Feature Engineering
기존 데이터셋(시가, 고가, 저가, 종가, 거래량)에서 기술적 지표(추세, 변동성, 거래량, 모멘텀)를 적용
만든 데이터셋에서 활용하고자 하는 시점에 대한 수익률, 변화율, 변동성을 적용
Data Load
import datetime
import sys
import os
import re
import io
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import ta
import sys
sys.path.append('/aiffel/aiffel/fnguide/data/')
from libs.feature_importance import importance as imp
from sklearn.feature_selection import SequentialFeatureSelector, RFECV
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier, VotingClassifier
DATA_PATH = '/aiffel/aiffel/fnguide/data/'
anno_file_name = os.path.join(DATA_PATH, 'sub_upbit_eth_min_tick_label.pkl')
target_file_name = os.path.join(DATA_PATH, 'sub_upbit_eth_min_tick.csv')
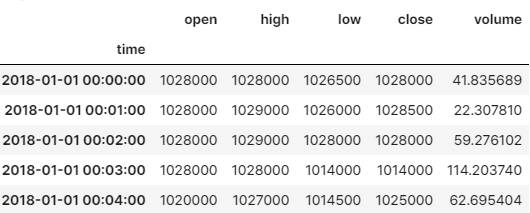
df_modify_data = pd.read_csv(target_file_name, index_col=0, parse_dates=True)
df_label_data = pd.read_pickle(anno_file_name)
df_sub_modify_data = df_modify_data.loc[df_label_data.index]
# 1000개의 데이터만 가져옴
df_sub_modify_data = df_sub_modify_data.iloc[:1000]
df_sub_modify_data.head()
Technical Index
지표
시장의 주가 또는 거래량 데이터를 기반으로 주가의 향방을 예측하기 위해 고안된 지표
추세 지표
MACD(Moving Average Convergence/Divergence)
: 단기 이동평균선 과 장기 이동평균선 의 차이로 주가의 수렴 / 확산 정도를 나타내는 지표
('signal', 'average', 'diverence')로 구성됨.
ADX(Average Directional Movement)
: 금일의 주가 움직임의 범위가 전일의 범위를 어느 방향으로 벗어났는지를 관찰, 추세의 강도를 추적하는 지표
TRIX(Triple Exponential)
: n-영업일 지수가중평균을 3번 연달아 실시한 후, 그 값의 기울기를 나타낸 지표
DPO(detrended price oscillator)
: 가장 최신의 가격 흐름에 반응하지 않도록 변위된 이동평균을 사용하여, 장기추세를 제거하기 위한 지표
중기 과매수 / 과매도 정도를 표시
AROON
: 추세의 강도와 변화를 식별하기 위한 지표, 고가사이의 시간차와 저가사이의 시간차를 측정
변동성 지표
ATR(Average True Range)
: 시장의 변동성을 측정하기 위한 지표, (고가 - 저가), (고가 - 전일종가)의 절대값, (저가 - 전일종가)의 절대값 중 큰값을 취하여, 이동평균
UI(Ulcer Index)
: 가격 하락의 유지기간, 깊이를 통해 가격의 하락 위험을 측정하는 지표
거래량 지표
CMF (Chaikin Money Flow)
: 산출방식이 MACD와 유사, 두 accumulation/distribution line의 EMA값의 차이를 통해 돈의 유입/유출을 파악하려는 지표
MFI (Money Flow Index)
: 가격의 흐름과 거래량의 조합으로 모멘텀의 방향성을 나타내는 지표
FI (Force Index)
: 가격과 거래량을 사용하여 가격의 움직임을 좌우하는 힘의 강도를 측정하는 지표
SMA EM (Ease of Movement)
: 가격의 상승/하락을 판단하기 위한 지표. 가격의 변동성과 거래량을 통해 가격 흐름의 용이성을 측정
VPT(Volume Price Trend)
: 가격의 변화 강도와 그 방향을 나타내는 지표. 수요 / 공급의 균형을 측정
모멘텀 지표
RSI(Relative Strength Index)
: 가격 흐름의 상대강도를 측정하는 지표. 일정기간 내의 평균 수익과 손실의 강도를 비교함.
WR(Williams %R)
: 과매도 / 과매수를 측정하는 지표(-100 ~ 0). 진입 / 청산 시점을 포착하는데 사용됨.
