Clustering(군집화)
- 비지도 학습 상황에서, 데이터 샘플들을 별개의 군집(cluster)으로 그룹화 하는 것
- 비지도 학습에서의 분류 알고리즘
- 데이터 특징에 따라 세분화 하는데 사용
- 이상 검출 (anomaly detection)에 사용 --> 전처리 과정에도 사용 가능
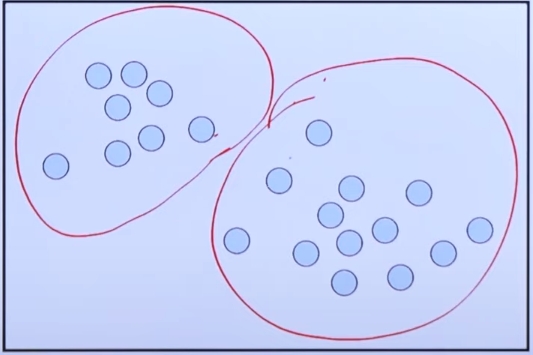
- 유사성이 높은 데이터를 동일한 그룹으로 분류
- 서로 다른 군집은 특성이 상이하도록 군집화함
- 클러스터 내부의 분산(within 분산) 최소화, 클러스터 간의 분산(between 분산) 최대화
Parametric vs Non-Parametric
모수적 추정 vs 비모수적 추정
모수적(parametric) 추정:
- 주어진 데이터가 특정 데이터 분포를 따른다고 가정 --> 수식으로 표현 가능 --> 분포 function
- Gaussian Mixture Model(GMM)이 대표적
비모수적(non-parametric) 추정:
- 데이터가 특정 분포를 따르지 않는다는 가정 하에 확률 밀도를 추정 --> 수식으로 표현 X
