SVM의 정의
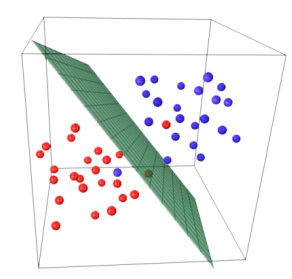
SVM(Support Vector Machine)은 주어진 데이터가 어디에 속하는지 분류하는 이진 선형 분류 모델이다. N차원의 공간을 (N-1)차원으로 나눌 수 있는 초평면을 찾는 분류 기법이다. 초평면은 경계를 뜻하며, 특히 2차원 뿐만 아니라 고차원에서도 분류할 수 있는 경계를 의미한다.
- 2차원인 평면에서 데이터를 분류하는 경계(초평면)는 1차원인 직선이다.
- 3차원인 입체에서는 데이터를 분류하는 경계(초평면)가 2차원인 평면일 것이다.
Margin
Margin(마진)은 클래스들 사이의 간격, 즉 각 클래스의 끝에 위치한 데이터들 사이의 거리를 의미한다.
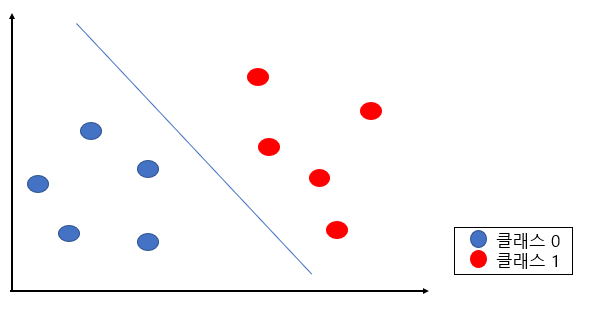
위와 같이 두 개의 클래스로 분류되는 데이터들이 있을 때 최적의 경계는 직관적으로 생각했을 때 저 직선이 될 것이다.
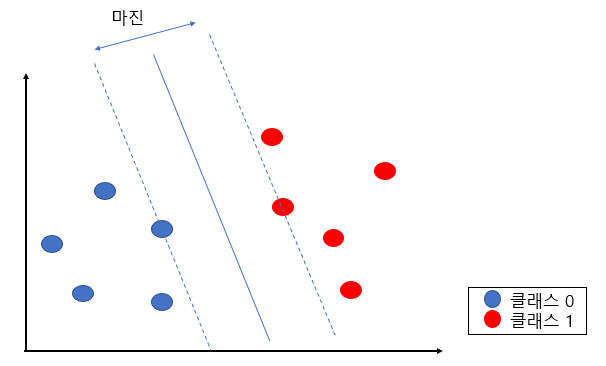
최적의 경계는 마진이 최대화되는 경계이다.
Support Vector는 마진에서 가장 가까이 위치한, 즉 각 클래스들의 끝에 있는 데이터를 지칭한다. 위의 그림에서 점선에 걸쳐진 두 데이터가 서포트 벡터라고 볼 수 있다. 이 데이터들의 위치에 따라 경계(초평면)의 위치가 달라지기에 초평면 함수를 지지한다는 뜻에서 서포트 벡터라는 이름을 가진다고 한다.
SVM의 종류
SVM는 선형으로 분류가 가능한 경우와 불가능한 경우에 따라 다른 종류가 쓰인다.
선형SVM
하드마진
하드마진은 두 클래스를 분류할 수 있는 최대마진의 초평면을 찾는 방법이다. hard인만큼 오차를 절대 허용하지 않는다. 즉 모든 데이터는 마진 밖에 있어야 한다. 그러나 모든 데이터를 오차없이 나누는 경계를 찾는 것은 쉽지 않다.
소프트마진
하드마진의 단점을 보완하는 방식이 소프트마진이다. 즉 일정한 오차나 잘못된 분류를 허용한다. 이를 위해 Slack Variable을 사용한다. Slack Variable의 크기만큼 초평면의 위, 아래로 오차를 허용한다.
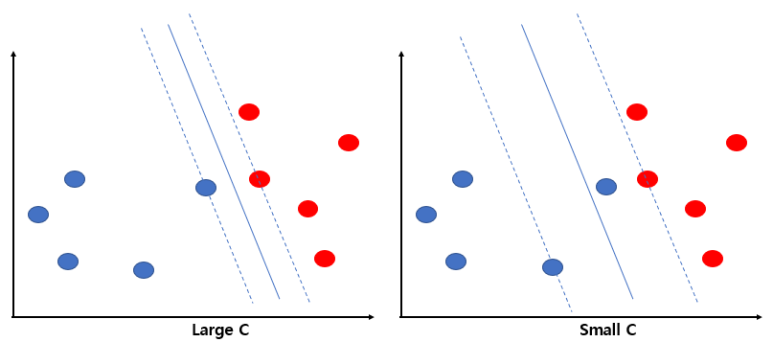
- Parameter인 C를 통해 slack variable의 총합에 제한을 두어 조정할 수 있으며, 이는 과적합 방지에 도움이 된다.
