BootStrap
출처 : 데이터 과학을 위한 통계학
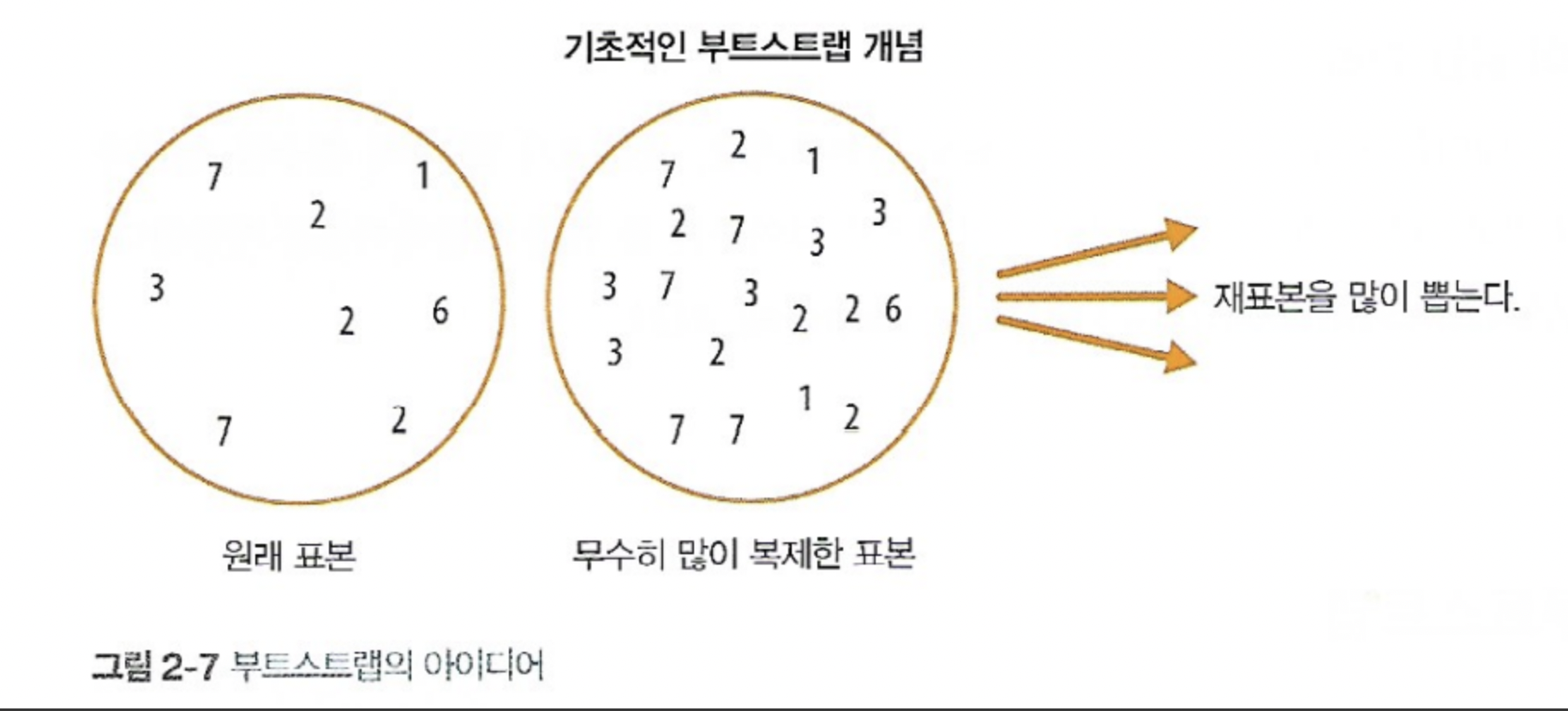
가설 검증(test)을 하거나 메트릭(metric)을 계산하기 전에 임의복원추출을 적용하는 방법을 일컫는다.
딱 하나의 통계치를 얻고 싶으면 전체의 평균을 구하면 된다.
그런데 만약 평균의 신뢰구간을 구하고 싶은데, 데이터를 수집했던 확률변수의 정확한 분포를 모르는 경우, 측정된 통계치의 신뢰도를 가늠할 방법이 없다.
이럴 때 부트스트랩을 사용한다고 한다.
측정된 데이터 중에서 중복을 허용하여 설정한 만큼 뽑고, 그들의 평균을 구해 저장한다. 그럼 표본에서 복원추출로 뽑은 데이터의 평균의 분포를 구할 수 있게 되고, 이로부터 신뢰구간을 파악할 수 있다.
이렇게 원래의 분포를 모르는 경우 외에도, 측정된 샘플이 부족한 경우에도 사용할 수 있다고 한다. 또 t분포와 같은 경우에는 모집단이 정규분포를 따라야 한다는 것이 전제되는데, 부트스트랩의 경우 그렇지 않아 편리하다고 한다.
🚨 다만 좋은 점만 있는 것은 아니고, 잘 모르고 쓴다면 결과가 일관적이지 않을 수 있고, 지원하는 소프트웨어도 별로 없으며, 쓰여진 통계량에 많이 의존한다고 한다.
출처 : https://en.wikipedia.org/wiki/Bootstrapping_(statistics)#Advantages
실습
출처 : KHUDA 박선우 선생님 <3
아쉬운 것은 데이터가 너무 커서 올릴 수 없다는 점.
#https://scikit-learn.org/stable/modules/generated/sklearn.utils.resample.html
#-> resample 이 bootstraping을 지원한다고 한다
from sklearn.utils import resample
loans_income = data2['annual_inc'][:100000]
results = []
for nrepeat in range(1000):
#resample는 Datetime Index를 원하는 주기로 나누어주는 메서드이다
#https://wikidocs.net/158101
#실습: resample을 이용해보자
sample = resample(loans_income)######
#실습: sample의 median을 리스트에 추가하자
results.append(sample.median())######)
results = pd.Series(results)
print('Bootstrap Statistics:')
print(f'original: {loans_income.median()}')
print(f'bias: {results.mean() - loans_income.median()}')
print(f'std. error: {results.std()}')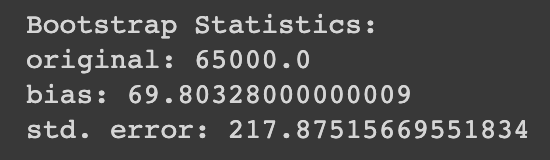
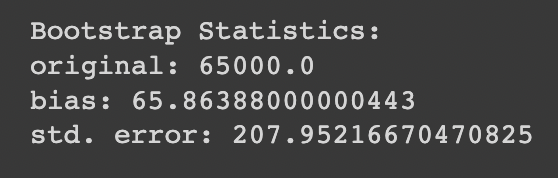
이렇게 보면 매 시행마다 표본편향이나 표준오차가 약간씩 다르게 나온다는 사실을 알 수 있다.
부트스트래핑으로 구한 표본을 통해서 모집단의 신뢰구간을 구해볼 수 있다.