- K-means, Mean Shift, DBSCAN 등의 알고리즘이 있음
Non-parametric 추정
K-means
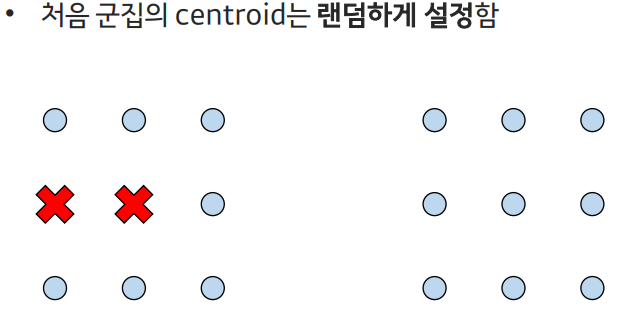
- 군집의 중심점(centroid)기반 클러스터링
- 샘플은 가장 가까운 중심점을 가진 군집으로 할당됨
- K-means 알고리즘은 사전에 군집의 수에 대한 하이퍼파라미터 k를 정해야 사용 가능
- , --> 군집의 수 : k, 샘플은 무조건 하나의 군집에 포함됨
- --> 군집의 centroid와의 유클리디안 거리 차이가 최소가 되도록
- EM 알고리즘을 통해 최적의 군집에 수렴할 때까지 학습함
기댓값 최대화 알고리즘 (EM algorithm)
- 최대가능도(maximum likelihood)나 최대사후확률(maximum a posteriori)을 갖는 모수의 추정값을 찾는 반복적인 알고리즘
- EM 알고리즘은 Expectation 단계와 Maximization 단계로 나뉨
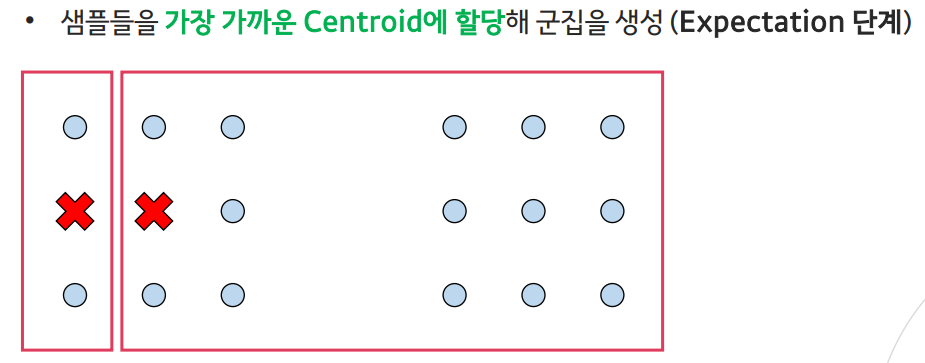
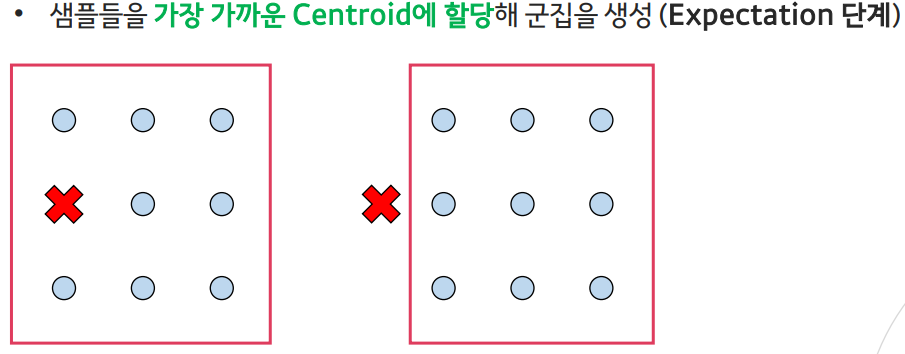
