본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.
Bag-of-Words Representation
1) 문장에 등장하는 단어들을 포함하는 vocabulary 구성 (중복제거)
sentences : "John really really loves this movie", "Jane really likes this song"
Vocabulary : {"John","really","loves","this","movie","jane","likes","song"}
2) vocabulary 속 단어들을 one-hot vectors로 encoding
Vocabulary : {"John","really","loves","this","movie","jane","likes","song"}
John : [1 0 0 0 0 0 0 0]
really : [0 1 0 0 0 0 0 0]
loves : [0 0 1 0 0 0 0 0]
this : [0 0 0 1 0 0 0 0]
movie : [0 0 0 0 1 0 0 0]
jane : [0 0 0 0 0 1 0 0]
likes : [0 0 0 0 0 0 1 0]
song : [0 0 0 0 0 0 0 1]
모든 단어 쌍에서 거리가 , cosine similarity가 0
- Cosine similarity 공식
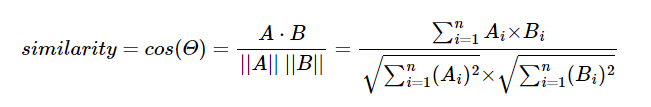
One-hot vectors의 합을 이용하면, 문장이나 문서를 나타낼 수 있음
Sentence : "John really really loves this movie"
John + really + really + loves + this + movie = [1 2 1 1 1 0 0 0]
NaiveBayes Classifier for Document Classification


-
class 별 확률
P() = =
P() = = -
문장 가 class에 속할 확률 계산
P(|) = P() P(W|) 0.00001
P(|) = P() P(W|) 0.0001