- C가 커질수록 오류에 엄격해지고 마진이 줄어들어 오류가 줄지만 과적합이 발생할 수 있다.
- C가 작아질수록 오류에 관대해지고 마진이 커져 과소적합의 위험이 생길 수 있다.
비선형SVM
선형분리가 불가능한 데이터셋에서 데이터의 차원을 높여서 선형분리를 진행한 후 다시 기존의 입력공간으로 변환하는 과정이다.
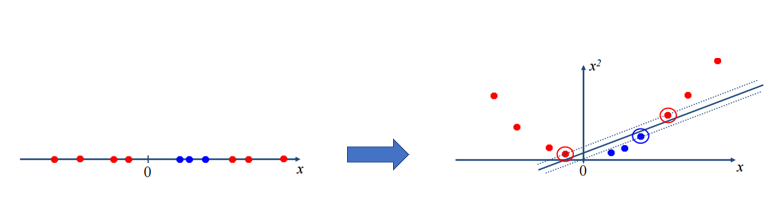
위와 같이 선형분리가 불가능한 1차원의 데이터를 2차원의 평면으로 바꾸어 선형분리가 가능하도록 한다.
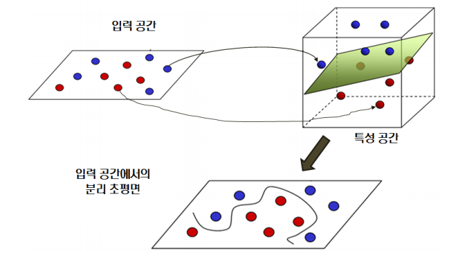
위의 그림은 2차원의 데이터를 3차원의 특정공간으로 변환하여 선형분리가 가능하도록 한 후 2차원의 초평면으로 분류한 것이다.
- 차원 변환에는 mapping function이 쓰인다.
- Kernel Trick: 고차원일수록 계산량이 크게 늘어 줄이기 위한 방식이다. 실제로 데이터의 특성을 확장하지 않고 확장한 것처럼 만들어 계산하는 방식이다.
- linear, polynomial,radial basis function, sigmoid 등이 커널함수의 종류이며, linear이 가장 많이 쓰인다.
- RBF(Radial Basis Function)이 성능이 가장 좋으며, 입력공간을 무한대의 특정공간으로 보내는 방식이다. 이 때는 C가 쓰이지 않고 Gamma라는 파라미터가 쓰인다. Gamma는 하나의 데이터의 영향력을 결정한다.
- Gamma가 커지면 경계의 곡률이 커져 과적합이 발생하며, 작아지면 경계가 직선에 가까워져 과소적합이 발생한다.
- Polynomial은 사용자가 직접 차수를 정하는 방식이다.
실습
from sklearn import svm
svm_clf = svm.SVC(kernel='linear', C=1.0)
svm_clf.fit(X_train, y_train)
y_predict_train = svm_clf.predict(X_train)
train_score = accuracy_score(y_train, y_predict_train)
y_predict_test = svm_clf.predict(X_test)
test_score = accuracy_score(y_test, y_predict_test)
print("train accuracy: {0:.3f}".format(train_score))
print("test accuracy: {0:.3f}".format(test_score))Parameter
- C: 오차의 허용 정도를 나타낸다.
- kernel: 어떤 커널함수를 사용할지 나타낸다.
linear, sigmoid, rbf, poly - degree: poly일 경우에만 사용된다. 차수를 결정한다.
- gamma: 곡률 경계를 나타낸다.
rbf, poly, sigmoid에서 튜닝하는 값이다.
SVM의 장단점
장점
- 과적합을 피할 수 있다.
- 저차원이나 고차원의 적은 데이터에서 일반화 능력이 좋다.
- 데이터 특성이 적어도 성능이 좋게 나오는 편이며, 잡음에 강하다.
단점
- 커널함수의 선택이 명확하지 않다.
- 고차원으로 갈수록 계산이 부담이 된다.
- 데이터 특성의 스케일링에 민감하다.
- 파라미터 조절을 잘해야 최적의 모델을 구할 수 있다.
출처
- https://blog.naver.com/PostView.nhn?blogId=winddori2002&logNo=221667083964&parentCategoryNo=&categoryNo=&viewDate=&isShowPopularPosts=false&from=postView
- https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-2%EC%84%9C%ED%8F%AC%ED%8A%B8-%EB%B2%A1%ED%84%B0-%EB%A8%B8%EC%8B%A0-SVM?category=1057680