- Expectation(기댓값) 단계:
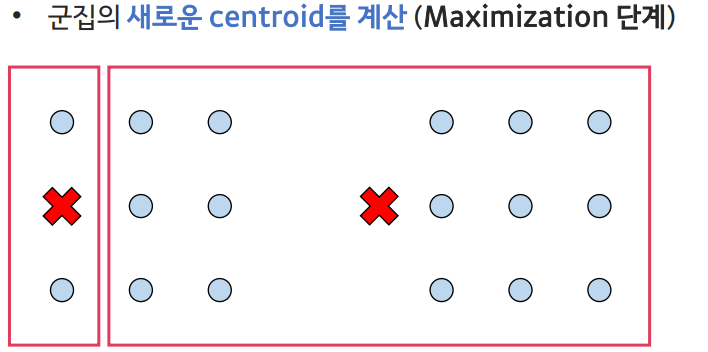
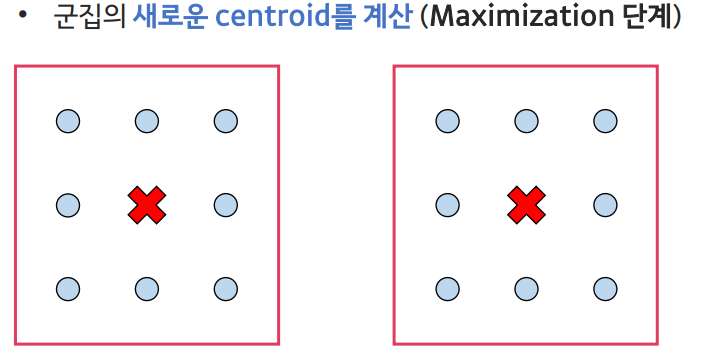
현재의 추정된 모수를 통해 샘플을 군집에 할당하는 단계 - Maximization(최대화) 단계:
로그 가능도(likelihood)의 기댓값을 최대화하는 모수를 추정하는 단계
- 특정 분포에 대한 가정이 없는 Non-parametric 추정에서는 가능도의 개념이 없음
- Mean Shift나 DBSCAN은 밀도 추정의 방법으로 학습
- K-means 군집화에서의 EM 알고리즘은
- Expectation 단계: 추정하고자 하는 모수는 중심점(centroid)이므로, 샘플을 군집으로 할당하는 단계
- Maximization단계: likelihood를 샘플이 군집에 속할 확률로 해석하여, 군집에 할당된 샘플을 바탕으로 새로운 중심점을 계산

Evaluation Metrics of Clustering
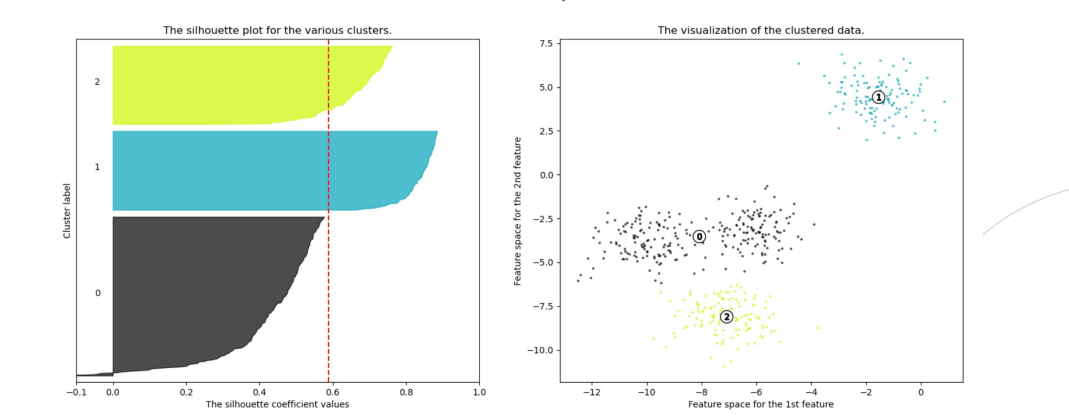
