Decision Tree(결정 트리)
데이터에 있는 규칙을 학습 해 자동으로 찾아내 분류 규칙을 만듦
keyword
지도학습 알고리즘(분류, 회귀)
직관적 알고리즘
과대 적합되기 쉬운 알고리즘(depth 제한 필요)
CART 알고리즘 기반
기본 구조
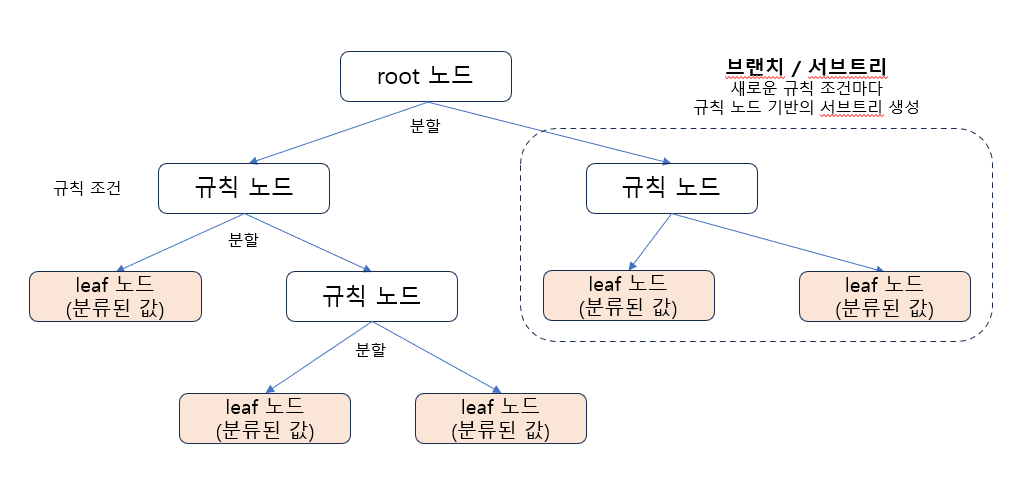
규칙 노드 : 규칙 조건 노드
Leaf 노드 : 결정된 클래스의 값
서브 트리 : 새로운 규칙
규칙이 많아질 수록 복잡해져(깊이가 깊어짐) 과적합에 따른 성능 저하 가능성
parameter
min_samples_split : 노드를 분할하기 위한 최소한 샘플 데이터 개수(Default = 2 / 작게 설정할 수록 과적합 가능성 증가)
min_samples_leaf : 분할 될 경우 오른쪽, 왼쪽의 브랜치 노드에서 가져야할 최소 샘플 데이터 수
(큰값으로 설정할 수록 조건을 만족 시키기 어려워 노드 분할 덜 수행)
max_features : 최적의 분할을 위한 피처 개수
(Default = 모두 사용)
max_depth : 트리의 최대 깊이를 정함
(Default : 없음)
max_leaf_nodes : 말단 노드 개수
정보 균일도
같은 종류의 데이터가 밀집된 정도
결정트리는 정보 균일도가 높은 데이터 세트를 먼저 선택함
정보 균일도 측정 방법 : 정보 이득 지수(엔트로피), 지니계수
정보 이득 지수(엔트로피)
엔트로피 : 주어진 데이터 집합의 혼잡도를 의미함
=> 서로 다른 값이 존재하면 엔트로피 높음
=> 서로 같은 값이 섞여 있으면 엔트로피 낮음
정보 이득 지수 : 1 - 엔트로피 지수
=> 정보 이득 지수가 높은 속성을 기준으로 분할함
지니 계수
경제학에서 불평등 지수를 나타냄
=> 낮을 수록 데이터 균일도가 높음
정보 이득이 높거나 지니 계수가 낮은 조건을 찾아서 자식트리 노드에 걸쳐 반복적으로 분할한 뒤, 데이터가 모두 특정 분류에 속하면 분할을 멈추고 분류 결정
Graphviz
시각화
from sklearn.tree import export_graphviz
import graphviz
# export_graphviz()의 호출 결과로 tree.dot 파일을 생성
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names , \
