두 번째 강의 내용은 loss function과 optimization에 대한 내용이다. 이번에 강의를 들으면서 이전보다 더 깊게 이해할 수 있고 실제 수식도 따라서 계산을 해보니깐 더 잘 이해가 됬다.
우선은 loss function이란 모델의 예측이 얼마나 잘못되었는지를 측정하는 방법으로 이번 강의는 Hinge loss (SVM) 과 corss-entropy loss (Softmax) 에 대한 리뷰를 진행하였음.
Loss function
Hinge loss (SVM)
Hinge Loss는 주로 SVM (Support Vector Machine)에서 사용되는 loss function이다.
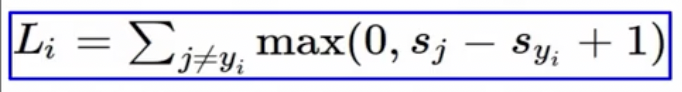
수식을 확인해보면,
- L_i는 i번째 데이터 포인트에 대한 loss
- s_j는 incorrect label score
- s_yi는 correct label score
- max(0, x)를 통해서 x가 양수이면 x를, 그렇지 않으면 0을 반환
그래서 간단하게 해석을 해보면 (correct label score - 1) 보다 큰 incorrect label score가 있다면 loss는 0보다 커지는 것이고, 반대로 correct label score가 incorrect label score 보다 1이상 크면 loss값은 0이 된다는 의미.
추가적으로 간단하게 직접 수식을 통해서 계산을 해본 결과, 결국 각각의 클래스들에 대한 loss를 계산을 하고 모든 클래스에 대한 손실을 합산하고, 클래스 수로 나누어 평균값을 계산한 것이다.
Regularization
하지만 바로 이런 loss function을 적용하는 것이 아닌 실제로 뒤에 lambda 값인 regularization loss를 아래 수식에 보이는 바와 같이 더해주는 것을 확인 가능하다.
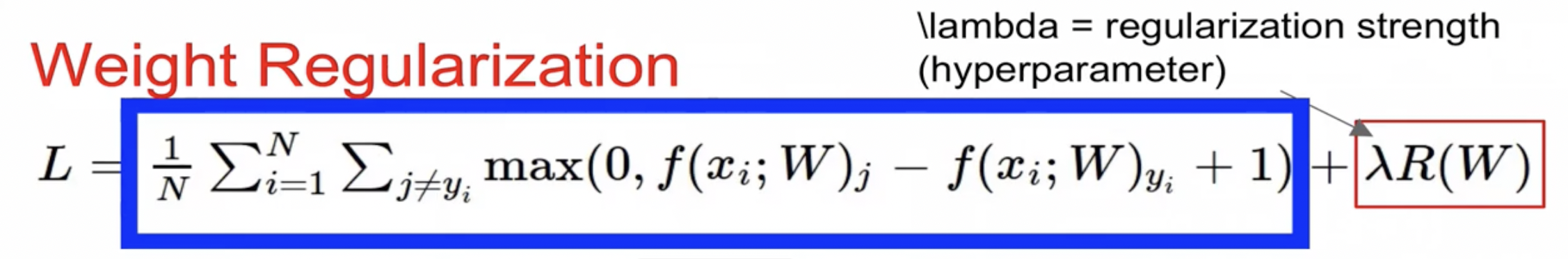
이제 이렇게 regularization loss를 추가해주는 이유는 결국 overfitting 같은 문제로 직면하는 것을 방지하는 것. 식을 보면 알 수 있듯이 Weight값이 커지면 더 큰 loss값을 부여받게 됨. 근데 이 weight가 커진다는 것은 결국 모델이 input feature들에 대해서 매우 민감하게 반응을 한다는 것이고 이것은 모델이 노이즈나 불필요한 복잡한 패턴까지 학습을 할 수도 있다는 것임. 그러면 실제로 중요하지도 않은 정보에도 굉장히 모델이 예민하게 받아들이게 됨.
그래서 이런 정규화 항을 loss function에 추가해줌으로서 모델은 가중치가 큰 값을 갖게 되면 더 높은 loss를 출력을 하기에 모델은 더 낮은 loss 를 달성하기 위해서 weight를 작게 유지하려고 할 것이고, 그러면서 이제 모델은 데이터의 본질적인 패턴을 학습하려고 노력을 하고, 노이즈나 불필요한 복잡한 패턴들은 무시하게 되는거지. 그래서 결론적으로 정규화의 핵심은 모델의 복잡성을 적절히 제어하여, 학습 데이터에 대해 높은 성능을 보이면서도 새로운 데이터에 대해 잘 일반화할 수 있는 균형 잡힌 모델을 생성하는 것.