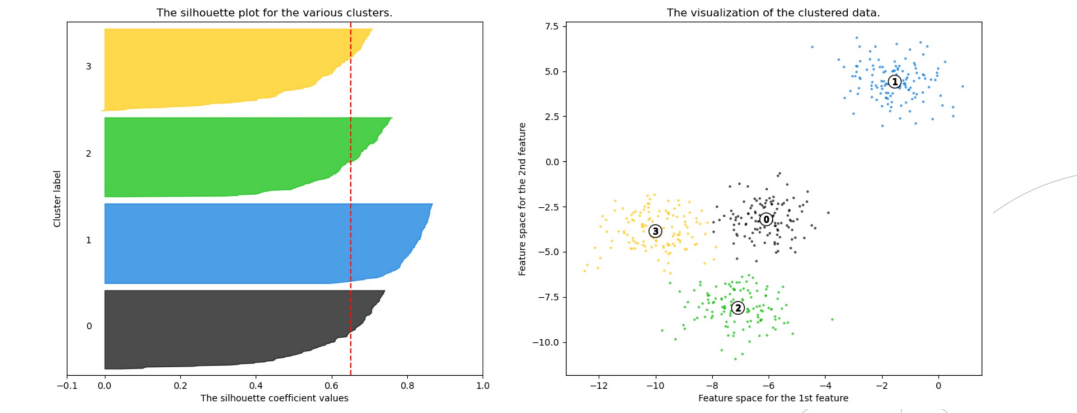
- 실루엣 분석(silhouette analysis)
- 군집들이 얼마나 효율적으로 분리되어 있는지를 보여줌
- 각 샘플들이 가지고 있는 실루엣 계수(silhouette coefficient)를 기반으로 함
- 전체 실루엣 계수의 평균값이 클수록, 개별 군집의 평균값의 편차가 작을수록 좋음
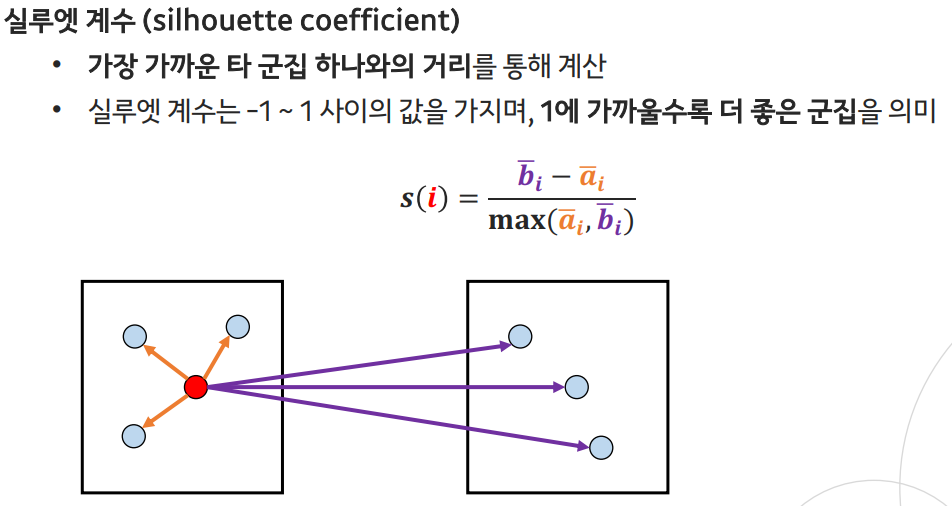
: 같은 군집에서의 샘플 거리 평균
: 다른 군집에서의 샘플 거리 평균
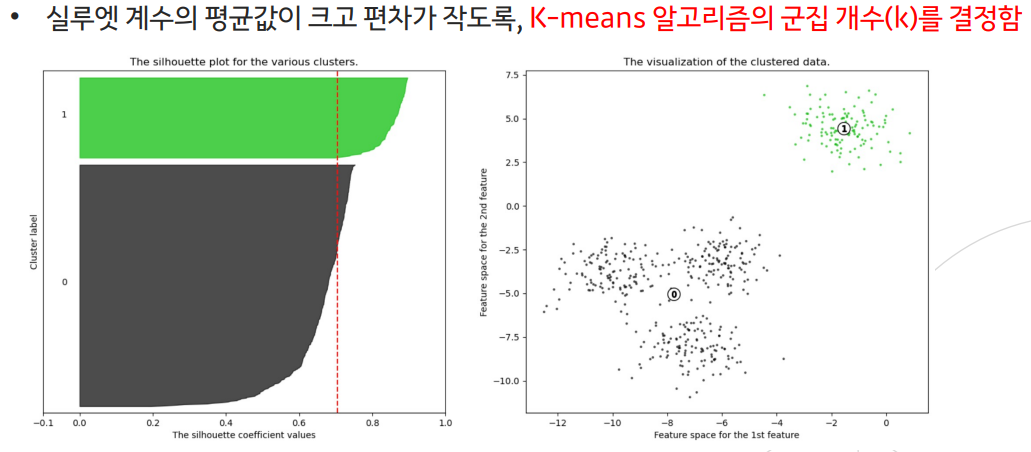
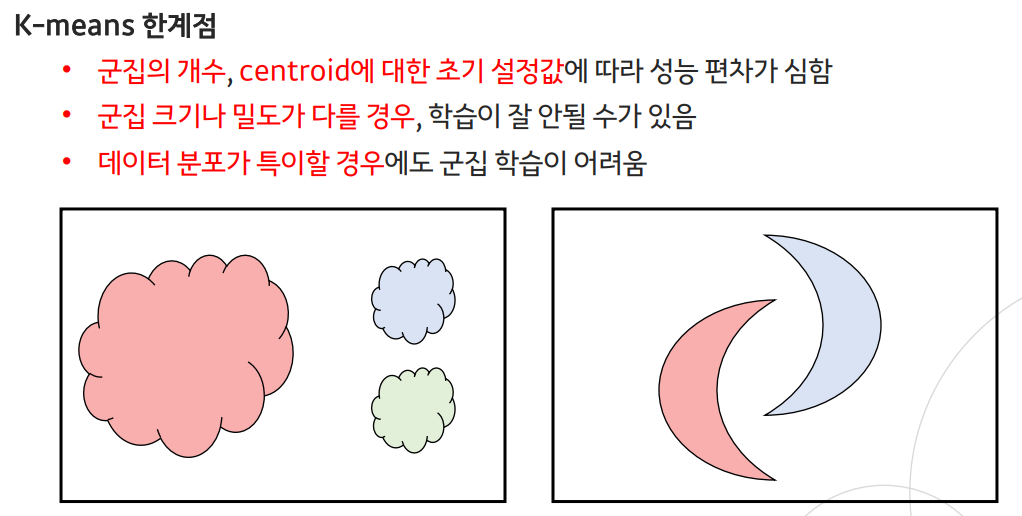
--> 이러한 단점을 보완시킨 알고리즘 : mean shift 알고리즘
Mean Shift(평균 이동)
- 각 샘플을 기점으로 주변에 데이터가 가장 밀집된 곳으로 이동하는 것을 수렴할 때까지 반복
- 모든 데이터에 대해 수렴 지점을 계산하여, 군집의 개수를 "자동으로" 결정
- 각 샘플들을 가장 가까운 중심점을 가진 군집으로 할당
