
오늘은 training neural network에 대한 부분이다.
앞에 내용 부분은 activation function에 대한 내용을 다루고 있는데 저번 강의에 추가적으로 정리를 한 내용이랑 매우 유사하다.
Activation function
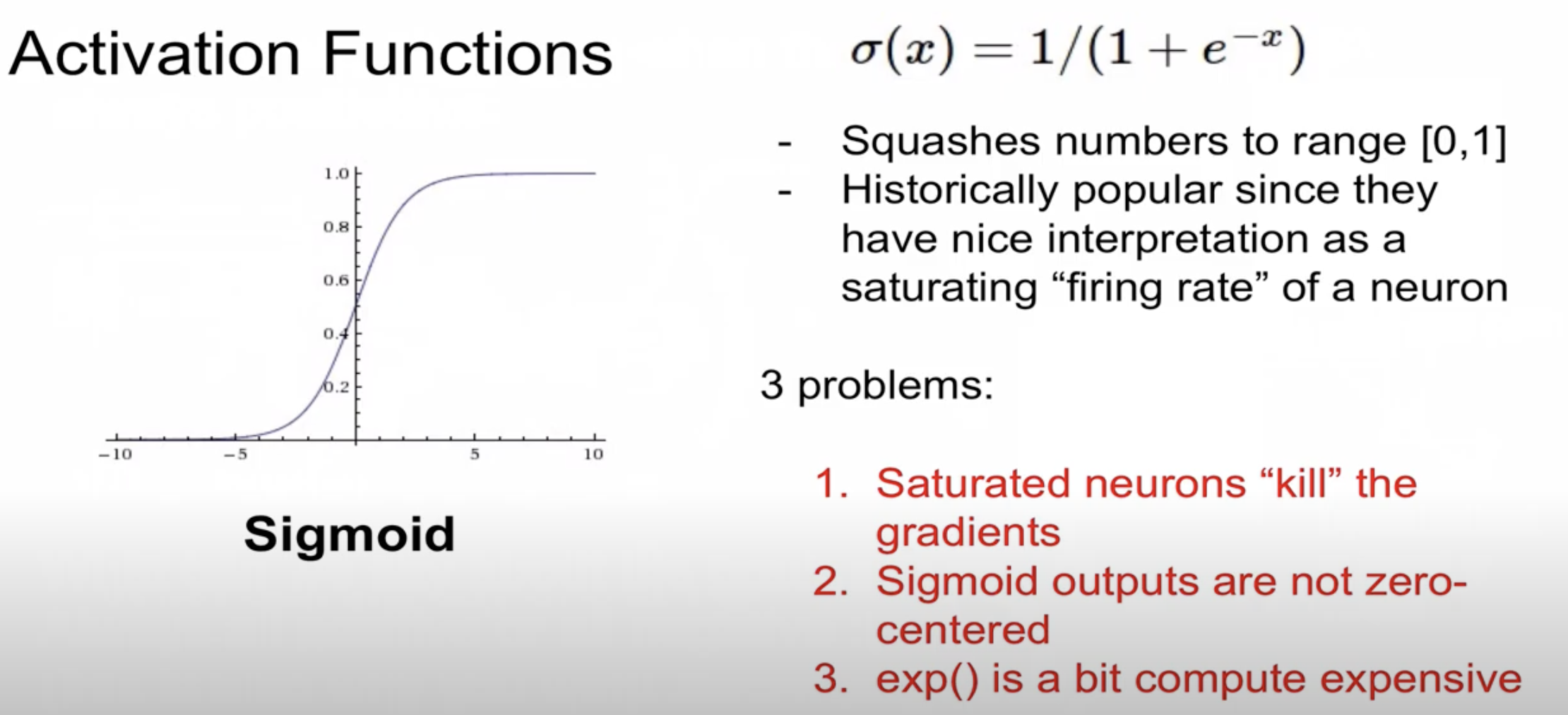
하나 추가로 정리하지 못한 부분은 Sigmoid 함수를 왜 요즘은 잘 사용하지 않는가에 대해서 설명해서 정리를 하고 넘어가고자 함. 우선은 시그모이드는 이제 예전에는 굉장히
요즘 잘 사용하지 않는 이유로:
(1) Saturated neurons "kill" the gradients: 이제 포화된 뉴런들이 gradient를 죽게 만든다고 표현을 했는데, 저번 강의에 대한 정리를 하면서 gradient vanishing 문제를 일으키는 것에 대한 내용이다. 시그모이드 함수의 경우는 0~1 사이의 값을 출력을 하는 것이기 때문에 만약 함수의 입력값이 매우 높거나 낮아지게 되면, 함수의 기울기가 거의 0에 가까워지기 때문에, 역전파 과정에서 가중치가 제대로 업데이트 되지 않는 현상이 발생하게 된다. 이런 과정이 gradient vanishing problem.
