아래는 A 통신사가 다양한 경쟁사가 등장함에 따라 M/S가 떨어지고 있고, 타 통신사로의 이탈률이 높아져가는 상황에서 이탈 가능성이 높은 고객을 분석하는 프로젝트이다.
문제 상황은 이렇다:
🔖
A통신사는 업계 1위의 통신사였으나 그 명성이 무색해져가고 있다. 다양한 경쟁사가 등장함에 따라 M/S가 떨어지고 있고, 타 통신사로의 이탈 고객이
증가하고 있는 상황이다. 이에 이탈 가능성이 높은 고객을 예측하고, 해지 방어 활동들을 전개하려고 한다.
⛳ 문제정의
▶ 고객 이탈
⛳ 기대효과
▶ 고객 이탈 방어
⛳ 해결방안
▶ 이탈 가능성 높은 고객 예측 및 해지 방어
⛳ 성과측정
▶ 이탈 가능성 높은 고객에 대해 관리 전/후 이탈률 모니터링
⛳ 운영
▶ Model에 Input하기 위한 Data mart 생성
데이터셋 정의
# ▶ Data read
import pandas as pd
df = pd.read_csv('S_PJT13_DATA.csv')
df.head()
customerID gender SeniorCitizen Partner Dependents tenure PhoneService \
0 7590-VHVEG Female 0 Yes No 1 No
1 5575-GNVDE Male 0 No No 34 Yes
2 3668-QPYBK Male 0 No No 2 Yes
3 7795-CFOCW Male 0 No No 45 No
4 9237-HQITU Female 0 No No 2 Yes
MultipleLines InternetService OnlineSecurity ... DeviceProtection \
0 No phone service DSL No ... No
1 No DSL Yes ... Yes
2 No DSL Yes ... No
3 No phone service DSL Yes ... Yes
4 No Fiber optic No ... No
TechSupport StreamingTV StreamingMovies Contract PaperlessBilling \
0 No No No Month-to-month Yes
1 No No No One year No
2 No No No Month-to-month Yes
3 Yes No No One year No
4 No No No Month-to-month Yes
PaymentMethod MonthlyCharges TotalCharges Churn
0 Electronic check 29.85 29.85 No
1 Mailed check 56.95 1889.50 No
2 Mailed check 53.85 108.15 Yes
3 Bank transfer (automatic) 42.30 1840.75 No
4 Electronic check 70.70 151.65 Yes
[5 rows x 21 columns]
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure |
|---|---|---|---|---|---|
| 고객ID | 성별 | 노인여부 | 결혼여부 | 부양가족여부 | 회원개월수 |
| PhoneService | MultipleLines | InternetService | OnlineSecurity | OnlineBackup | DeviceProtection |
|---|---|---|---|---|---|
| 전화서비스 여부 | 다회선 여부 | 인터넷 서비스 공급자 | 온라인 보안 여부 | 온라인 백업 여부 | 기기보험여부 |
| TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod |
|---|---|---|---|---|---|
| 기술지원여부 | 스트리밍TV여부 | 스트리밍영화여부 | 계약기간 | 종이없는청구여부 | 결제수단 |
| MonthlyCharges | TotalCharges | Churn |
|---|---|---|
| 월청구금액 | 청구된 총 금액 | 이탈여부 |
데이터 전처리 및 EDA
(1) Data shape(형태) 확인
# ▶ Data 형태 확인
# ▶ 7,043 row, 21 col로 구성됨
print('df', df.shape)
> df (7787, 12)- 7,043 개의 데이터가 있으며 21개의 컬럼으로 이루어져 있음.
(2) Data type 확인
# ▶ Data type 확인
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customerID 7043 non-null object
1 gender 7043 non-null object
2 SeniorCitizen 7043 non-null int64
3 Partner 7043 non-null object
4 Dependents 7043 non-null object
5 tenure 7043 non-null int64
6 PhoneService 7043 non-null object
7 MultipleLines 7043 non-null object
8 InternetService 7043 non-null object
9 OnlineSecurity 7043 non-null object
10 OnlineBackup 7043 non-null object
11 DeviceProtection 7043 non-null object
12 TechSupport 7043 non-null object
13 StreamingTV 7043 non-null object
14 StreamingMovies 7043 non-null object
15 Contract 7043 non-null object
16 PaperlessBilling 7043 non-null object
17 PaymentMethod 7043 non-null object
18 MonthlyCharges 7043 non-null float64
19 TotalCharges 7043 non-null object
20 Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB총 21개의 열 데이터가 있으며 TotalCharges라는 숫자형이나 날짜형 타입의 데이터가 object 문자형 데이터로 선언이 돼있다.
