학습/테스트 데이터 셋
test_data를 분리하지 않고 train data만 학습시킨 후 예측을 하게되면 결과가 1.0이 나오게 됨(과적합)
모의 고사 답을 알고 있는 상황에서 똑같은 모의 고사를 본 격
x_train, y_train, x_test, y_test = train_test_split(
x.data,
x.target,
test_size = 0.3,
random_state - 121,
shuffle = True
)shuffle : 데이터를 분리하기 전 데이터를 섞을지의 여부(Default = True)
random_state : 설정하지 않으면 실행할 때 마다 다른 세트가 나옴
But. 해당 방법만으로는 과적합 문제를 해결 할 수가 없음.
고정된 데이터 셋으로 계속 학습하게 되면 편향된 모델이 만들어짐
=> 데이터셋을 별도의 여러 세트로 구성된 train_data, test_data로 나눔
K-Fold Cross Validation
K개의 데이터 폴드 세트를 만들어 K번 만큼 폴드 세트에 학습과 검증을 반복 수행
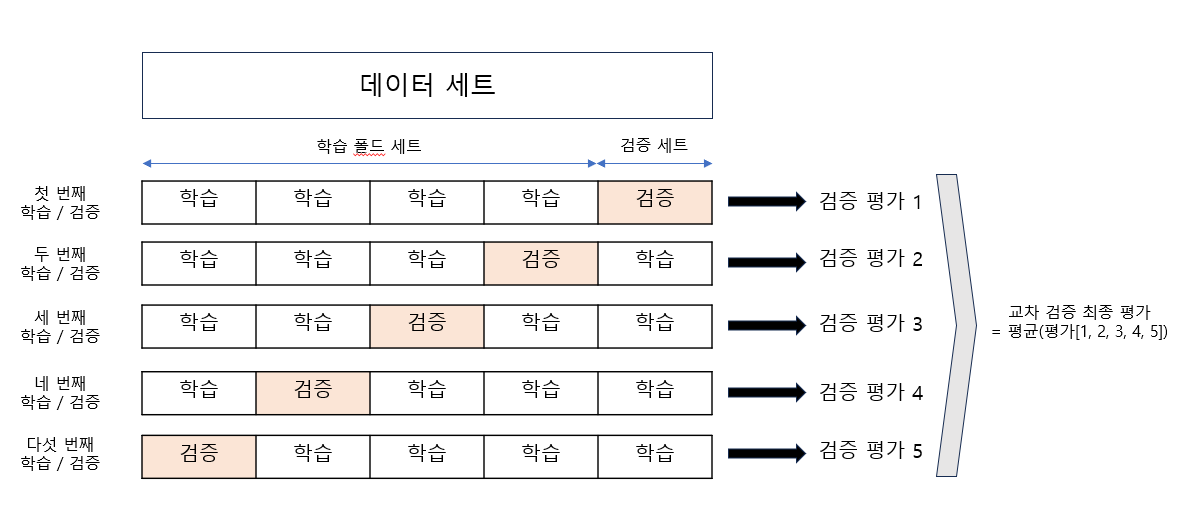
K개의 예측 평가를 구했으면 이를 평균내 K 폴드 평가 결과로 반영
K-Fold in scikit-learn
- KFold
- StratifiedKFold
KFold
관련 패키지 import 및 모델 설정
import numpy as np
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
kf = KFold(n_splits=5, shuffle=True, random_state=42)교차 검증을 위한 모델 설정
model = LogisticRegression(max_iter=200)max_iter=200 : 알고리즘 최대 반복 횟수
교차 검증 진행
accuracies = [] # 각 폴드에서의 정확도를 저장할 리스트
# 각 폴드에 대해 훈련/테스트 데이터 인덱스 분리
for train_index, test_index in kf.split(X):
# 훈련 데이터와 테스트 데이터 분리
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]모델 훈련
model.fit(X_train, y_train)예측 및 정확도 평가
pred = model.predict(X_test)
accuracy = accuracy_score(y_test, pred)
accuracies.append(accuracy)교차 검증 결과 출력
print(f"Accuracy for each fold: {accuracies}")
print(f"Average accuracy: {np.mean(accuracies)}")Error!
ex) 대출 사기 데이터에 1000건의 데이터중 사기인 데이터가 10개라고 가정
KFold방식을 사용하여 나누면 0, 1의 비율이 맞지 않아 특정 train_data에는 사기 데이터가 들어가지 않을 수가 있음
Stratified K Fold
불균형한 분포도(특정데이터의 분포가 치우침)를 가진 데이터를 위한 방식
KFold가 제대로 분배하지 못하는 경우에 사용
관련 패키지 import 및 모델 설정
import numpy as np
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)교차 검증을 위한 모델 설정
model = LogisticRegression(max_iter=200)교차 검증 진행
accuracies = [] # 각 폴드에서의 정확도를 저장할 리스트
# x = 사용 데이터 y = 타겟 변수
for train_index, test_index in skf.split(X, y):
# 훈련 데이터와 테스트 데이터 분리
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]모델 훈련
model.fit(X_train, y_train)예측 및 정확도 평가
pred = model.predict(X_test)
accuracy = accuracy_score(y_test, pred)
accuracies.append(accuracy)교차 검증 결과 출력
print(f"Accuracy for each fold: {accuracies}")
print(f"Average accuracy: {np.mean(accuracies)}")분류 문제에서 교차 검증은 일반적으로 Stratified K Fold를 사용
회귀에서는 Stratified K Fold가 사용되지 않음
cross_val_score
앞서 폴드 세트를 설정, for문 이용 train, test데이터 인덱스 추출, 반복 학습을 통해 예측 성능 반환의 일련의 과정들을 한번에 수행
scores = cross_val_score(model, x, y, scoring = 'accuracy', cv=5)
model : 사용 모델
x : 데이터 셋
y : 타겟 데이터
scoring : 성능 평가 지표
cv : 교차 검증 폴드 개수
- 예제
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# 1. 데이터 로드
data = load_iris()
X = data.data # 특성 데이터 (입력)
y = data.target # 목표 변수 (타겟)
# 2. 모델 설정
model = LogisticRegression(max_iter=200)
# 3. 교차 검증 수행
scores = cross_val_score(model, X, y, scoring = 'accuracy', cv=5) # 5-fold 교차 검증
# 4. 결과 출력
print(f"Accuracy scores for each fold: {scores}")
print(f"Average accuracy: {scores.mean()}")