(2) Sigmoid outputs are not zero-centered: 시그모이드 함수의 출력값은 항상 양수인데, 이는 옵티마이저가 가중치를 업데이트할 때 일정한 방향성을 가지고 움직이게 되므로 비효율적으로 학습이 가능해짐. 이제 모든 출력들이 양수이면 가중치 업데이트가 한방향으로만 치우쳐지게되니깐 가중치 조정이 비효율적이게 되는 것이다.
(3) exp() is a bit compute expensive: 그리고 시그모이드 함수에는 지수함수를 포함하고 있는데, 이 지수함수가 컴퓨터한테는 상대적으로 비용이 많이 들어가는 연산이라고 함. 그래서 계산적인 비효율성이 발생 가능하기 때문에 비효율적이라고 소개하고 있음.
Data preprocess
이제 다음은 데이터 전처리에 대한 부분. 여기서 보다가 "zero-centered data"라고 하는 처음보는 용어가 있어서 정리를 하고 넘어간다.
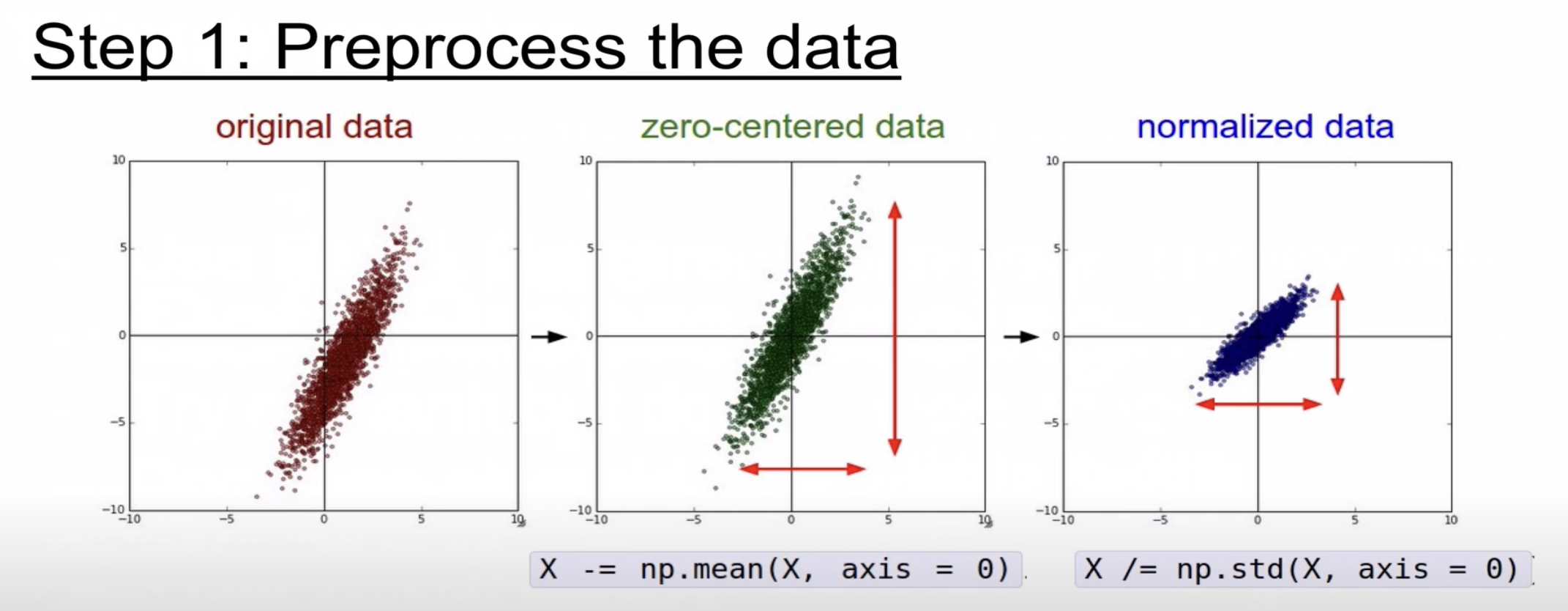
Zero-centered data는 강의에서 소개하기를 데이터의 중심을 0으로 맞추는 전처리 방법으로, 각 데이터 포인트에서 전체 데이터의 평균을 빼주는 것이라고 한다. 이렇게 하면 데이터의 중심이 원점(0,0)으로 이동하게 되는데, 이렇게 되면 데이터가 평균값을 중심으로 대칭이 되도록 만들어주고, 이로 인해 여러 최적화 알고리즘들이 더 잘 작동할 수 있도록 도와주는 효과가 있다고 한다.