필요에 따라 데이터 분석 진행 시 int 타입으로 변경시키는게 좋을 거 같다.
(3) Null값 확인 (※ 빈 값의 Data)
customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
MonthlyCharges 0
TotalCharges 0
Churn 0
dtype: int64null값이 존재하지 않는 데이터이다.
(4) Outlier 확인 (이상치, 정상적인 범주를 벗어난 Data)
# ▶ Outlier 확인
df.describe()
SeniorCitizen tenure MonthlyCharges
count 7043.000000 7043.000000 7043.000000
mean 0.162147 32.371149 64.761692
std 0.368612 24.559481 30.090047
min 0.000000 0.000000 18.250000
25% 0.000000 9.000000 35.500000
50% 0.000000 29.000000 70.350000
75% 0.000000 55.000000 89.850000
max 1.000000 72.000000 118.750000
min값을 확인해 outlier를 확인해본 결과 존재하지 않는 것으로 보인다.
(5) 데이터 EDA
우량고객 분포 탐색
우량고객이라 함은 이탈률이 낮은 고객군을 의미한다. 그래서 이탈여부를 나타내는 Churn 열의 데이터로 이탈률을 계산하고 이후 장기회원과 프리미엄 요금 이용 회원으로 우량고객의 분포를 살펴보고자 한다.
# ▶ 우량고객이라 함은 이탈률이 낮은 고객군
df['Churn'].value_counts()
Churn
No 5174
Yes 1869
Name: count, dtype: int64이탈하지 않은 고객은 5174명, 이탈한 고객은 1869명이라고 할 수 있다. 이를 아래와 같이 비율로 나타내 이탈률을 계산해보면
# ▶ 약 27%의 이탈률
1869 / (1869 + 5174)
0.2653698707936959전체 고객에서 이탈률은 총 27프로로 나타났다.
이후 데이터 모델링이 필요할 경우를 생각해 Churn 타겟 데이터를 숫자 데이터 0, 1로 변환했다.
# ▶ Target 숫자 데이터로 변환
import numpy as np
df['Churn'] = np.where(df['Churn'] == 'Yes', 1, 0)
df['Churn'].value_counts()
Churn
0 5174
1 1869
Name: count, dtype: int64(1) 장기회원
더 이상의 고객의 이탈률을 낮추기 위해 현재 존재하는 장기회원의 이탈률을 더 낮춰야 할 것이다
따라서 우리는 장기고객일수록 이탈률이 낮을 것이다
라는 가설을 바탕으로 장기회원의 분포를 살펴보고자 한다.
# ▶ 가설1) 장기고객일수록 이탈률이 낮을 것이다.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.style.use(['dark_background'])
sns.distplot(df['tenure']);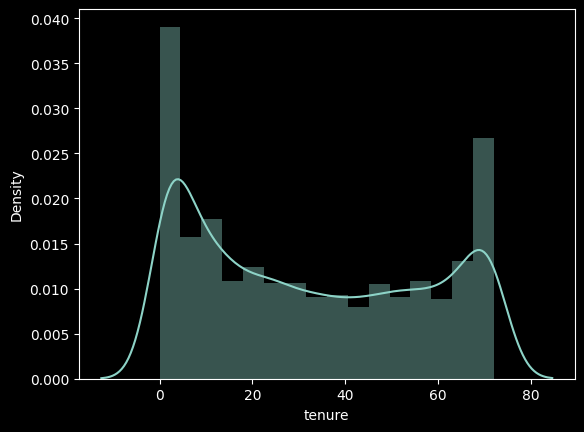
tenure은 회원의 가입 개월 수를 의미하며 총 0~ 70개월까지 가입한 회원들이 존재하는 것으로 보인다. 구간화를 통해서 tenure을 그룹핑하여 각 회원의 가입 개월 수 별로 이탈률을 계산해보자.
