MetaCode - Machine Learning
1.MetaCode(Machine Learning) 1-1 머신러닝 소개

인공지능(AI) > 머신러닝(ML) > 딥러닝(DL)인공지능 : 사람을 흉내내는 모든것 ( 기술, 알고리즘)머신러닝 : 전문가가 준 데이터를 기계가 학습하는 것딥러닝 : 머신러닝의 기계 구조가 신경망(Neural Networks)으로 이루어진 것인간이 제공한 데이터에
2.MetaCode(Machine Learning) 1-2 기초수학(이론)
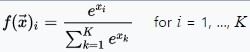
입력값 : 연속값(실수형), 이산값(범주형) 등 모두 가능출력값 : 연속값(실수형)모델 형태: 일반적인 함수 형태 (ex. y = wx+b)입력값 : 연속값(실수형), 이산값(범주형) 등 모두 가능출력값 : 이산값(범주형)모델 형태 :이진 분류라면 sigmoid 함수다
3.MetaCode(Machine Learning) 1-4 편향과 분산
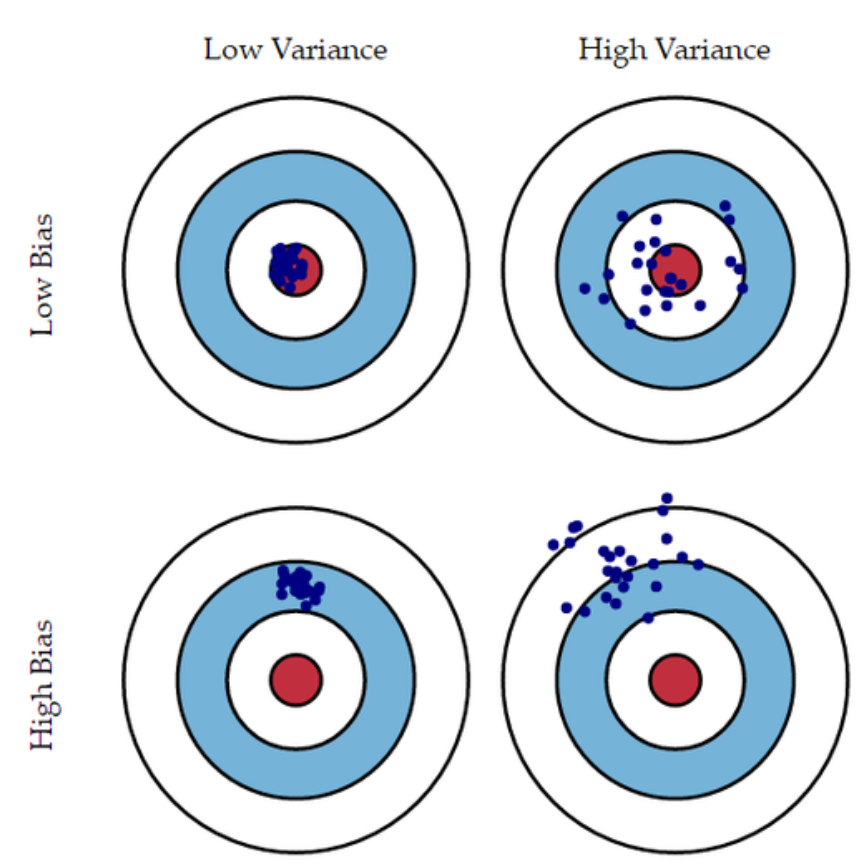
입력된 데이터는 학습 데이터와 평가 데이터로 나눌 수 있음학습 데이터는 모델 학습에 사용되는 모든 데이터셋평가 데이터는 오직 모델의 평가만을 위해 사용되는 데이터셋평가 데이터는 절대로 모델 학습에 사용 X학습 데이터와 평가데이터는 같은 분포를 가지는가? 랜덤함수를 통해
4.MetaCode(Machine Learning) 2-1 Logistic Regression