그래서 처음 들었을 때는 어떤 픽셀 값들에 대해서 정규분포 형태로 만들어주는 것인가 싶었다. 근데 zero centering은 단순히 데이터의 평균을 0으로 만들어주는 개념이다. 이미지 데이터를 처리하는데 사용된다고 한다. 이를 적용하면 이점으로
- 가중치 초기화와 함께 학습 속도를 향상 할 수 있고, 또한 최적화 알고리즘들이 더 효율적으로 작동할 수 있도록 해서, 결과적으로 더 빠른 수렴을 가능하게 해준다고 한다.
- 또한 각 레이어의 입력 분포를 안정화해주는 효과가 있어서, 가중치를 업데이트 시 그레디언트의 흐름이 일정하게 유지되도록 도와준다고 함.
- 마지막으로 결국 입력 데이터가 중심을 기준으로 대칭적이면, 신경망의 가중치가 더 대칭적으로 학습될 가능성이 높아지기 때문에, 특히 깊은 네트워크에서 학습을 좀더 안정화시키는데 도움이 된다고 함.
Weight Initialization
학습에 매우 중요한 부분!
가중치 초기화는 신경망의 각 레이어에 대한 가중치가 처음에 설정되는 방식을 말하는 것으로 학습을 시간하기 전에 각 레이어의 가중치에 설정되는 초기 값이다. 이 초기값들로 학습의 출발점을 결정하게 되는 것이다. 생각을 해보면 모든 가중치가 같은 값으로 초기화된다고 하면, 모든 뉴런들이 동일한 출력값들을 생성해서 학습을 하면서 다른 특성들을 학습하지 못할 것이고, 또한 이 가중치 값이 너무 크거나 작으면 이것 또한 gradient vanishing 문제를 일으킨다.
Pytorch 자체에서는 nn.Module 에서 기본적인 초기화를 수행하는 것이 내포되어 있지만, 좀더 효과적으로 학습하기 위해서는 모델에 적합한 초기화 방법을 직접 설정해주는 것도 좋은 방법이다.
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.layer1 = nn.Linear(5, 3)
self.activation = nn.ReLU()
init.xavier_uniform_(self.layer1.weight)
init.zeros_(self.layer1.bias)Batch normalization
이후 batch normalization이 vanishing gradient가 일어나지 않도록 하기 위한 방법 소개 부분이다. 근데 vanishing gradient를 방지하기 위해서 relu 또는 weight initialization 을 잘 선택하는 방법들로 해결을 해옴. 근데 batch norm은 이런 간접적인 방법이 아니라 학습하는 과정 자체를 전반적으로 안정화를 하겠다는 방법이고, 이는 학습 속도를 가속화하고 안정적이게 학습을 시키겠다는 근본적인 방안을 제시한 방법임. 학습을 하면서 불안정화가 이루어지는 이유는 내부에서 코베리언스 시프트가 ? 이러나게 되고, 각 레이어들을 거치면서 입력값들의 분포가 달라지는 현상이 발생해서 이런 불안정화가 일이나는 것인데, 그래서 각 계층 각 레이어를 거칠 때마다 이것들을 normalization을 하자는 것이고 이것이 기본적인 batch norm의 핵심 아이디이다. 각 레이어에서 normalization을 해주더라도 여전히 미분 가능한 함수이고, 그렇기 때문에 forward, backward pass하는데 아무런 문제가 없다.
과정을 보면 이것은 normalization이 한번에 전부다 적용하는 것이 아닌, mini batch를 뽑아서 이 배치에 대해서 평균과 분산을 계산을 해주고 그것을 정규화 해주는 것이다. 일반적으로 layer와 activation function 그 사이에 위치를 하게 된다.

두 단계로 나누어서 보면. 첫번째 단계에서 normalize를 하고 그 두 번재 단계에서는 정규화된 것을 다시 한번 조정해주는 것. normalize된것에 대해서 scaling을 해주고 shift해주는 것. 그래서 이 값들은 학습을 통해서 결정이 되는 것.
그래서 결과적으로 네트워크상에서 gradient flow를 개선해주고 learning rate가 다소 큰 값을가져고 허용해줘서 좀더 빠르게 학습을 해주고, 가장 핵심은 초기화에 너무 의존하지 않도록 만들어준다는 장점을 가진다. 그리고 그 자체가 regulaization을 해주는 효과를 얻게 되는 것이다. 그래서 모 다른 regulaization 기법인 dropout같은 방법을 사용할 경우에는 batch normalization 기법을 잘 사용하지 않는 그런 경향이 있다고 함.
한가지 주의해야될 부분은 training, test 할때 batch norm은 다르게 동작을 한다고 함. min값과 variance 값을 구할 때 training 단계에서는 batch를 기준으로 구하게 되는 것이고, test를 한경우는 batch에 대해서 구하는 것이 아니라 전체에 대해서 구하는 것이다.
이제 뒤에 부분은 전반적인 learning process + hyperparameter optimization에 대한 소개이다. 이 부분들은 실제로 해보면서 많은 시행착오를 겪는 과정 .. 이 부분은 너무 잘아는 과정이기 때문에 정리는 패스.