# ▶ 구간화
import numpy as np
df['tenure_gp'] = np.where (df['tenure'] <= 20, '20 이하',
np.where(df['tenure'] <= 60, '20-60 이하', '60 초과'))
df[['tenure','tenure_gp']].head(5)
> tenure tenure_gp
0 1 20 이하
1 34 20-60 이하
2 2 20 이하
3 45 20-60 이하
4 2 20 이하
# ▶ 장기고객일 수록 우수고객이다.
df_gp = df.groupby('tenure_gp')['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp['lift'] = round(df_gp['ratio'] / 27,1)
df_gp
count sum ratio lift
tenure_gp
20 이하 2878 1251 43.5 1.6
20-60 이하 2758 525 19.0 0.7
60 초과 1407 93 6.6 0.2구간화를 통해 확인해본 결과 가입 개월 수가 낮을 수록 ratio 즉 이탈률이 높은 것을 확인해볼 수 있으며 가입 개월수가 늘어날 수록 이탈률이 낮은 것을 확인할 수 있다.
이탈률이 27프로인것에 비해서 각 개월 수 그룹별로 몇배 더 이탈률이 높은 것인지 확인해본 결과 20개월 이하는 1.6배나 높은 것을 확인할 수 있다.
(2) 프리미엄 요금 회원
# ▶ 프리미엄 요금 회원일 수록 우수고객이다.
sns.distplot(df['MonthlyCharges']);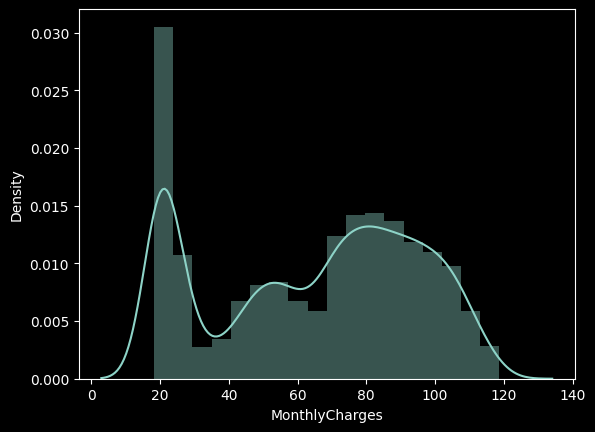
MonthlyCharges은 우수 고객 즉, 프리미엄 회원의 가입 요금을 의미하며 총 20 ~ 120 달러까지 요금을 내고 가입한 회원들이 존재하는 것으로 보인다. 구간화를 통해서 MonthlyCharges을 그룹핑하여 각 회원의 납부 요금 별로 이탈률을 계산해보자.
# ▶ 구간화
import numpy as np
df['MonthlyCharges_gp'] = np.where (df['MonthlyCharges'] <= 40, '40 이하',
np.where(df['MonthlyCharges'] <= 80, '40-80 이하', '80 초과'))
df[['MonthlyCharges','MonthlyCharges_gp']].head(5)
MonthlyCharges MonthlyCharges_gp
0 29.85 40 이하
1 56.95 40-80 이하
2 53.85 40-80 이하
3 42.30 40-80 이하
4 70.70 40-80 이하# ▶ 프리미엄 요금 회원들이 이탈률이 더 높다.
df_gp = df.groupby('MonthlyCharges_gp')['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp['lift'] = round(df_gp['ratio'] / 27,1)
df_gp
count sum ratio lift
tenure_gp
40 이하 1838 214 11.6 0.4
40-80 이하 2539 749 29.5 1.1
80 초과 2666 906 34.0 1.3
구간화를 통해 확인해본 결과 프리미엄 요금을 내는 회원들의 ratio 즉 이탈률이 높은 것을 확인해볼 수 있으며 요금을 적개 내는 회원들의 이탈률이 낮은 것을 확인할 수 있어다.
이탈률이 27프로인것에 비해서 각 요금 그룹별로 몇배 더 이탈률이 높은 것인지 확인해본 결과 80 이상의 요금을 내는 고객의 이탈률이 1.3배나 높은 것을 확인할 수 있다.
그래서 프리미엄 고객의 이탈률이 많아지는 이유에 대해서 생각해볼 필요가 있다.
