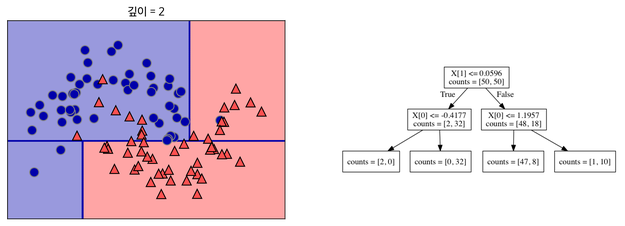
분류된 데이터들을 잘 나눌 수 있는 기준을 다시 세워준다. 이 과정을 반복한다.
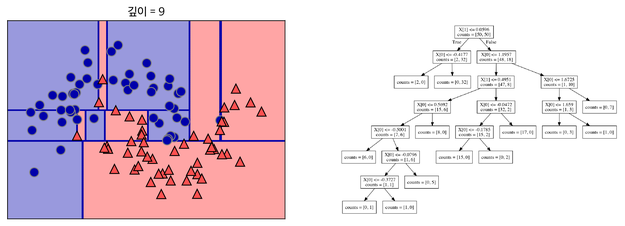
지나치게 많이 할 경우 위 그림과 같이 Overfitting이 될 수 있다. 결정 트리에 아무 Parameter를 주지 않고 모델링할 경우에 Overfitting이 나타난다.
가지치기(Pruning)
오버피팅을 줄이기 위한 전략이다. 오버피팅은 트리에 가지가 지나치게 많을 때 나타나기에 최대 깊이나 Terminal Node의 최대 개수 등을 제한하는 작업을 해주는 것이다.
- min_sample_split이라는 Parameter를 조정하여 한 노드에 들어있는 최소 데이터 수를 정할 수도 있다.
ex) min_sample_split = 5이면 한 노드에 5개의 데이터가 존재할 때 해당 노드는 더이상 나누어지지 않는다. - max_depth(최대 깊이)를 조정할 수도 있다.
ex) max_depth = 3이면 깊이가 3보다 크게 가지치기를 하지 않는다.
결정트리는 다음 글에서 더 자세히 다루도록 하겠다.
배깅을 활용한 모델 -> 랜덤 포레스트
부스팅(Boosting)
Boosting은 가중치를 활용하여 약 분류기와 강 분류기로 나누어주는 방법이다. Bagging과는 다르게 한 모델들의 예측이 다른 모델의 예측에 영향을 줄 수 있다.
하나의 모델이 예측을 하면 예측값에 따라 데이터에 가중치가 부여되고, 그 가중치가 다른 모델의 예측에 영향을 준다.
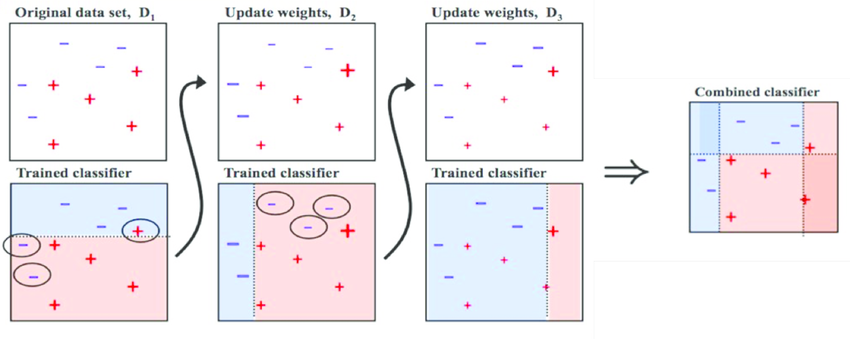
위의 그림의 살펴보자.
1. 중간보다 살짝 위에 가로선을 그어 데이터를 분류했다.
- 위의 영역의 (+)1개와 아래 영역의 (-)2개가 잘못 분류됐다.
- 잘못 분류된 데이터들의 가중치를 크게 하고 제대로 분류된 데이터들의 가중치를 작게 한다.(가중치가 커지면 데이터의 크기가 커짐을 확인할 수 있다.)
- 가중치가 커진 데이터는 다음 모델에서 더 중요하게 다뤄진다.
- 1단계에서 가중치가 커진 데이터들에 중점을 둬서 분류하여 왼쪽으로 치우쳐진 세로선을 그었다.
