딥러닝 학습의 한계점: 대용량 학습 데이터로 부터 학습하는 모델 구조 - 점점 더 복잡해지고 이해하기 어려워짐.
XAI 기법
- 모델 & 데이터셋의 오류 색출
- 모델이 얼마나 편향되어 있는지 확인 가능
XAI
사람이 모델을 쓸 때 그 동작을 이해하고 신뢰할 수 있게 해주는 기계 학습 기술
XAI 분류하는 방법


- intrincsic: 모델의 복잡도를 훈련하기 이전부터 설명하기 용이하도록 제안한 뒤 학습을 시켜서 그 후 학습된 모델을 가지고 설명하는 방법
- post-hoc: 임의 모델의 훈련이 끝난 뒤에 이 방법을 적용해서 그 모델의 행동을 설명하는 방법simple gradient method
입력에 대한 모델의 gradient로 설명을 제공
gradient라는 것이 각 픽셀의 값이 조금 바뀌었을 때 이 함수의 출력 값이 얼마나 빨리 변하는지를 구하는 값
단점: 구한 설명들이 매우 noisy할 수 있다!
smoothgrad
a simple method to address the noisy gradients

CAP ( CLASS ACTIVATION MAP)
saliency map 기반의 설명 가능 방법
- global average pooling이라는 특정한 레이어를 만들고 그것을 활용하여 설명을 제공하는 방법
GAP레이어는 각 activation map의 모든 activation들의 평균을 내는 연산을 뜻한다.