# ▶ 이용개월수 및 프리미엄 요금 회원 조합에 따른 이탈률 분석
df_gp = df.groupby(['tenure_gp','MonthlyCharges_gp'])['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp
count sum ratio
tenure_gp MonthlyCharges_gp
20 이하 40 이하 873 187 21.4
40-80 이하 1300 597 45.9
80 초과 705 467 66.2
20-60 이하 40 이하 674 26 3.9
40-80 이하 922 140 15.2
80 초과 1162 359 30.9
60 초과 40 이하 291 1 0.3
40-80 이하 317 12 3.8
80 초과 799 80 10.0이용개월수 및 프리미엄 요금 회원 조합에 따른 이탈률 분포에 대해서도 함께 확인해보았다.
가입 개월 수를 기준으로 프리미엄 요금 회원 조합에 따라서도 프리미엄 회원 가입자의 이탈률이 높은 것을 확인할 수 있다.
이탈 고객 특성 분석
고객의 이탈률의 분포에 대한 정보는 대략적으로 확인해보았으며 그렇다면 이탈을 하는 고객의 개별적 특성을 분석해 이탈하는 고객을 분류해보고자 한다. 아래의 세 가지를 분석할 것이다.
**인구통계학적 특성 - 이탈률 분석
부가서비스 사용 - 이탈률 분석
계약 형태, 요금 - 이탈률 분석**
(1) 인구통계학적 특성 - 이탈률 분석
먼저 전체 데이터에서 고객의 개별적 특성을 나타낼만한 데이터들인 별/실버고객/결혼여부/부양가족여부를 데이터 프레임화 한 후 막대 그래프로 분포를 확인해 보았다.
# ▶ 인구통계학적 특성 성별/실버고객/결혼여부/부양가족여부
df[['gender', 'SeniorCitizen', 'Partner', 'Dependents']].head(10)
gender SeniorCitizen Partner Dependents
0 Female 0 Yes No
1 Male 0 No No
2 Male 0 No No
3 Male 0 No No
4 Female 0 No No
5 Female 0 No No
6 Male 0 No Yes
7 Female 0 No No
8 Female 0 Yes No
9 Male 0 No Yes# ▶ gender(성별)
sns.catplot(x="gender", hue="Churn", kind="count",palette="pastel", edgecolor=".6",data=df);
plt.gcf().set_size_inches(10, 3)
df_gp = df.groupby('gender')['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp['lift'] = round(df_gp['ratio'] / ((df['Churn'].sum() / len(df))*100) ,1)
print(df_gp)
count sum ratio lift
gender
Female 3488 939 26.9 1.0
Male 3555 930 26.2 1.0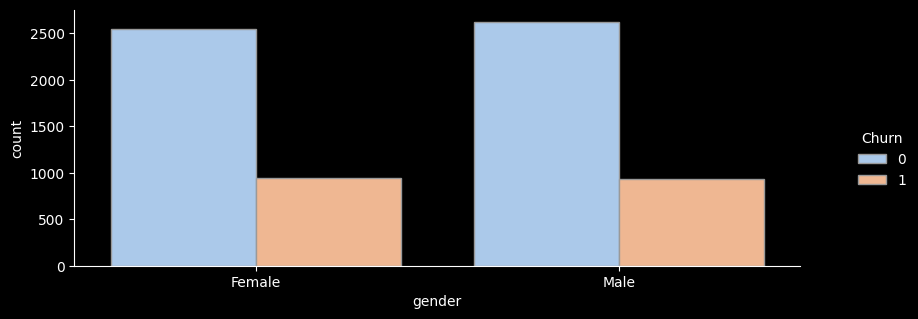
- 성별 이탈률을 확인해보니 성별 이탈률의 차이는 거의 동일하여 큰 의미가 없는 것으로 보인다.