그래서 결론적으로 앞에 파란색으로 표시된 부분은 data loss를 최소화하는 목적으로 모델이 학습 데이터에 가능한 잘 맞도록 만들어 학습 데이터에 대한 성능을 최대화하지만, 과적합을 유발 할 수 있음. 반면 regularization loss의 경우는 모델이 너무 복잡해지지 않고, 보지 못한 새로운 데이터에 대해서도 잘 작동하도록 해주는 역할을 해준다. 결국 이 두 목표 사이에서 균형을 찾음으로서 하습 데이터에 대해서도 충분히 잘 작동하면서, 새로운 데이터에 대한 일반화능력도 높은 모델을 만드는 것이 목표.
그래서 강의에서는 여러 regularization 기법들에 대한 소개는 자세하게 하지 않았지만 간단하게 많이 사용되는 L2, L1 regularization에 대해서만 리뷰를 해보면:
L2 regularization은 모델의 weight를 제곱해서 모든 weight를 함께 축소하는 방법이다. 큰 weight에 대해 더 큰 패널티를 부과함으로서 모델이 학습 데이터의 미세한 변동보다는 전박적인 패턴을 학습하도록 유도하는 것. L2 regularization은 weight를 완전히 0으로 만들지는 않지만, 모든 가중치를 작게 만들어서 모델이 좀더 부드럽고, 일반화 능력이 높은 예측을 할 수 있게 도와주는 것.
L1 regularization은 모델의 가중치의 절대값을 사용해서 특정 가중치를 0으로 만들어 버린다. 그래서 모델이 가장 중요한 특징만을 사용하도록 만들어서, 결과적으로 sparse한 모델을 생성하게 되는 것임. 대부분의 weight들은 0이고, 오직 일부 중요한 특징에만 가중치가 할당되도록 만들어 줌으로 모델 해석에 용이하다는 특징이 있다.
L1 vs L2: 그래서 둘 중 어떤 것이 더 좋은지 생각해보면, 결국 사용하는 데이터셋에 따라서 달라지지 않을가 싶다. L1 regularization은 모델이 몇몇 중요하지 않은 특징을 무시하도록 만들 때 유용한 것이고, L2 regularization은 모든 특징들이 어느 정도 중요하다고 판단될 때 선택하면 좋을 것이다. 추가적으로 이 두개를 모두 결합한 Elastic net도 있는데, 각 정규화의 장점을 결합해서 모델의 특징 선택과 일반화 능력 동시에 향상시키려고 시도한 방법도 있다고 함.
Cross entropy loss (Softmax)
이번에는 cross entropy loss에 대한 소개다. 이에 사용되는 softmax classifier는 각 클래스에 대한 점수를 확률로 변환해서 가장 높은 확률을 가진 클래스를 모델의 예측으로 사용하는 것이다.
우선은 softmax function에 대해서 수식으로 확인을 해보면 아래와 같다.
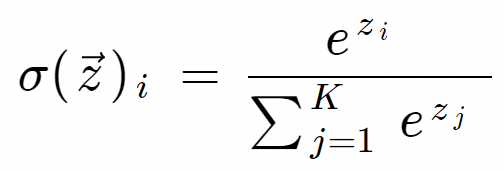
여기서 s_k는 입력 x_i에 대해 클래스 k의 점수이며, e는 자연 상수이다. 분모는 모든 클래스 점수의 지수함수 값의 합으로, 확률들의 합이 1이 되도록 보장해준다.
다음으로 cross entropy loss에 대해서 살펴보면, cross-entropy loss는 모델의 예측이 실제 레이블과 얼마나 잘 일치하는지를 측정하는 것. 실제 클래스에 대한 예측 확률의 음의 로그를 취하여 계산된다.
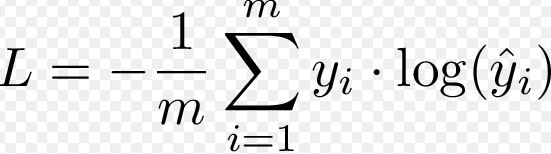
수식에서 y_i는 실제 레이블을 의미하는 것이고, 모델이 실제 클래스에 대해 높은 롹률을 예측할수록, 음의 로그 확률 값은 낮아지게 되고 따라서 loss도 줄어들게 된다. 반면 실제 클래스에 대해 낮은 확률을 예측할수록 Loss는 증가하게 되는 것이다.
강의에서는 cross entropy loss에 정규화항을 추가하지는 않았지만, 이 것도 동일하게 정규화 항을 추가해서 과적합 방지가 가능하다.
