k-means clustering
데이터를 몇 개의 클러스터로 나누어서 비교적 비슷한 특징을 가지는 각각의 클러스터로 모으는 것을 목표
PCA
디멘션을 줄이기 위한 기법
- EIGENVALUE DECOMPOSITION과 동일한 방식
전통적 머신러닝
- low dimensional data
- simple concepts
- reliable- cluster validation is a must
cluster validation
숫자적으로 의미가 있는지 꼭 확인 필요
전통적 머신러닝에서의 unsupervised learning
상당히 좋은 문제나 연구가 많이 진행이 되긴 했지만, 실제 엡에 사용하기에 걱정이 되는 상황
deep learning
딥러닝의 기원
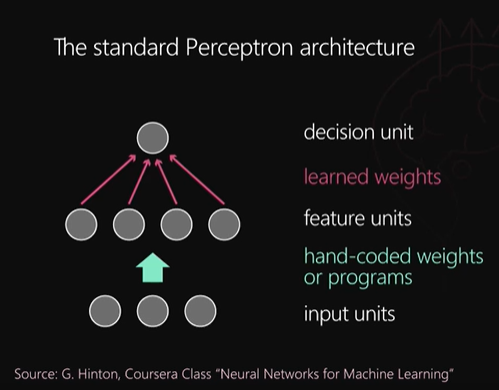
perceptron 같이 단순한 알고리즘을 쓸 때는 데이터 자체의 정보라는 것은 perceptron 같은 단순한 알고리즘으로 좋은 성능을 바로 내기가 어렵기 때문에 raw 데이터(input 데이터) 에서 인간이 가공을 해서 hand cordweight를 통과시키든지 프로그램을 만들어서 그걸 통과시키든지 인간이 수작업을 통해서 중요한 정보들을 잘 정리해주고 이를 충분히 간단한 정보를 중간 layer에 넣어주면, 맨 위에 부분에 있는 perceptron 알고리즘이 좋은 일을 할 수 있다.
feature engineering
필드에서 푸는 문제들에 중요
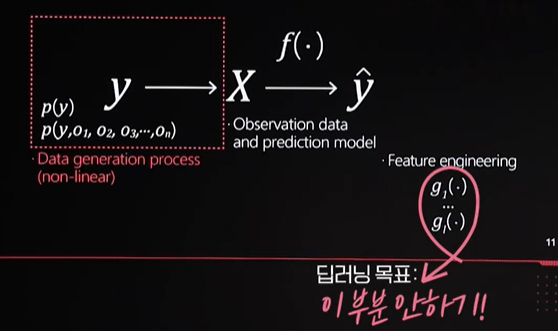
인간이 하는 것이 아닌 알고리즘이 스스로 중요한 정보를 스스로 잘 정리를 해서 y라는 정보를 다시 뽑아내는데 큰 어려움 없이, 마지막에는 linear layer만 집어넣어도 linear한 방식으로 뽑아내는 것이 딥러닝
feature engineering vs representation learning
feature engineering
- by human
- domain knowledge & creativity
- brainstorming
representation learning
- by machine
- deep learning knowledge & coding skill
- trial and error
high dimensional data
- difficult concepts
- not well understood, but surpringly good performance - deep learning
- unsupervised represntation learning
REPRESENTATION
어떤 X라는 개념이 있을 때, 수학적인 기호로 표현하는 RULE들

문과생 데이터사이언티스트되기 프로젝트