2-1 Logistic Regression 회귀 (Regression) Input : 연속값(실수), 이산값(범주형) 등 모두 가능 output : 연속값(실수형) 모델 형태 : 일반적인 함수 형태( ex. $y = w1x+w0)$ 분류 (Classificat
5.MetaCode(Machine Learning) 2-3 Support Vector Machine
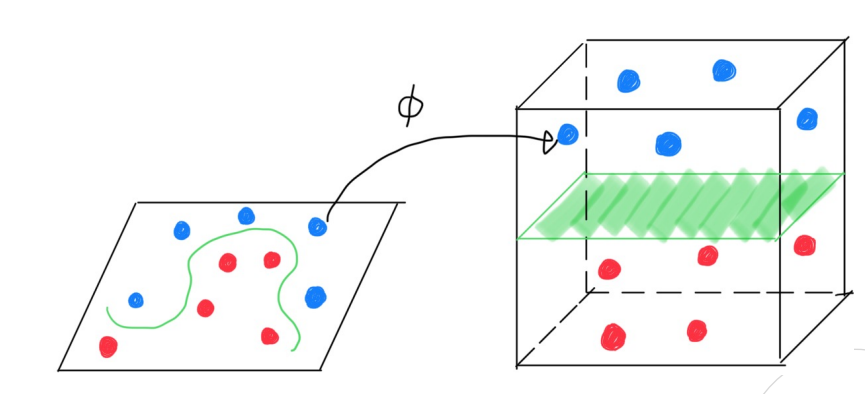
SVM (Support Vector Machine) Hyperplane p차원에서 hyperplane은 p-1차원에서의 평평한 어핀 공간(2차원-> 직선, 3차원 -> 면) $b+ w1X1 + w2X2 + ... + wpXp = b + = 0$ $w = (w1, w
6.MetaCode(Machine Learning) 2-4 Decision Tree
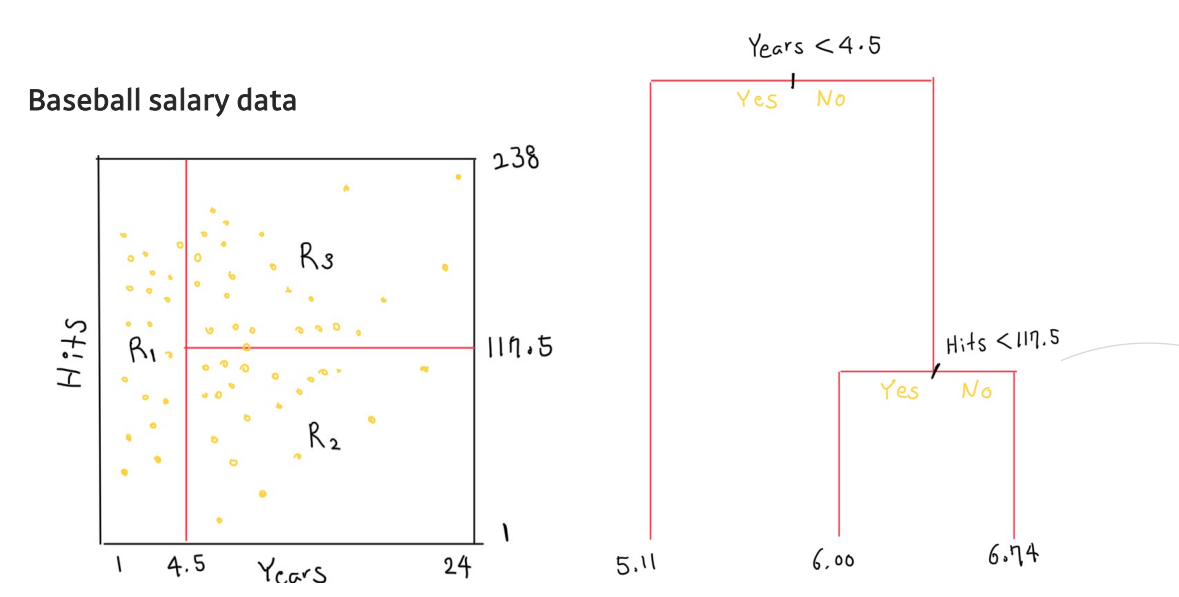
Tree-based Methods 예측을 위해 여러 region으로 stratifying or sementing 하는 방법론 회귀와 분류 모두에서 사용 가능
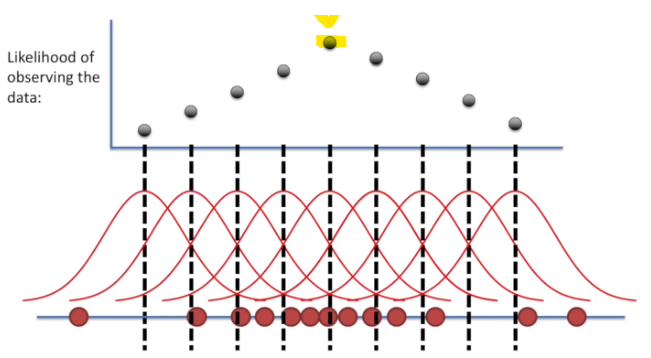
7.MetaCode(Machine Learning) 2-5 Linear Discriminant Analysis
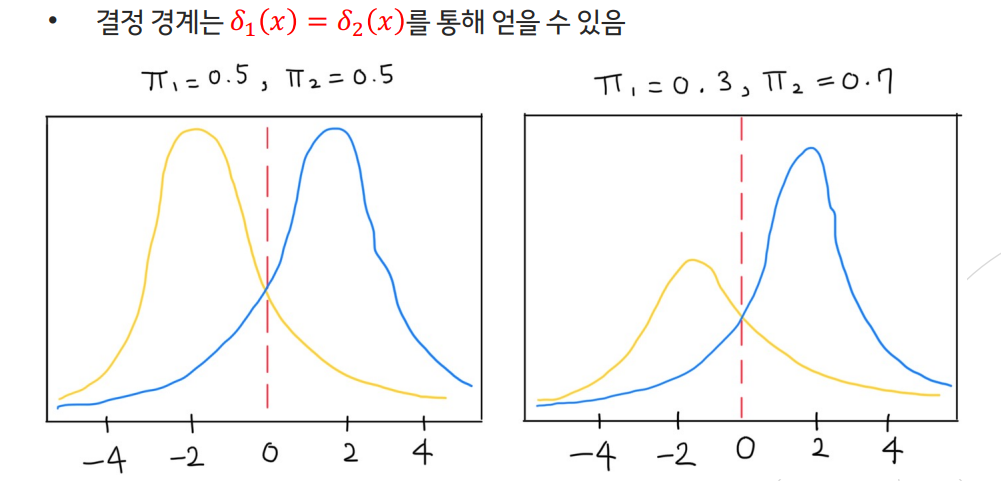