# ▶ SeniorCitizen(노인가구여부)
sns.catplot(x="SeniorCitizen", hue="Churn", kind="count",palette="pastel", edgecolor=".6",data=df);
plt.gcf().set_size_inches(10, 3)
df_gp = df.groupby('SeniorCitizen')['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp['lift'] = round(df_gp['ratio'] / ((df['Churn'].sum() / len(df))*100) ,1)
print(df_gp)
count sum ratio lift
SeniorCitizen
0 5901 1393 23.6 0.9
1 1142 476 41.7 1.6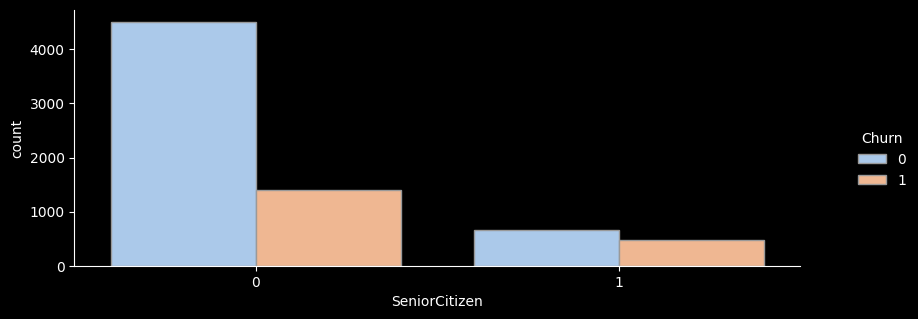
- 노인가구별 이탈률을 확인해보니 노인가구에 해당하는 가입자가 훨씬 더 높은 이탈률을 보이고 있는 것을 확인해볼 수있다.
# ▶ Partner(결혼여부)
sns.catplot(x="Partner", hue="Churn", kind="count",palette="pastel", edgecolor=".6",data=df);
plt.gcf().set_size_inches(10, 3)
df_gp = df.groupby('Partner')['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp['lift'] = round(df_gp['ratio'] / ((df['Churn'].sum() / len(df))*100) ,1)
print(df_gp)
count sum ratio lift
Partner
No 3641 1200 33.0 1.2
Yes 3402 669 19.7 0.7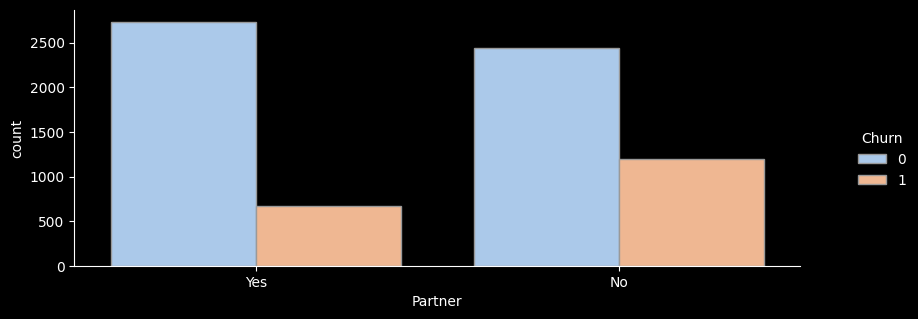
- 결혼여부별 이탈률을 확인해보니 미혼자에 해당하는 가입자가 훨씬 더 낮은 이탈률을 보이고 있는 것을 확인해볼 수있다.
# ▶ Dependents(부양가족 여부)
sns.catplot(x="Dependents", hue="Churn", kind="count",palette="pastel", edgecolor=".6",data=df);
plt.gcf().set_size_inches(10, 3)
df_gp = df.groupby('Dependents')['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp['lift'] = round(df_gp['ratio'] / ((df['Churn'].sum() / len(df))*100) ,1)
print(df_gp)
count sum ratio lift
Dependents
No 4933 1543 31.3 1.2
Yes 2110 326 15.5 0.6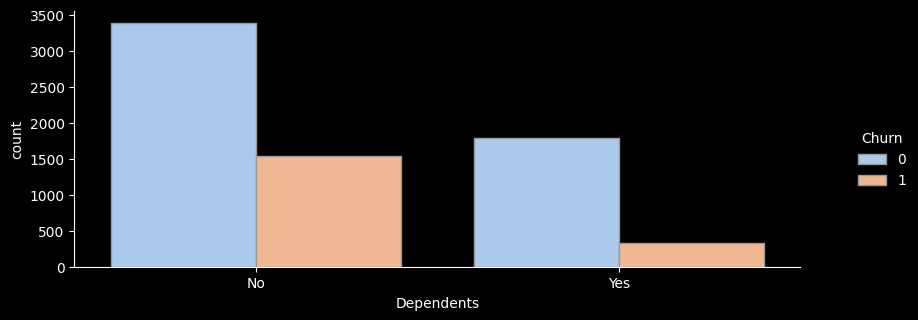
- 부양가족이 있는지 별로 이탈률을 확인해보니 부양가족이 없음에 해당하는 가입자가 훨씬 더 높은 이탈률을 보이고 있는 것을 확인해볼 수있다.