- K-means 알고리즘과 다르게 군집 개수에 대한 하이퍼파라미터가 불필요
- Sliding window의 크기를 조절해 주변 어느 정도까지 볼 지 결정해야 함 --> 하이퍼 파라미터로 주변 반경 크기
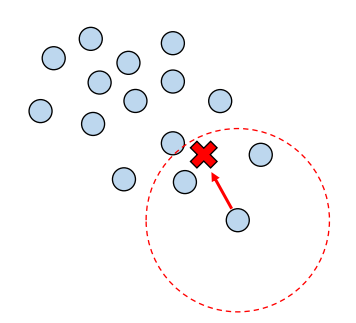
- 비모수(non-parametric) 방법의 모델
- KDE(kernel density estimation)를 통해 밀도가 가장 높은 곳을 찾아냄
히스토그램 (histogram)
- 비모수적 밀도 추정을 위해 간단하게 히스토그램을 사용할 수 있음
- 하지만, Bin의 경계때문에 불연속적인 특징이 있음
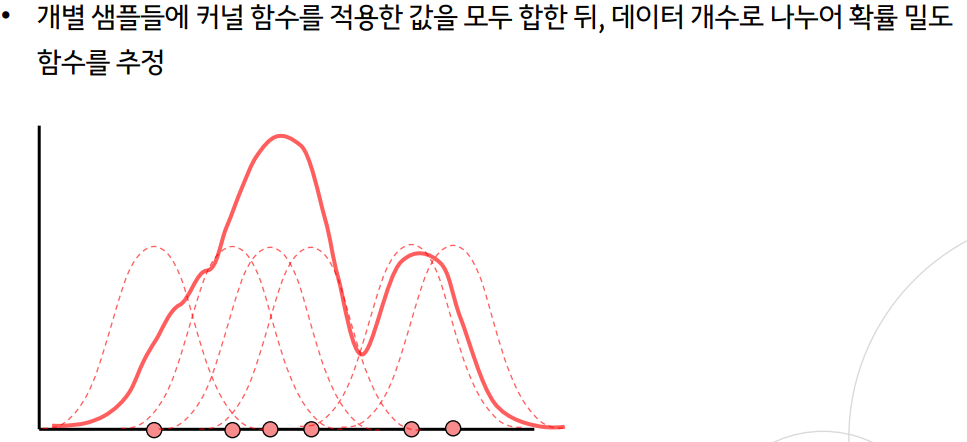
KDE(kernel density estimation)
- 커널 함수를 통해 어떤 변수의 확률 밀도 함수를 추정하는 방법
- 개별 샘플들에 커널 함수를 적용한 값을 모두 합한 뒤, 데이터 개수로 나누어 확률 밀도 함수를 추정 --> 각각에 모두 적용
- 는 커널 함수의 bandwidth 파라미터로, 뾰족한 형태 혹은 완만한 형태일지 결정
