캐글에서 LoRA 학습해보기
파일 설명
- 브레인스토밍, 분류, 폐쇄형 QA, 생성, 정보 추출, 개방형 QA 및 요약을 포함한 여러 행동 범주에서 수천 명의 Databricks 직원이 생성한 지시 따르기 기록의 오픈 소스 데이터 세트
- databricks dolly 15k
라이브러리 및 패키지 설치
!pip install -q -U keras-nlp
!pip install -q -U keras>=3
import os
# 딥러닝 프레임워크의 백엔드와 메모리 관리를 설정
os.environ["KERAS_BACKEND"] = "jax" # Or "torch" or "tensorflow".
# Avoid memory fragmentation on JAX backend.
os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"]="1.00"- KERAS_BACKEND는 Keras가 어떤 딥러닝 엔진을 사용할지 정하는 설정
- "1.00"은 사용 가능한 메모리의 100%를 사용한다는 의미
🖍️ 첫 번째 설정은 "어떤 자동차를 운전할지" 고르는 것과 같음
🖍️두 번째 설정은 "자동차의 연료 탱크를 얼마나 채울지" 정하는 것과 같음
대화형 AI 모델을 훈련시키기 위한 데이터를 준비하는 과정
import keras
import keras_nlp
import json
data = []
with open('/content/databricks-dolly-15k.jsonl') as file:
for line in file:
features = json.loads(line)
# Filter out examples with context, to keep it simple.
if features["context"]:
continue
# Format the entire example as a single string.
template = "Instruction:\n{instruction}\n\nResponse:\n{response}"
data.append(template.format(**features))
#1000개의 데이터만 뽑아서 사용
# Only use 1000 training examples, to keep it fast.
data = data[:1000]케글API
!mkdir -p ~/.kaggle
!echo '{"username":"taixi1992","key":"사용자"}' > ~/.kaggle/kaggle.json
!chmod 600 ~/.kaggle/kaggle.jso모델 다운 및 로딩
import kagglehub
model = kagglehub.model_download("keras/gemma/keras/gemma_2b_en/2")
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
gemma_lm.summary()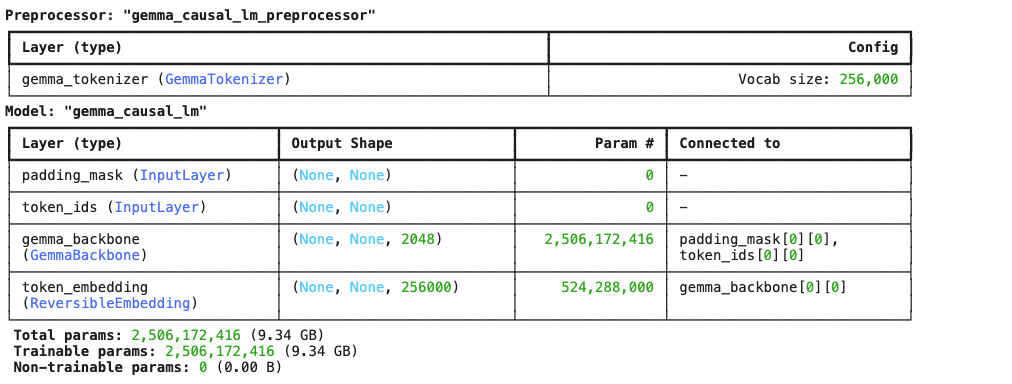
- 25억개의 파라미터 갯수 !!! 엄청난 수
fine tuning 전
prompt = template.format(
instruction="What should I do on a trip to Europe?",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))
prompt = template.format(
instruction="Explain the process of photosynthesis in a way that a child could understand.",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))
- fine tuning 전이라서 학습이 제대로 안되는게 보임
LoRA Fine-tuning
gemma_lm.backbone.enable_lora(rank=8)
gemma_lm.summary()
- 활성화 파라미터를 엄청나게 줄였음 !!!
# Limit the input sequence length to 512 (to control memory usage).
gemma_lm.preprocessor.sequence_length = 512
# Use AdamW (a common optimizer for transformer models).
optimizer = keras.optimizers.AdamW(
learning_rate=5e-5,
weight_decay=0.01,
)
# Exclude layernorm and bias terms from decay.
optimizer.exclude_from_weight_decay(var_names=["bias", "scale"])
gemma_lm.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
gemma_lm.fit(data, epochs=1, batch_size=1)
LoRA Fine-tuning 결과
# Rank(4)
prompt = template.format(
instruction="What should I do on a trip to Europe?",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))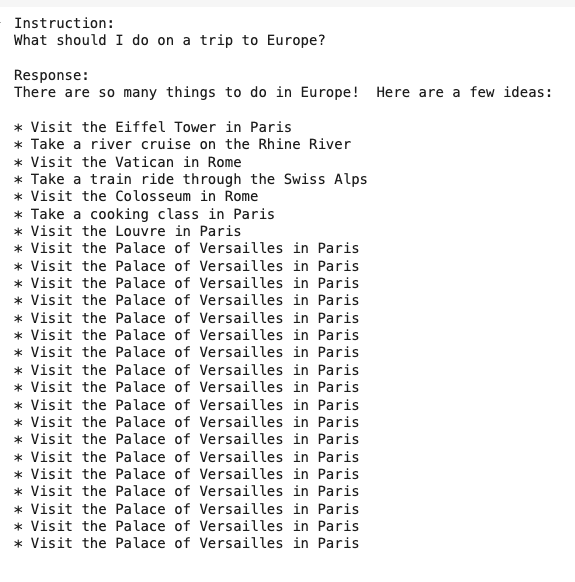
- 전보다는 결과가 좋지만 아직부족한듯하다
# Rank(8)
prompt = template.format(
instruction="What should I do on a trip to Europe?",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))- 랭크를 변경해서 조금더 섬세하게 미세조정을 해봄 ~

# Rank(4)
prompt = template.format(
instruction="Explain the process of photosynthesis in a way that a child could understand.",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))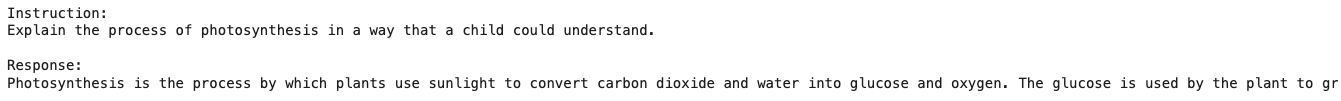
# Rank(8)
prompt = template.format(
instruction="Explain the process of photosynthesis in a way that a child could understand.",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))
랭크4보다는 랭크8로 변경시 결과가 더 좋은거 같다
💡 높은 LoRA 순위는 모델의 세부 조정과 성능 향상에 효과적이며, 복잡한 작업과 데이터셋에서 특히 유용함. 하지만 리소스와 성능 간의 균형을 고려해야 함.
- LoRA를 활성화하면 학습 가능한 매개변수의 수가 크게 감소함
- 학습 가능한 매개변수의 수가 25억 개에서 130만 개로 줄어들음

개발자를 위한 첫시작