- 오른쪽 영역의 (-)3개가 잘못 분류되어 이들의 가중치가 커졌다.
- 1,2단계에서 커진 가중치들을 고려해서 오른쪽에 치우쳐진 세로선으로 데이터를 분류했다.
- 1,2,3단계를 종합하여 최종 Classifier를 구한다.
Ada Boost
위에서 설명한 내용이 에이다 부스트에 관한 것이다. 각 weaker model을 순차적으로 적용하며 제대로 분류된 샘플은 가중치를 낮추고 잘못 분류된 샘플은 가중치를 높이는 방식이다.
Gradient Boost
각 weaker model을 순차적으로 적용하며 잘못 분류된 샘플의 에러를 optimization하는 방식이다.
Bagging과 Boosting 차이
독립성
Bagging은 각 모델들이 독립적이어서 병렬로 학습이 되지만 Boosting은 모델들의 학습이 다른 모델에 영향을 주기에 순차적으로 학습된다. 오답에는 높은 가중치, 정답에는 낮은 가중치를 주는 것이다.
성능과 속도
Boosting이 Bagging에 비해 에러가 적고, 성능이 뛰어나다. 그러나 속도가 느려 시간이 오래 걸리고, 오버피팅이 될 수 있다.
=> 상황에 맞게 선택해서 쓰도록 한다.
(성능문제->Boosting, 오버피팅문제-> Bagging)
Bagging은 모델의 bias를 유지하고 variance를 줄여준다.
배깅의 단점
- 복원 추출이기에 중복이 가능하여 독립의 보장이 없다.
- 공분산이 0이라는 조건이 없어서 비슷한 Tree가 만들어질 확률 높다.
- Tree가 증가하여 모델 전체의 분산이 증가할 수 있다.
-> 분산 줄이기 위해 나온 모델이 Random Forest이다.
실습
Voting
class sklearn.ensemble.VotingClassifier(estimators, *, voting='hard', weights=None,
n_jobs=None, flatten_transform=True, verbose=False)
Parameter
- estimators: 리스트 형식으로 튜플 형식의 앙상블할 classifier를 넣어준다.
- voting: voting 방식(hard or soft) default값은 hard이다.
Bagging
배깅의 파라미터와 코드는 아래의 링크를 참고하라.
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html
Ada Boosting
class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, *,
n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
GBM(Gradient Boosting Machine)
class sklearn.ensemble.GradientBoostingClassifier(*, loss='deviance',
learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse',
]min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None,
random_state=None, max_features=None, verbose=0, max_leaf_nodes=None,
warm_start=False, presort='deprecated', validation_fraction=0.1,
n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
이전 knn실습에 추가로 진행했다. 그러나 데이터가 워낙 적어서 정확도는 대부분 같게 나왔다.
Parameter
- loss: 경사하강법에서의 비용 함수 - 기본값인 'deviance' 주로 사용
- learning_rate: 학습률 - 기본값은 0.1 작을수록 성능 굿, 시간 오래걸림 / 클수록 성능 떨어지고 시간 줄어듦
- n_estimators: weak learner의 개수 - 기본값은 100 / 개수 많을수록 성능 굿, 시간 오래걸림
- subsample: weaker learner가 학습에 사용하는 데이터의 샘플링 비율 - 기본값은 1 / 0.5라면 학습 데이터의 50%를 샘플링한다. 과적합시 1보다 작은 값 선택.
출처
- https://velog.io/@gr8alex/Ensemble-Learning
- https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-11-%EC%95%99%EC%83%81%EB%B8%94-%ED%95%99%EC%8A%B5-Ensemble-Learning-%EB%B0%B0%EA%B9%85Bagging%EA%B3%BC-%EB%B6%80%EC%8A%A4%ED%8C%85Boosting
- https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-4-%EA%B2%B0%EC%A0%95-%ED%8A%B8%EB%A6%ACDecision-Tree?category=1057680
- http://blog.naver.com/PostView.nhn?blogId=qbxlvnf11&logNo=221488622777&categoryNo=0&parentCategoryNo=0&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postView
- https://libertegrace.tistory.com/entry/Classification-2-%EC%95%99%EC%83%81%EB%B8%94-%ED%95%99%EC%8A%B5Ensemble-Learning-Voting%EA%B3%BC-Bagging
- https://pangyo-datascientist.tistory.com/23