이것도 간단한 예시로 계산을 해보면 예를들어,고양이, 자동차, 개구리 3개의 클래스에 대한 점수가 각각 3.2, 5.1, -1.7일 때, softmax 함수는 먼저 각 점수에 대해 지수 함수를 적용해서 unnormalized probabilities를 계산하게 된다. 이후 각 값들을 모두 더해주고, 각 클래스에 대한 정규화된 확률값을 계산해주고, 이 확률 값들을 기반으로 true label에 해당되는 클래스에 대한 cross-entropy loss를 계산하게 되는 것. ( -log(P(car)) )
이처럼 softmax classifier는 클래스 점수를 확률로 변환해주고, cross-entropy loss를 사용해서 모델이 실제 레이블을 얼마나 잘 예측하는지를 평가함.
Optimization
Optimization은 loss를 최소화하는 weight를 찾아가는 과정이다.
우선은 numerical gradient란 loss function의 값을 미세하게 변화시켜 그 차이를 계산함으로 gradient를 근사하는 것이다. 하지만 이렇게 계산을 해서 미분을 하면 정확한 값이 아니라 결국 근사치를 얻게 되는 단점이 잇고, 평가를 하기 위해서 시간이 매우매우 오래 걸린다. CNN 같은 경우만 해도 수백만개의 weight를 가지고 있는데 하나하나의 gradient를 계산을 하면 시간이 너무 오래 걸림..
다르게 생각해보면 결국 우리는 weight가 변화할 때 loss가 얼만큼 변화는지를 알고 싶은 것인데, 이 값은 우리가 미분만 알면 쉽게 구할 수가 있다. 이렇게 미분을 통해서 gradient를 구하는 방식을 analytic gradient라고 한다. 이 접근 방법은 빠르 정확하고 실제로 딥러닝 분야에서는 numerical gradient는 사용하지도 않는다.
그래서 간단하게 정리를 해보면, graident 알고리즘을 통해서 기울기를 이용해서 모델의 weight를 조정하는 방법이다. 어떻게 모델의 weight를 조정해야 loss를 가장 효과적으로 감소시킬 수 있는지 알고자 하는 목표이고, 기본적인 단계는 1) 모델의 현재 weight에 대해 loss function의 gradient를 계산해준다. 그러면 gradient는 각 가중치에대해 loss function의 기울기 값이 나오고 이를 바탕으로 loss가 어떻게 변화하는지를 파악한다, 2) 그리고 계산된 gradient의 방향은 loss를 증가시키는 방향이기에, 우리는 반대 방향으로 weight를 이동시킨다. 그래서 식으로 생각해보면 현재 weight에 gradient * learning rate를 곱한 값을 이제 빼주고 이 과정을 반복하면서 weight를 점차적으로 조정해 나간다.
이제 다음은 강의에서 mini batch gradient descent에 대해서 소개를 해줬다. Full batch gradient descent의 한계를 극복하기 위한 방법으로, mini batch gradient descent의 주요 특징에 대해서 확인해보면
- 전체 데이터셋을 작은 batch 단위로 나우어 계산함
- 각 미니 배치에 대해 gradient를 계산하고 파라미터를 업데이트하기 때문에, 학습 과정이 단축됨.
- 또한 메모리도 줄일 수 있음. 전체 데이터를 메모리에 올리는 것이 아니기 때문에
- 또한 미니 배치를 사용하면, 각 업데이트에서 약가느이 노이즈가 추가되어서 모델이 local minima에 빠지는 것을 방지하고 일반화 성능도 높일 수 있음.
그리고 마자막으로 gradient descent 방법으로 momentum, Adagrad, RMSProp, Adam 등이 있다고 소개를 해준다. 처음 딥러닝 공부를 할 때 모르면 그냥 Adam 을 사용하라고 했던말이 기억나는데 이번 포스팅은 momentum, Adam이 무엇인지 간단하게 리뷰를 하고 끝!
Momentum은 이전의 gradient를 어느 정도 기억하면서 현재 gradient에 가중치를 조정하는 방법으로, 파라미터에 일종의 관성을 부여해서 최적점에 좀더 빠르게 도달하고 local minima에 덜 빠지게 도와주는 방법,
Adam (Adaptive Moment Estimation) 이란 모멘텀과 RMSProp의 개념을 결합한 알고리즘으로, 각 가중치에 대해 개별적인 학습률을 적용함. Adam은 그래디언트의 제곱근을 기반으로 한 RMSProp의 학습률 조정 기능과 모멘텀의 이전 그래디언트에 대한 정보를 결합하여 사용함으로 다양한 조건에서 안정적으로 좋은 성능을 낼 수 있는 것으로 널리 인식되고 있음.
오늘의 공부는 여기까지~ 다음 장은 chain rule에 대한 내용~