어떤 activation map에 activation이 크게 된다는 것은 map이 주어진 입력과 관련이 많다는 뜻이고 또한 그것을 결합하는 w가 크다는 것도 최종 분류에 큰 영향을 주는 activation이라는 뜻이므로 그것을 결합하면 입력에 대한 예측을 잘 설명하는 방식이 되는 것.
- GAP-FC model
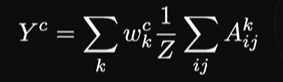
클래스 c에 대한 아웃풋 y를 구하는 방식
CAM의 응용분야
- OBJECT DETECTION
- Semantic segmentation
장단점
strngth
- it clearly shows what objects the model is looking at
weakness
- model-specitic : it can be applied only to models with limited architerture
- it can only be obtained at the last convolutional layer and this makes the interpretation resolution coarse
Grad-CAM
CAM의 단점을 극복하기 위한
CAM을 gradient 정보를 활용해서 확장한 설명 방법
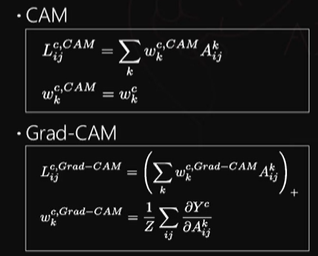
global average pooling 없는 모델에도 activation을 결합하는 방식을 보완
어떤 w가 특정 모델 구조를 가지고 학습된 w를 사용하는 것이 아니라 어느 activation map에서도 그 activation map의 gradient를 구한 다음에 그것의 global average pooling값으로 w를 적용한다는 뜻
학습된 모델이 제대로 학습하고 있는지 또는 이 모델의 예측에 편향성이 존재하지 않는지도 알아낼 수도 있다.
장단점
strngth
- model agnostic : can be applied to various output models
weakness
- average gradient sometimes is not accurate
gradient 값이 크다는 것은 해당 activation에 대한 출력 값의 민감도가 크다는 말이지만 그것이 반드시 그 activation이 최종 결과를 게산하는 데 있어서 중요도를 정확히 반영하지는 않는 뜻
pertubation-based
입력 데이터를 조금씩 바꾸면서 그에 대한 출력을 보고, 그변화에 기반해서 설명
LIME
어떤 분류기가 딥러닝 모델처럼 매우 복잡한 비선형적 특징을 가지고 있더라도 주언진 데이터 포인트들에 대해서는 아주 LOCAL하게는 다 선형적인 모델로 근사화가 가능하다는 관찰에서 출발하고 있다.
주어진 데이터를 조금씩 교란해 가면서 그 교란된 입력 데이터를 모델에 여러 번 통과시킴으로써 나오는 출력을 보고 이렇게 나온 입출력 pair들을 간단한 성형 모델로 근사함으로써 설명을 얻어내는 방법
Black-box
딥러닝 모델뿐 아니라 주어진 입력과 그에 대한 출력만 얻을 수 있다면 어떤 모델에 대해서도 다 적용할 수 있는 설명 방법
단점
- computationally expensive
- hard to apply to certain kind of models
- when the underlying model is still locally non-linear
모델의 구조를 알지 못하는 black-box방법이 어쩔 수 없이 가지게 되는 한계
RISE
lime과 비슷하게 여러번 입력을 perturb해서 설명을 구하는 방법
여러 개의 랜덤 마스킹이 되어 있는 입력에 대한 출력 스코어를 구하고 그 스코어 그러니깐 확률들을 이용해서 이 마스크들을 가중치를 둬서 평균을 냈을 때 나오는 것이 설명 map인 것
XAI
주어진 모델이 어떤 training set으로부터 학습한 것이므로 그 데이터셋에 있는 training image들의 함수라고 볼 수 있고 각 테스트 이미지를 분류하는데 가장 큰 영향을 미친 training image가 해당 분류에 대한 설명이라고 제공을 하는 것
- influence function
평가 방법
1. XAI 방법들이 만들어낸 설명을 보고 비교 평가
ex) AMT test
2. human annotation
some metrices employ human annotations as a ground truth and compare them wuth interpretation
- pointing game
- bounding box를 활용해서 평가하는 방법
- 각 이미지마다 가장 정확도가 높은 픽셀을 활용
- weakly supervised semantic segmentation
- 어떤 이미지에 대해서 classification label만 주어져 있을 때 그것을 활용하여 픽셀별로 객체의 label을 예측하는 semantic segmentation을 수행하는 방법
weakly supervised라고 하는 이유?
: 픽셀별로 정답 label이 다 주어져 있지 않기 때문이다.
loU ( intersection over union)
정답 map과 이렇게 만들어낸 segmentation map이 얼마나 겹치는지를 평가하는 metric
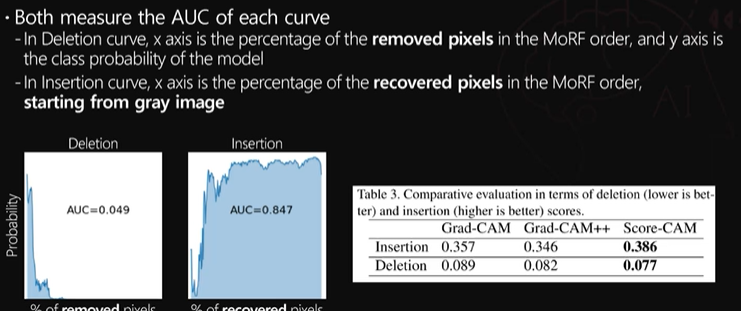
3. pixel perturbation
- AOPC (area over the MORF pertubation Curve )
- 주어진 이미지에 대해서 각각의 XAI기법이 설명을 제공하면 그 제공한 설명의 중요도 순서대로 각 픽셀들을 정렬할 수 있을 것이고 그 순서대로 픽셀을 교란하였을 때 과연 원래 예측한 분류 스코어 값이 얼마나 빨리 바뀌는지를 측정하는 것
insertion and deletion
ROAR (remove and retrain)
ROAR removes some portion of pixels in train data in the order of high interpretation values of the original model, and retrains a new model
장단점
장점
- 조금 더 객관적이고 정확한 평가를 할 수 있다
단점
- 픽셀을 지우고 나서 매번 재학습해야한다
XAI 신뢰성 확인하는 방법
sanity checks
interpretation = edge detector?
