scikit-learn이란?
데이터 분석(예측)을 위한 간단하고 효율적인 도구
scikit-learn 종류
분류 (스팸 메일)
회귀 (가격)
클러스터링 (고객 세그먼트)
차원 축소 (변수의 수를 줄임)
모델 선택 (모델 튜닝 평가)
데이터 전처리 (데이터 가공 / 변환)
사용 데이터
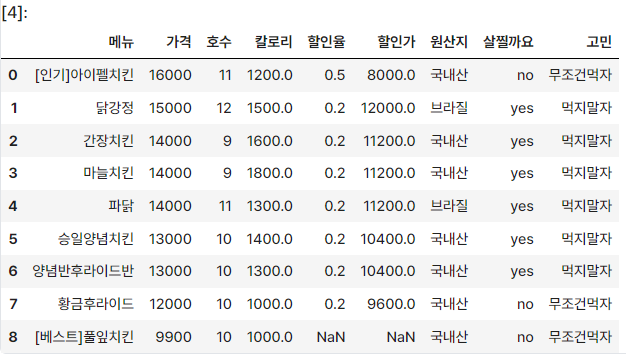
데이터 변경
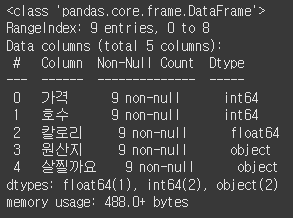
data.loc[2,'원산지'] = '미국'df = data[['가격', '호수', '칼로리', '원산지', '살찔까요']].copy()데이터 전처리
범주형 데이터
데이터 형식이 숫자가 아닌 범주형으로 되어 있으면 학습이 진행이 되지 않음
M/L을 사용하기 위해 범주형 >> 숫자형으로 변경해야 함
처리 방식
- Label Encoding
- 특정 컬럼의 값을 0, 1, 2로 변경함(미국 : 1, 한국 : 2 일본 : 3)
- 변수의 고유한 값이 많지 않으면 좋음
- 순서 관계가 없는 범주형 변수에 사용할 경우 잘못 해석 할 수 있음
(미국이 한국보다 더 중요한 변수라고 여길 수 있음)
- One hot Encoding
- 특정 컬럼의 값을 전부 0, 1로 변경(해당 과정에서 컬럼의 개수가 늘어남)
- 순서가 없는 데이터셋에 주로 사용함
- 차원의 저주 존재(컬럼의 개수가 너무 많음)
Label Encoding
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['원산지'] = le.fit_transform(df['원산지'])

컬럼이 여러개일 경우
cols = ['원산지', '살찔까요']
from sklearn.preprocessing import LabelEncoder
for col in cols:
le = LabelEncoder()
df[col] = le.fit_transform(df[col])
df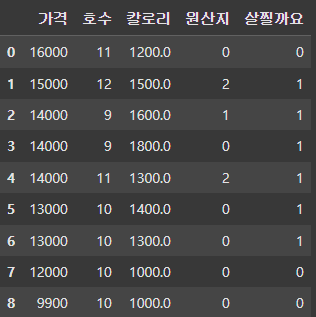
컬럼의 type이 object인 경우도 따로 뽑을 수 있음
cols = df.select_dtypes(include = 'object').columnsOne hot Encoding(ver.Scikit learn)
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse_output=False) # Array형태로 반환해줌
cat = ohe.fit_transform(df[['원산지']])
cat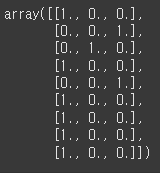
주의! Df형태로 입력을 받기에 대괄호 2번 써줘야함
카테고리 조회
ohe.categories_
원래 컬럼 이름 + 카테고리
ohe.get_feature_names_out()
데이터 프레임 생성 및 합치기
df_cat = pd.DataFrame(cat, columns = ohe.get_feature_names_out())
df = pd.concat([df, df_cat], axis = 1)
df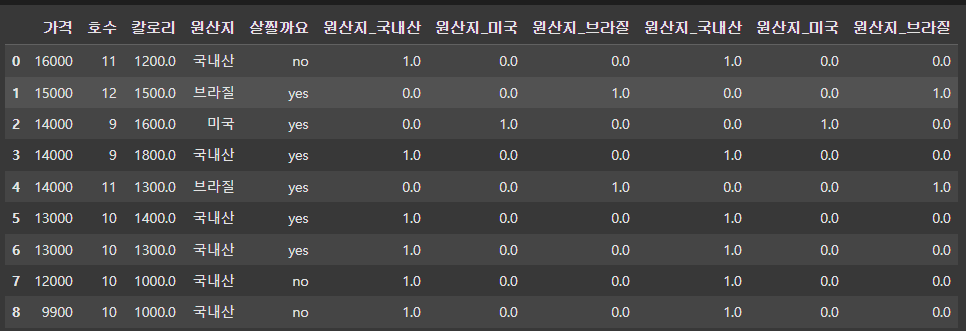
필요 없는 데이터 Drop
df = df.drop(['원산지'], axis = 1)컬럼이 여러개일 경우
cols = df.select_dtypes(include = 'object').columns
ohe = OneHotEncoder(sparse_output = False)
cat = ohe.fit_transform(df[cols])
df_cat = pd.DataFrame(cat, columns = ohe.get_feature_names_out())
df = pd.concat([df, df_cat], axis = 1)
df = df.drop(cols, axis = 1)
One hot Encoding(ver.Pandas)
생각보다 엄청 간단하다
df = pd.get_dummies(df)
df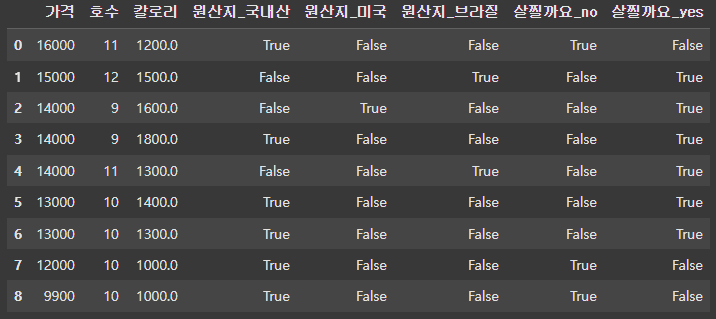
True, False는 Colab에서 진행 하였기에 상관 x