데이터 분포를 학습해 결정경계(Decision boundary)를 만들어 데이터를 분류(classification)하는 모델사후확률 $P(W|X) = \\frac{P(X|W)P(W)}{P(X)}\\propto P(X|W)P(W)$ 우도확률 \* 사전확률$P(Y=k|X=
8.MetaCode(Machine Learning) 3. Ensemble Learning
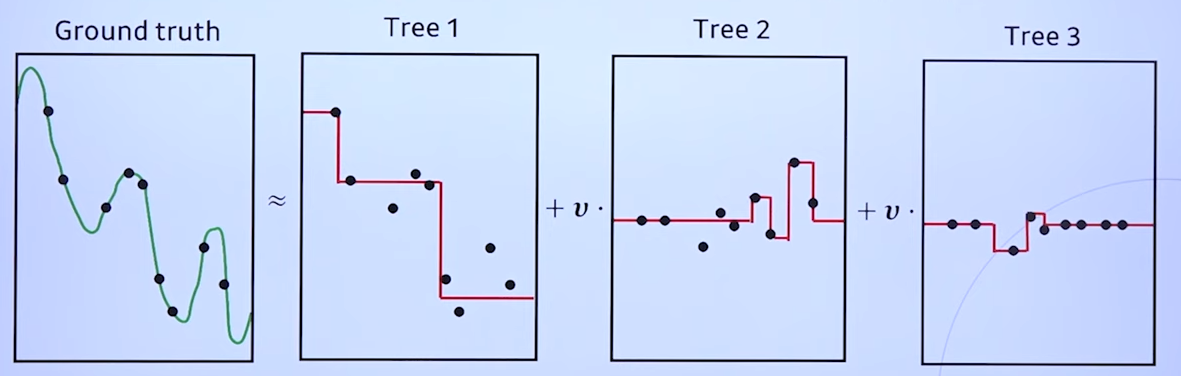
Ensemble Learning(앙상블 학습) 앙상블 학습은 여러 개의 모델을 학습시켜, 다양한 예측 결과들(평균, majority vote)를 이용하는 방법론 모든 머신 러닝 모델과 회귀, 분류 문제 모두에 적용 가능함 보통 결정 트리에서 자주 사용됨 크게 Baggi
9.MetaCode(Machine Learning) 4. Dimension Reduction - PCA

Dimension Reduction 데이터에 대한 차원 축소는 속도뿐만 아니라 성능 면에서 필요 모델 학습에 불필요한 피처(속도 향상)나 방해되는 피처(성능 향상)를 제거해야함 방해되는 피처란, over-fitting 문제를 발생시키는 피처로 이해 가능 이는 차원의 저
10.MetaCode(Machine Learning) 5. Clustering
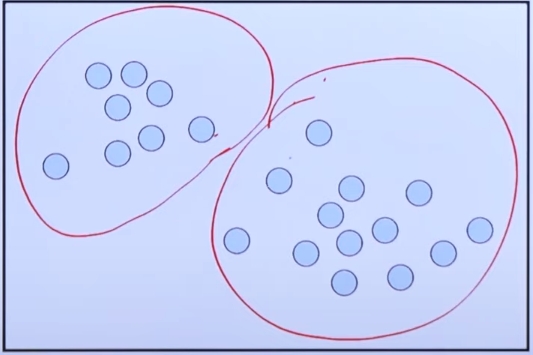
비지도 학습 상황에서, 데이터 샘플들을 별개의 군집(cluster)으로 그룹화 하는 것비지도 학습에서의 분류 알고리즘데이터 특징에 따라 세분화 하는데 사용이상 검출 (anomaly detection)에 사용 --> 전처리 과정에도 사용 가능유사성이 높은 데이터를 동일한