(2) 부가서비스 사용 - 이탈률 분석
먼저 전체 데이터에서 가입 시 부가서비스를 이용하는지 확인할 수 있는 데이터들인 온락인백업서비스/기기보험서비스/기술지원서비스/스트리밍TV/스트리밍영화 서비스데이터 프레임화 한 후 막대 그래프로 분포를 확인해 보았다.
# ▶ 부가서비스 col, 온락인백업서비스/기기보험서비스/기술지원서비스/스트리밍TV/스트리밍영화 서비스
df[['OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']]
OnlineBackup DeviceProtection TechSupport StreamingTV StreamingMovies
0 Yes No No No No
1 No Yes No No No
2 Yes No No No No
3 No Yes Yes No No
4 No No No No No# ▶ for문 활용 한 번에 출력
col_list = ['OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']
for i in col_list :
val = i
sns.catplot(x=val, hue="Churn", kind="count",palette="pastel", edgecolor=".6",data=df);
plt.gcf().set_size_inches(10, 3)
df_gp = df.groupby(val)['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp['lift'] = round(df_gp['ratio'] / ((df['Churn'].sum() / len(df))*100) ,1)
print(df_gp)
print("---------------------------------------")
count sum ratio lift
OnlineBackup
No 3088 1233 39.9 1.5
No internet service 1526 113 7.4 0.3
Yes 2429 523 21.5 0.8
---------------------------------------
count sum ratio lift
DeviceProtection
No 3095 1211 39.1 1.5
No internet service 1526 113 7.4 0.3
Yes 2422 545 22.5 0.8
---------------------------------------
count sum ratio lift
TechSupport
No 3473 1446 41.6 1.6
No internet service 1526 113 7.4 0.3
Yes 2044 310 15.2 0.6
---------------------------------------
count sum ratio lift
StreamingTV
No 2810 942 33.5 1.3
