Metrics의 정의
사이킷런에 있는 서브패키지로, 분류문제의 여러 성능평가 명령을 제공한다. 일반적으로 정확도(accuracy_score)를 많이 사용하는데, 이밖에도 여러 종류의 성능평가 지표가 있다.
Confusion Matrix(오차 행렬)
타겟의 정답인 클래스와 모형이 예측한 클래스가 얼마나 일치하는지 세서 표로 나타낸 것이다.
행(row)은 정답 클래스, 열(column)은 예측 클래스가 들어간다.

- TN: 실제 클래스가 0일 때 예측 클래스도 0인 경우
- TP: 실제 클래스가 1일 때 예측 클래스도 1인 경우
- FP: 실제 클래스가 0일 때 예측 클래스는 1인 경우
- FN: 실제 클래스가 1일 때 예측 클래스는 0인 경우
위 사진은 Confusion Matrix 중에서도 클래스가 0과 1밖에 없는 Binary Confusion Matrix에 해당한다.
y_answer = [0,0,1,1,2,2]
y_predict = [1,0,2,0,2,1]
confusion_matrix(y_answer, y_predict)Accuracy(정확도)
전체 샘플 중에서 맞게 예측한 샘플의 비율을 뜻한다.
- 데이터가 불균형한 경우에는 사용에 주의해야 한다.
- True가 99%, False가 1%라고 예를 들면 늘 True로 예상해도 정확도가 99%이다.
Precision(정밀도)
양성 클래스(클래스 1)에 속한다고 예측한 샘플 중 실제로 양성 클래스에 속한 샘플의 비율을 뜻한다.
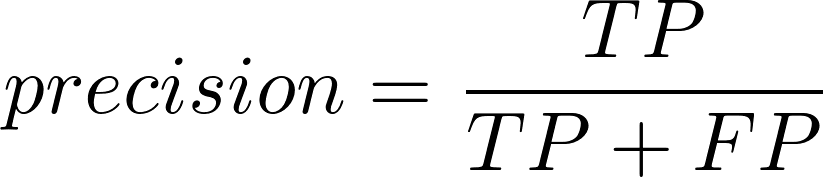
Recall(재현율)
양성 클래스에 속하는 표본 중에서 양성 클래스에 속한다고 예측한 샘플의 비율을 뜻한다. TPR(True Positive Rate), Sensitivity(민감도)라고도 한다.

정밀도와 재현율
- 재현율과 정밀도는 실제 양성, 음성 클래스의 비율과 관련이 있다.
- 정밀도 재현율 Trade-off: 한쪽을 높이면 한쪽이 떨어진다.
- 실제 양성인 데이터를 음성으로 잘못 예측했을 때 영향이 큰 경우
-> 재현율이 중요한 지표 ex) 암진단 - 실제 음성인 데이터를 양성으로 잘못 예측했을 때 영향이 큰 경우
-> 정밀도가 중요한 지표 ex) 스팸메일 판단
Fall-out(위양성율)
실제 양성 클래스에 속하지 않은 샘플 중 양성 클래스에 속한다고 예측한 샘플의 비율을 뜻한다. 실제로는 정상인데 비정상이라고 예측하는 정도라고 생각하면 된다. 낮을수록 좋은 지표이다. FPR(거짓 양성 비율)이라고도 한다.
특이도(Specificity) = 1 - Fall-out
FPR = FP / (FP + TN)
재현율과 위양성율은 오차 행렬에서 실제 클래스끼리 계산하기에 클래스 비율의 영향을 받지 않아 유용하다.
F-score(F-점수)
Precision(정밀도)와 Recall(재현율)의 가중조화평균을 뜻한다. 이 때 정밀도에 가해지는 가중치를 beta라고 한다. 특히 beta=1인 경우 F1-score라고 한다.

ROC(Receiver Operator Characteristic) Curve
클래스를 분류하는 기준값이 변할 때 위양성률과 재현률이 어떻게 변하는지 시각화한다.
- 재현률을 높이려면?
양성으로 판단하는 기준을 낮추어 양성으로 예측하는 양을 늘리면 된다. - 이럴 경우 실제로는 음성인데 양성으로 예측한 표본도 증가한다.
-> 위양성률이 증가한다.
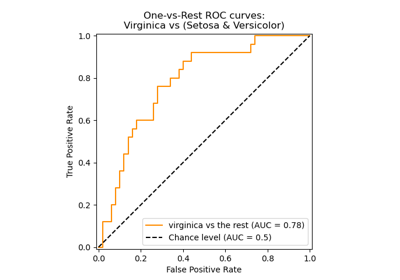
AUC(Area Under Curve)
ROC의 면적을 의미한다. 위양성률이 같을 때 재현률이 높을수록, 또는 재현률이 같을 때 위양성률이 낮을수록 ROC는 1에 가까워지며 더 좋은 모형이다.
출처