- 대표적인 커널 함수로 Gaussian 분포 함수가 사용됨 --> : 데이터값 자체를 평균으로, : 값으로 대체


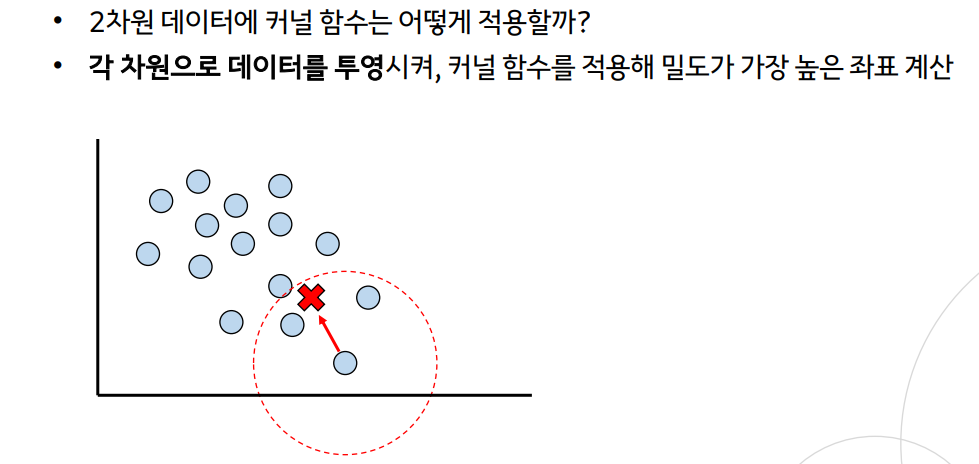
--> x축, y축에 투영시켜서 계산
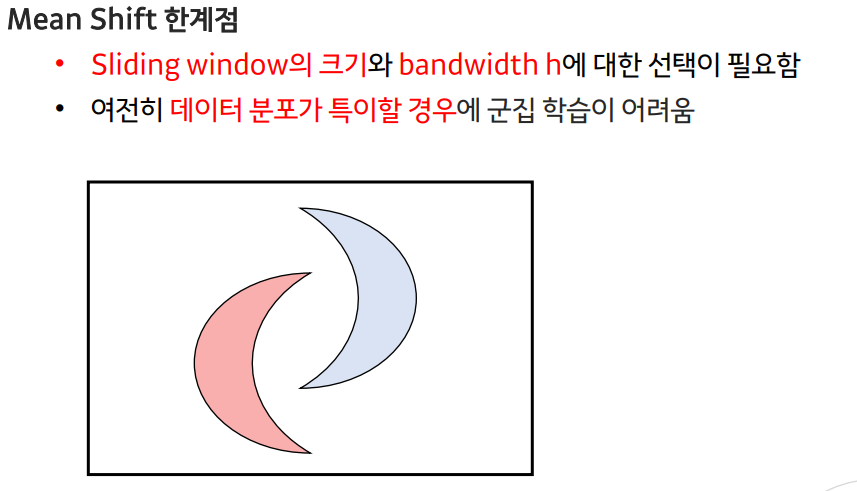
--> 결국 거리의 차이에 따라서 평가를 하므로 특이한 데이터 분포의 경우 학습 어려움 여전
--> 이를 해결한 알고리즘이 DBSCAN 알고리즘
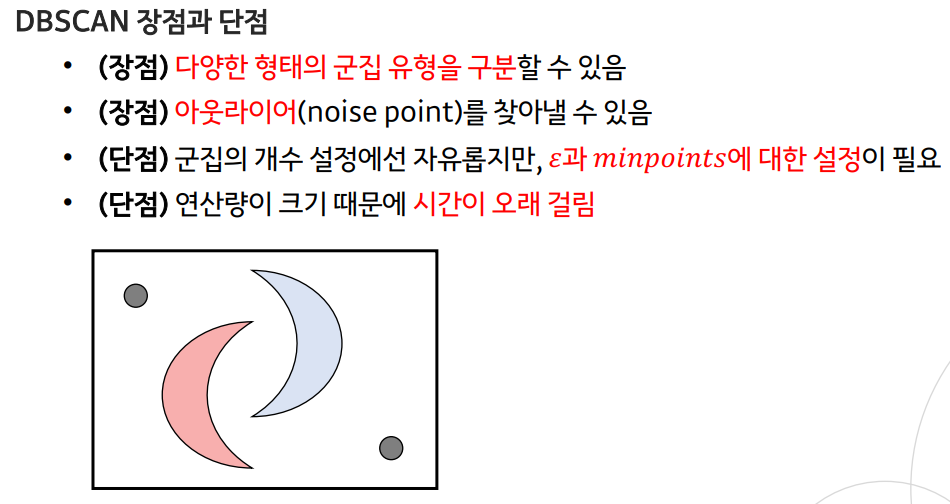
DBSCAN (density-based spatial clustering of applications with noise)
- DBSCAN 또한 밀도가 높은 부분을 중심으로 군집화를 하는 방법론
- 어떤 점을 기준으로 반경 내에 샘플이 minpoints 보다 많으면 같은 군집으로 할당
- 군집으로 할당된 샘플들을 해당 군집의 core point로 설정해 계속 반복
- minpoints 개수를 만족 못하는 borderpoint 샘플(군집으로 할당은 됐지만, corepoint가 될 수 없는 샘플)이 나올 경우 멈춤