feature_names = iris_data.feature_names, impurity=True, filled=True)
# tree.dot 파일을 Graphviz 읽어서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)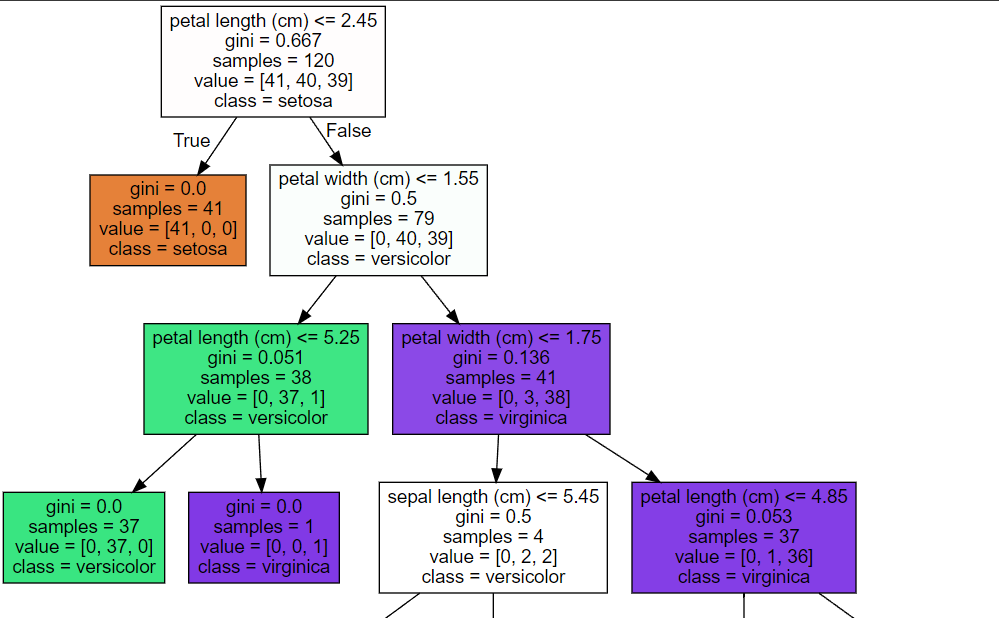
feature 중요도 평가
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names , dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
# feature importance를 column 별로 시각화 하기
sns.barplot(x=dt_clf.feature_importances_ , y=iris_data.feature_names)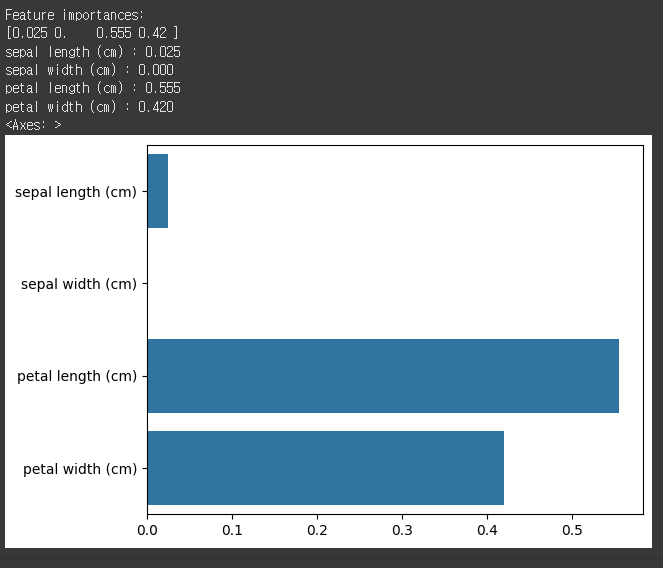
예제
데이터셋
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
def make_dataset():
iris = load_breast_cancer()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df['target'] = iris.target
x_train, x_test, y_train, y_test = train_test_split(
df.drop('target', axis = 1), df['target'], test_size = 0.5, random_state = 1004)
return x_train, x_test, y_train, y_test
x_train, x_test, y_train, y_test = make_dataset()
x_train.shape, x_test.shape, y_train.shape, y_test.shapemodel
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(
criterion = 'entropy',
max_depth = 7,
min_samples_split = 3,
min_samples_leaf = 2,
random_state = 0)
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)