No internet service 1526 113 7.4 0.3
Yes 2707 814 30.1 1.1
---------------------------------------
count sum ratio lift
StreamingMovies
No 2785 938 33.7 1.3
No internet service 1526 113 7.4 0.3
Yes 2732 818 29.9 1.1
---------------------------------------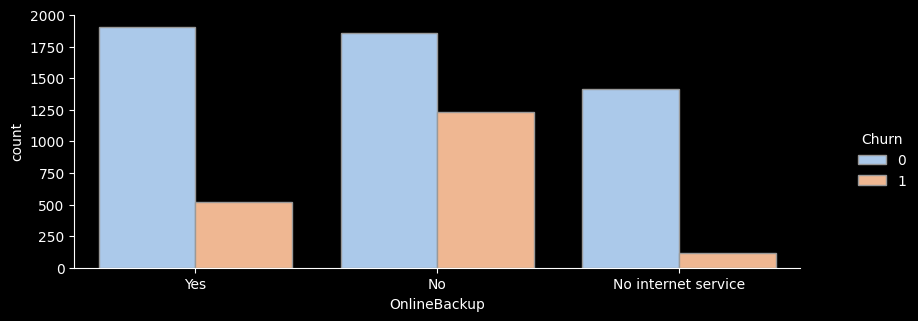
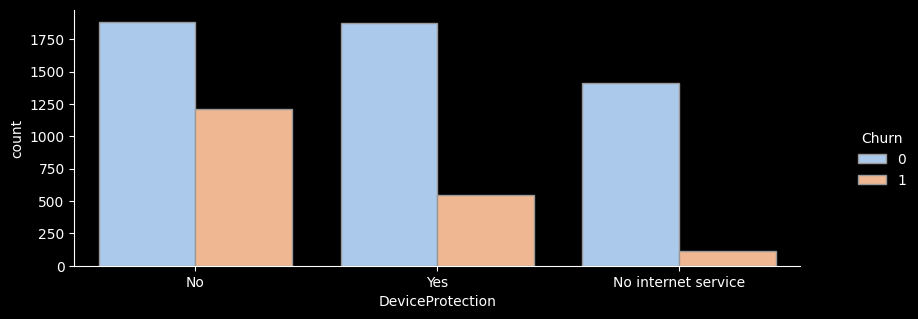
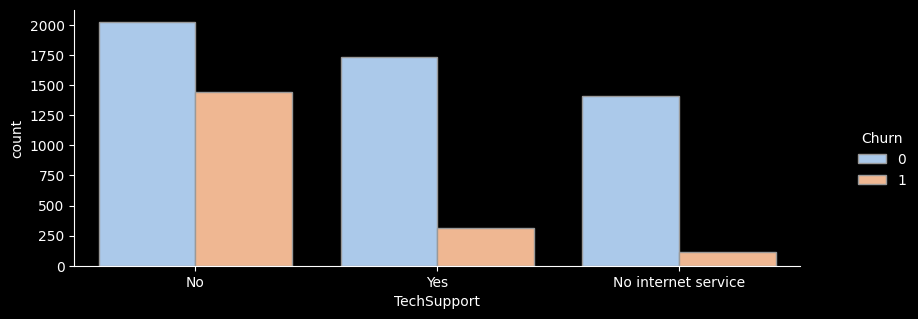
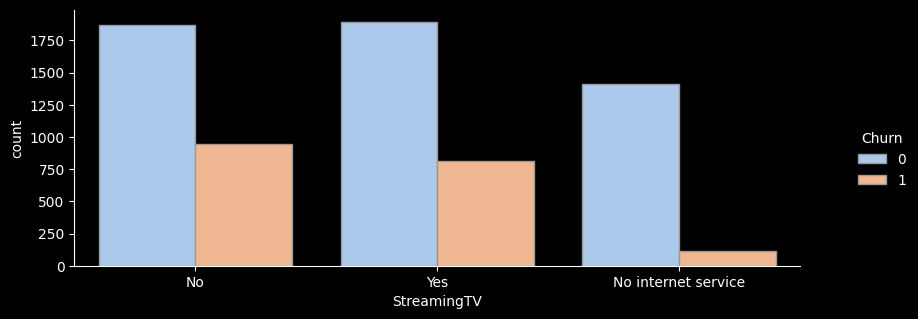
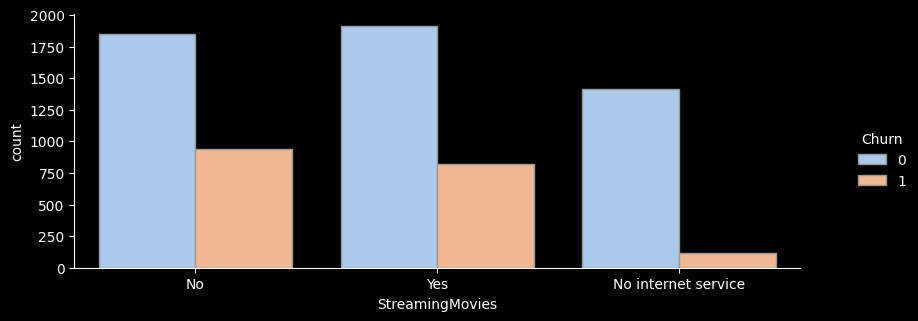
- for문을 활용해 온락인백업서비스/기기보험서비스/기술지원서비스/스트리밍TV/스트리밍영화 서비스 의 이탈률을 한눈에 그래프로 확인해보았다.
- 전체적으로 서비스를 이용하지 않는 고객의 이탈률이 가장 높은 것으로 나타난다.
- 하지만 스트리밍 서비스, 스트리밍 영화 서비스를 이용하는 고객이나 이용하지 않는 고객의 이탈률은 크게 차이가 나지 않는 것으로 보인다.
그래서 전체적으로 부가서비스를 아예 이용하지 않는 고객의 이탈률이 낮은 것을 확인하기 위해 이탈률을 확인해보니
# ▶ 부가서비스를 모두 이용하지 않는 고객에 이탈률 분석
df_no = df[(df['OnlineBackup'] =='No') & (df['DeviceProtection'] =='No') & (df['TechSupport'] =='No') & (df['StreamingTV'] =='No') & (df['StreamingMovies'] =='No')]
df_no[col_list]
OnlineBackup DeviceProtection TechSupport StreamingTV StreamingMovies
4 No No No No No
7 No No No No No
10 No No No No No
36 No No No No No
... ... ... ... ... ...
7026 No No No No No
7032 No No No No No
7033 No No No No No
7040 No No No No No
7041 No No No No No# ▶ 부가서비스 형태가 모두 No인고객은 47.6% 이탈률, Lift 약 1.8
df_no['Churn'].sum() / len(df_no)- 그래서 부가서비스를 모두 이용하지 않는 고객에 이탈률을 분석해본 결과 부가서비스를 모두 이용하지 않는 고객의 이탈률이 모두 47.6%로 절반을 보이며 부가서비스를 이용하지 않는 고객들의 이탈률이 상당히 높은 것을 확인할 수 있었다.
