수치형 데이터
처리방식
표준화(StandardScaler)
- 평균이 0, 분산이 1인 표준정규분포로 변환하는 기법

방법
평균과 표준편차를 사용하여 각 특성 값 변환
특징
- 데이터의 크기나 범위에 상관 없이 모델이 학습할 수 있음
- 표준화는 데이터의 분포를 그대로 유지하기에 만약 원본 데이터가
정규 분포라면 표준화 데이터도 정규분포를 따름- 선형 회귀, 로지스틱 회귀, SVM, KNN 알고리즘에서 많이 쓰임
- 이상치에 민감함
정규화(Min-Max)
- 데이터의 범위를 일정한 구간으로 압축하는 기법

방법
특성의 최소값과 최대값을 사용하여 범위 변환
특징
- 각 특성값의 범위를 동일하게 맞추기에 값의 크기에 따라 영향을 받지 않음
- 이상치가 있을때 분포정도가 왜곡될 수 있음
- 신경망 및 딥러닝 알고리즘에서 많이 쓰임
표준화(StandardScaler)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit_transform(df[['가격']])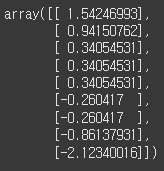
컬럼이 여러 개일 때
cols = ['가격', '호수', '칼로리']
ss = StandardScaler()
df[cols] = ss.fit_transform(df[cols])
df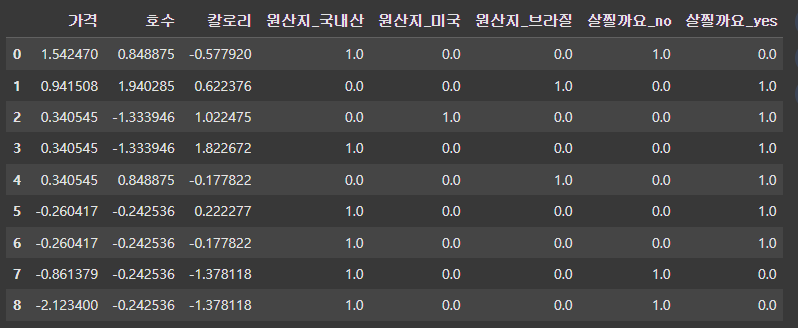
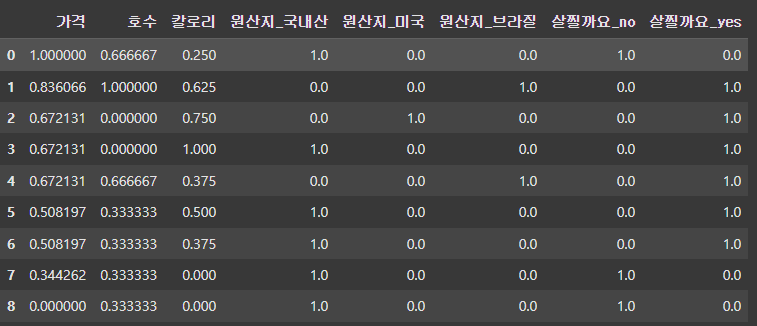
정규화(MinMaxScaler)
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
cols = ['가격', '호수', '칼로리']
df[cols] = mm.fit_transform(df[cols])
df