- 이를 모든 데이터 샘플에 대해 진행하여 cluster point와 noise point를 구분
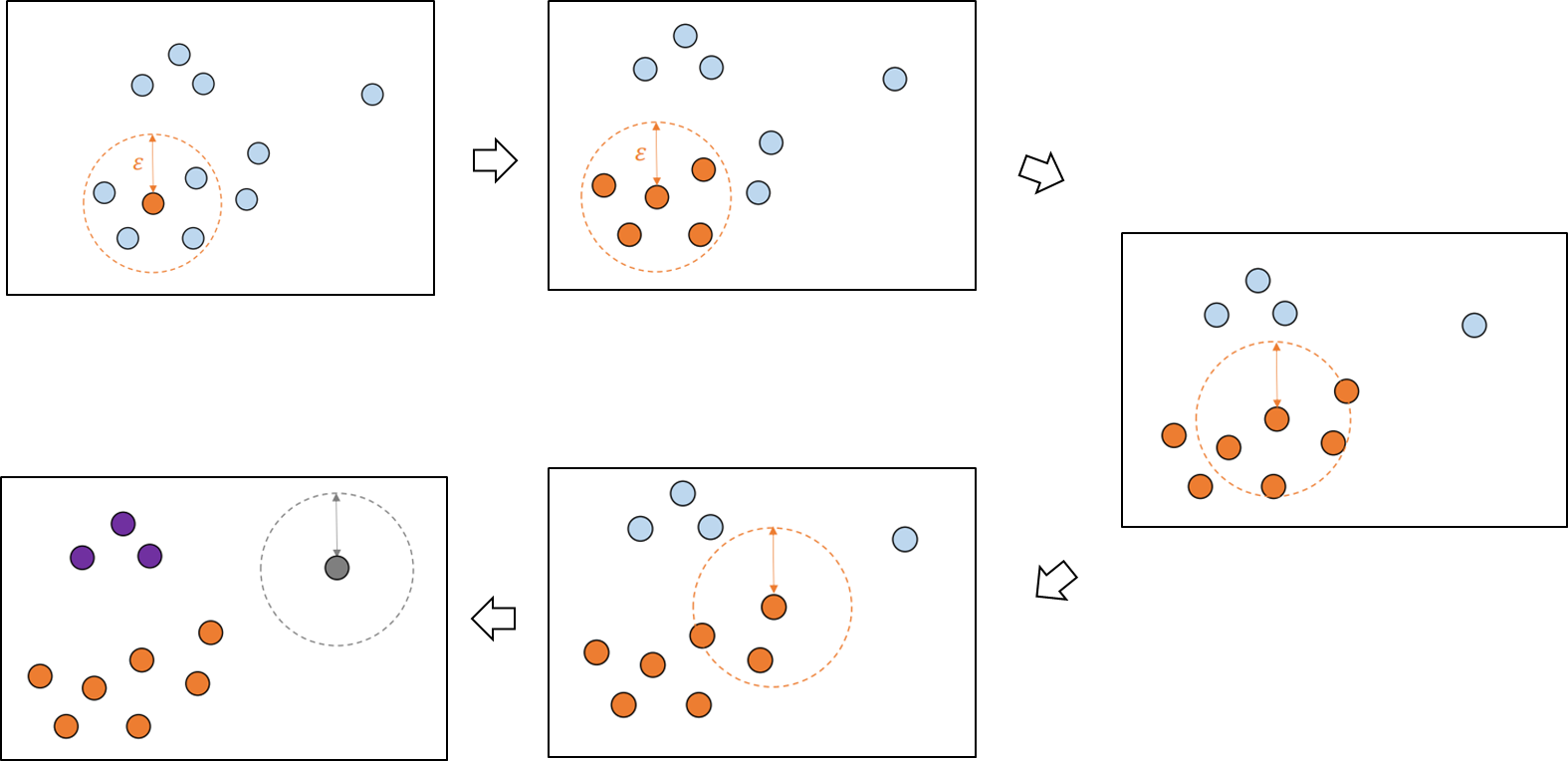
parametric 추정
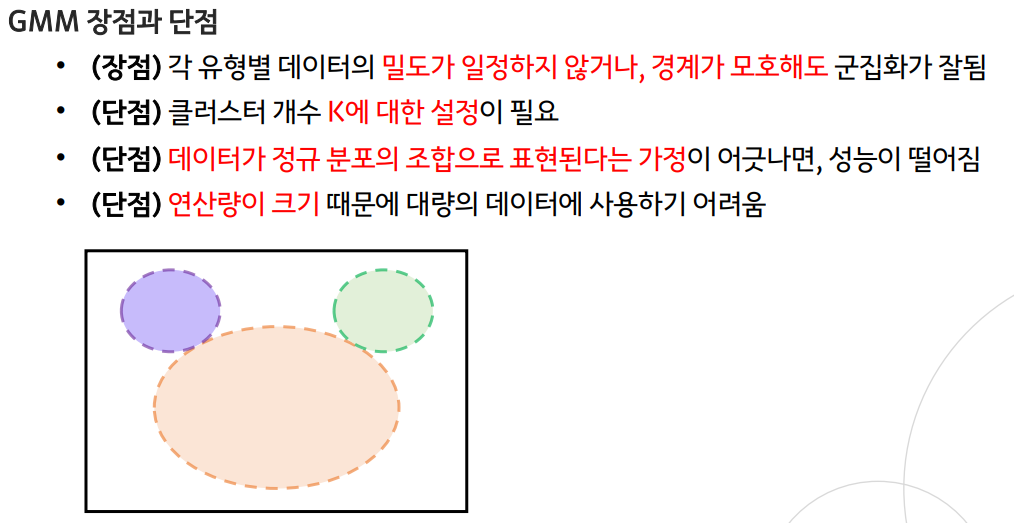
GMM (Gaussian Mixture Model)
- 모수적 추정의 방법론으로, 주어진 데이터를 K개의 Gausian 분포의 혼합으로 가정
- EM 알고리즘을 통해 모델을 학습함
- LDA에서의 베이즈 분류기와 매우 비슷
- 비지도 학습이기 때문에 Y 라벨을 Z 클러스터 군집으로 대체하여 표현
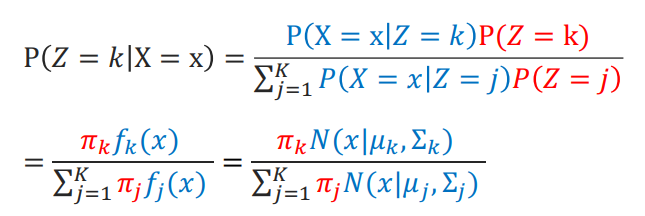
- 비지도 학습이기 때문에 LDA와 다르게 뿐만 아니라 에 대한 모수 추정 필요
- EM 알고리즘은 Expectation 단계와 Maximization 단계로 나뉨
- Expectation(기댓값) 단계:
- 현재 추정된 모수를 통해 샘플을 군집에 할당하는 단계