(3) 계약 형태, 요금 - 이탈률 분석
다음으로는 전체 데이터에서 계약형태를 확인할 수 있는 데이터들인 계약기간/종이없는청구/결제수단 등의 데이터를 데이터 프레임화 한 후 분포를 확인해보았다.
# ▶ 계약형태 col, 계약기간/종이없는청구/결제수단
df[['Contract', 'PaperlessBilling', 'PaymentMethod']]
Contract PaperlessBilling PaymentMethod
0 Month-to-month Yes Electronic check
1 One year No Mailed check
2 Month-to-month Yes Mailed check
3 One year No Bank transfer (automatic)
4 Month-to-month Yes Electronic check
... ... ... ...
7038 One year Yes Mailed check
7039 One year Yes Credit card (automatic)
7040 Month-to-month Yes Electronic check
7041 Month-to-month Yes Mailed check
7042 Two year Yes Bank transfer (automatic)# ▶ for문 활용 한 번에 출력
col_list = ['Contract', 'PaperlessBilling', 'PaymentMethod']
for i in col_list :
val = i
df_gp = df.groupby(val)['Churn'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp['lift'] = round(df_gp['ratio'] / ((df['Churn'].sum() / len(df))*100) ,1)
print(df_gp)
print("---------------------------------------------------")
count sum ratio lift
Contract
Month-to-month 3875 1655 42.7 1.6
One year 1473 166 11.3 0.4
Two year 1695 48 2.8 0.1
---------------------------------------------------
count sum ratio lift
PaperlessBilling
No 2872 469 16.3 0.6
Yes 4171 1400 33.6 1.3
---------------------------------------------------
count sum ratio lift
PaymentMethod
Bank transfer (automatic) 1544 258 16.7 0.6
Credit card (automatic) 1522 232 15.2 0.6
Electronic check 2365 1071 45.3 1.7
Mailed check 1612 308 19.1 0.7
---------------------------------------------------- 확인 결과 월 단위 가입자의 이탈률이 당연히 높은 것을 확인 할 수 있다.
- 종이 청구서를 이용하지 않는 고객의 이탈률이 더 높은 것을 확인할 수 있다.
Electonice check를 이용해 결제하는 고객의 이탈률이 가장 많이 높은 것을 확인할 수 있다.
결론
-
넷플릭스는 최근 몇 년 동안 급성장세를 보였으며 2016년을 시작으로 2020년까지 다수의 컨텐츠를 제작하고 있는 것을 확인했다.
-
12월에 가장 많은 컨텐츠가 추가되었으며, 10월 1월에도 비슷한 수준이지만 상대적으로 다른 월에 비해 많은 컨텐츠가 추가된 것을 확인할 수 있다.
-
그래서 10월~내년도 1월까지 특히 연말에 컨텐츠 추가가 집중되는 경향이 있는 것으로 보인다. 이는 연말 시즌에 맞춘 콘텐츠 업데이트 전략을 반영할 수 있을 것으로 보인다.
-
넷플릭스에서 제작된 컨텐츠들은 티비쇼보다는 영화 제작에 더 집중을 하고 있으며 컨텐츠는 대부분을 성인을 타깃으로 하는 컨텐츠를 제작한 것으로 보인다.
-
영화 컨텐츠의 제작 길이는 80분에서 120분 사이의 길이를 가지고 있어 극장 영화보다 짧은 시간의 길이를 가지고 있다.
-
아무래도 미국 회사다 보니 미국이 압도적으로 컨텐츠 제작이 많으며 그 다음은 영화산업이 발달 돼 있는 인도가 위치해 있으며 그 다음으로 영국, 일본이 뒤를 이었다. 이는 넷플릭스의 컨텐츠가 주로 이 세 국가에서 제작됐음을 확인할 수 있다.
- 장르별 컨텐츠의 분포를 확인해보니 가장 인기 있는 장르는
'International Movies'국제 영화와'Dramas'드라마로 나타났디. 이는 넷플릭스가 국제적인 시청자를 대상으로 다양한 영화를 제공하고 있음을 시사한다.