TA 패키지를 이용하여 지표 산출
mt = 1
fillna = False
df_ = df_sub_modify_data.copy()
open, high, low, close, volume = 'open', 'high', 'low', 'close', 'volume'
cols = [open, high, low, close, volume]
## Volume Index
# Chaikin Money Flow
df_["volume_cmf"] = ta.volume.ChaikinMoneyFlowIndicator(
high=df_[high], low=df_[low], close=df_[close], volume=df_[volume], window=20*mt, fillna=fillna
).chaikin_money_flow()
# Force Index
df_["volume_fi"] = ta.volume.ForceIndexIndicator(
close=df_[close], volume=df_[volume], window=15*mt, fillna=fillna
).force_index()
# Money Flow Indicator
df_["volume_mfi"] = ta.volume.MFIIndicator(
high=df_[high],
low=df_[low],
close=df_[close],
volume=df_[volume],
window=15*mt,
fillna=fillna,
).money_flow_index()
# Ease of Movement
df_["volume_sma_em"] = ta.volume.EaseOfMovementIndicator(
high=df_[high], low=df_[low], volume=df_[volume], window=15*mt, fillna=fillna
).sma_ease_of_movement()
# Volume Price Trend
df_["volume_vpt"] = ta.volume.VolumePriceTrendIndicator(
close=df_[close], volume=df_[volume], fillna=fillna
).volume_price_trend()
## volatility index
# Average True Range
df_["volatility_atr"] = ta.volatility.AverageTrueRange(
close=df_[close], high=df_[high], low=df_[low], window=10*mt, fillna=fillna
).average_true_range()
# Ulcer Index
df_["volatility_ui"] = ta.volatility.UlcerIndex(
close=df_[close], window=15*mt, fillna=fillna
).ulcer_index()
## trend index
# MACD
df_["trend_macd_diff"] = ta.trend.MACD(
close=df_[close], window_slow=25*mt, window_fast=10*mt, window_sign=9, fillna=fillna
).macd_diff()
# Average Directional Movement Index (ADX)
df_["trend_adx"] = ta.trend.ADXIndicator(
high=df_[high], low=df_[low], close=df_[close], window=15*mt, fillna=fillna
).adx()
# TRIX Indicator
df_["trend_trix"] = ta.trend.TRIXIndicator(
close=df_[close], window=15*mt, fillna=fillna
).trix()
# Mass Index
df_["trend_mass_index"] = ta.trend.MassIndex(
high=df_[high], low=df_[low], window_fast=10*mt, window_slow=25*mt, fillna=fillna
).mass_index()
# DPO Indicator
df_["trend_dpo"] = ta.trend.DPOIndicator(
close=df_[close], window=20*mt, fillna=fillna
).dpo()
# Aroon Indicator
df_["trend_aroon_ind"] = ta.trend.AroonIndicator(close=df_[close], window=20, fillna=fillna).aroon_indicator()
## momentum index
# Relative Strength Index (RSI)
df_["momentum_rsi"] = ta.momentum.RSIIndicator(close=df_[close], window=15*mt, fillna=fillna).rsi()
# Williams R Indicator
df_["momentum_wr"] = ta.momentum.WilliamsRIndicator(
high=df_[high], low=df_[low], close=df_[close], lbp=15*mt, fillna=fillna
).williams_r()
Feature Selection
MDI
Tree 계열 분류기에서 산출되는 Feature Importance 값을 사용한 Feature Selection 기법
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Feature Importance 확인
importances = model.feature_importances_
MDA
Tree 외의의 분류기에서도 사용가능한 Feature Selection 기법
모델의 기본 성능을 측정 후 특성을 무작위로 섞은 후 성능을 평가하는 방법 >> 성능 감소가 클수록 중요한 Feature
RFE CV
Data Set을 K개로 분할하여 학습과 검증을 동시에 진행
검증시 Feature의 기여도에 따라 삭제 여부를 결정하는 방식
svc_rbf = SVC(kernel='linear', probability=True)
rfe_cv = RFECV(svc_rbf, cv=cv)
rfe_fitted = rfe_cv.fit(X_sc, y)
rfe_df = pd.DataFrame([rfe_fitted.support_, rfe_fitted.ranking_], columns=X_sc.columns).T.rename(columns={0:"Optimal_Features", 1:"Ranking"})
rfe_df
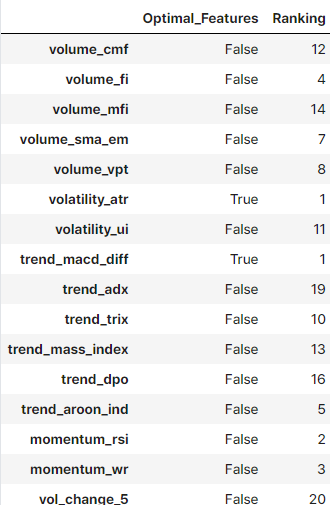
# 선택된 특성
rfe_df[rfe_df["Optimal_Features"]==True]
SFS
순차적으로 Feature를 더하거나 빼는 방식으로 Feature의 최적조합을 찾는 방식
Forward: Null에서 시작하여, Feature를 하나씩 더해가는 방식으로 조합을 찾습니다.
Backwrd: 모든 Feature에서 시작하여 하나씩 빼가는 방식으로 조합을 찾습니다.
n = 2
sfs_forward = SequentialFeatureSelector(svc_rbf, n_features_to_select=n, direction='forward')
sfs_fitted = sfs_forward.fit(X_sc, y)
sfs_rank = sfs_fitted.get_support()
sfs_df = pd.DataFrame(sfs_rank, index=X_sc.columns, columns={"Optimal_Features"})
sfs_df [sfs_df ["Optimal_Features"]==True].index

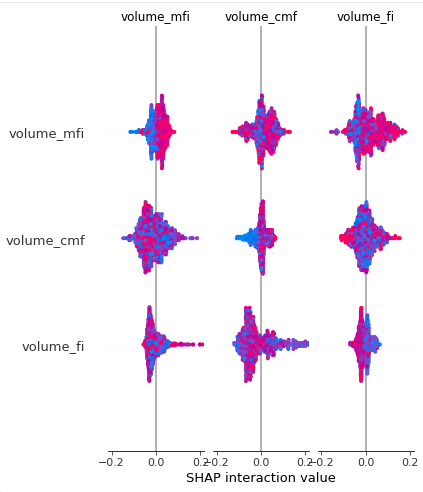
SHAP (Shapley Additive explanations)
각 특성의 Shapley Value를 구하여 중요도를 평가함
import shap
explainer = shap.TreeExplainer(rfc)
shap_value = explainer.shap_values(X_sc)
shap.summary_plot(shap_value, X_sc)