본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.
What is Word Embedding?
"하나의 단어를 하나의 벡터로 표현한 것"
비슷한 의미를 가진 단어가 좌표 공간상 비슷한 위치에 mapping 되게 함으로써 단어들의 의미상 유사도를 반영한 벡터 표현
Word2Vec
가장 유명한 word embedding
같은 문장에 나타난 인접한 단어들 간 의미가 비슷할 것이라고 가정하고, 인접 단어들로부터 단어에 대한 벡터 표현을 학습을 통해 결정하는 알고리즘
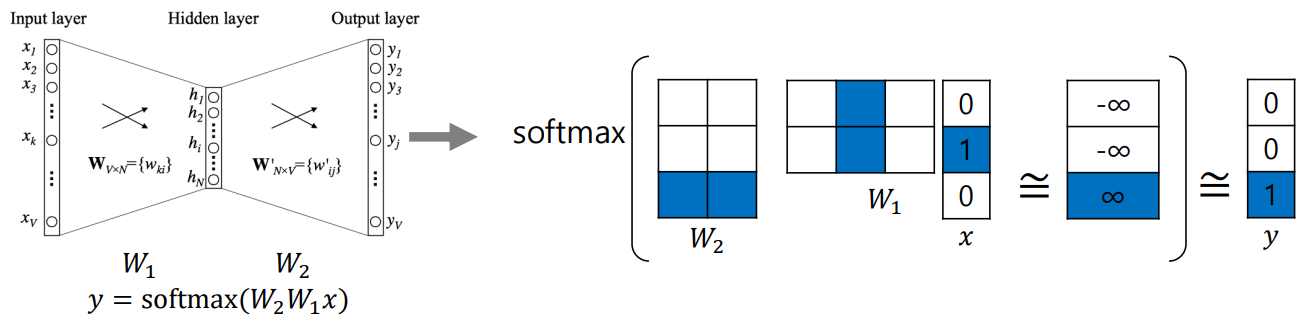
: vocabulary size -> hidden size (hyperparameter)
: hidden size -> vocabulary size의 열, 의 행이 각 단어를 나타냄
- sentence : "I study math."
- Vocabulary : {"I","study","math"}
- Input : "study" [0 1 0]
- Output : "math" [0 0 1]
에서 'study' vector와 에서 'math' vector의 내적값은 큰 값을 가져야 함
Application of Word2Vec
Word2Vec은 NLP 대부분의 연구 분야에서 성능을 향상시킴
- Word similarity
- Machine translation
- Part-of-speech (PoS) tagging
- Named entitiy recognition (NER)
- Sentiment analysis
- Clustering
- Semantic lexicon building
- Image Captioning
GloVe: Global Vectors for Word Representation
- Word2Vec과 Glove의 차이점
| Word2Vec | GloVe |
|---|---|
| 특정 입출력 단어 쌍이 자주 등장하는 경우, 학습을 통해 두 word embedding 내적값이 커지도록 학습됨 | 학습 전, 단어 쌍이 한 윈도우 내에서 총 몇번 동시에 등장하는지 횟수를 미리 계산하고 학습 |
-
Glove 장점
중복되는 계산을 줄여줌 (중복되는 단어 쌍)
Word2Vec에 비해 빠르고, 보다 적은 data에서도 잘 동작하는 특성이 있음
-
Loss function
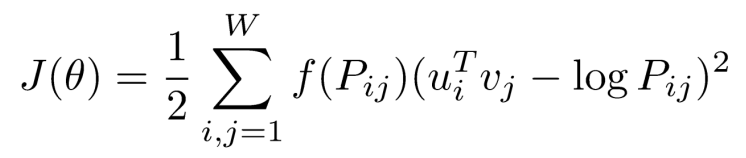
: 두 단어가 한 윈도우 내에서 몇번 동시에 나타나는지에 대한 값

머신러닝 엔지니어를 꿈꾸는 부스트캠퍼입니다🙏