- Responsibility(책임값)를 계산하여, 샘플마다 가장 큰 값을 도출하는 군집으로 할당
-
2. Maximization(최대화) 단계:
- 로그 가능도(likelihood)의 기댓값을 최대화하는 모수를 추정하는 단계
- 먼저 GMM의 우도 확률(likelihood)을 로 정의
- 단조 증가 함수의 로그 함수를 사용해 로그 가능도 함수를 정의
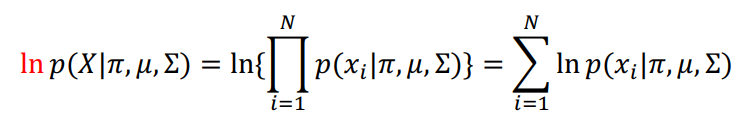







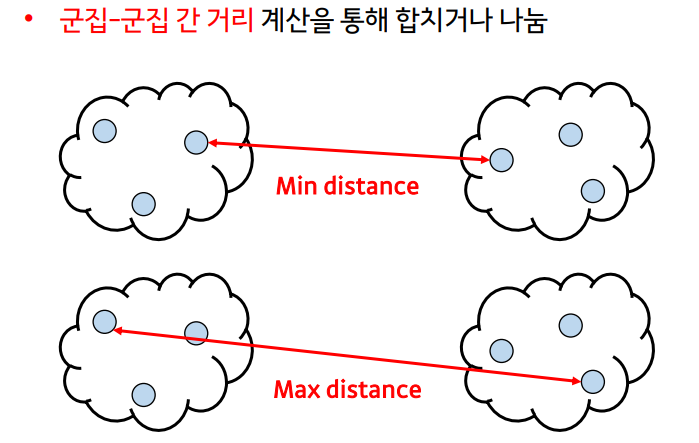
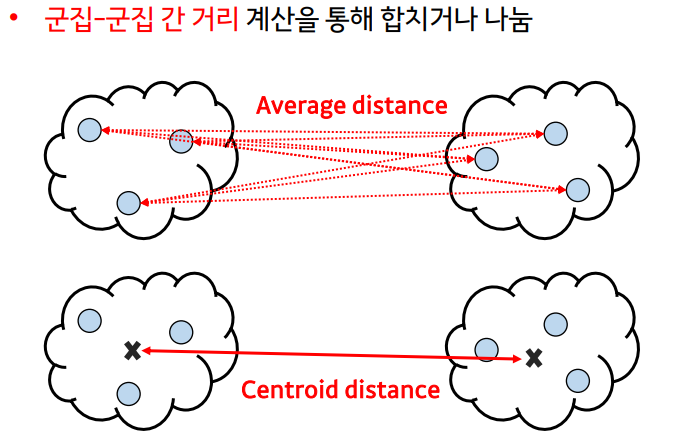
Hierarchical Clustering(계층적 군집화)
- 하나의 클러스터ㅓ로부터 시작해서 모든 클러스터가 하나의 원소를 가질 때까지 쪼개는 Divisive(top-down approach) 방법
- 각각의 샘플을 원소로 가지는 클러스터들로부터 전체를 포함하는 하나의 클러스터가 될 때까지 합쳐가는 Agglomerative(bottom-up approach) 방법


Sometimes You gotta run before you can walk.