Image Captioning
- Encoder를 Image-Captioning을 위해 Pre-trained된 ResNet101을 사용
- Pooling과 linear를 제거하여 사용한다.
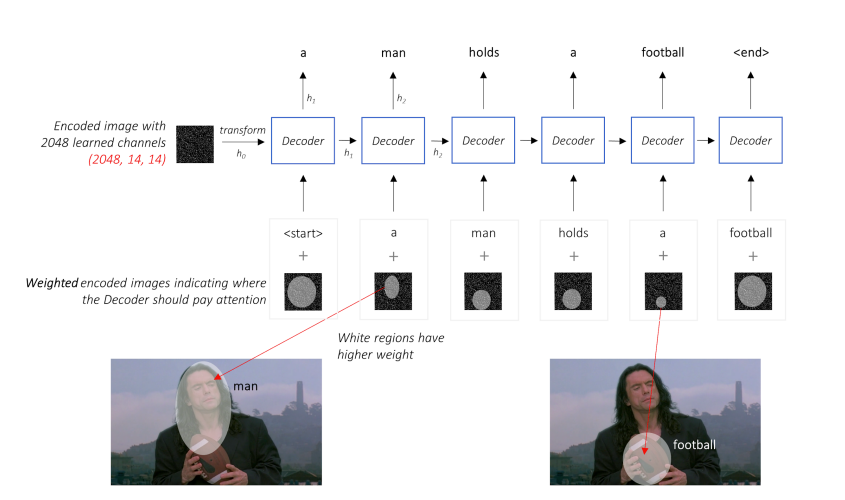
- start token이 decoder로 들어가고 이전에 출력된 정보와 attention 정보를 input을 넣는다.
- RNN은 많은 word class를 가진 classification이다. 만약 어떤 값보다 더 나은 값이 나와도 앞단계에서 버리기 때문에 아쉬운 상황이 발생하는데 이 때 Beam search를 사용한다.
- Beam Search는 Top 1 대신 Top k개를 고른다. -> 즉 k개까지는 여지를 주면서 다음 값을 계속 추측하게 된다.
3D understanding
우리가 3D 세상에 살고 있기 때문에 3D 기술은 중요하다.
다음은 어떻게 3D 데이터가 저장되는지 그 방법들을 나태낸 그림이다.

3D datasets
-
Shape NET: Large scale synthetic objects (51300개)
-
Part NET: Fine grained dataset, useful for segmentation (573,585 part instances in 26,671 3D models)
-
Scene NET: 5million RGB-depth synthetic indoor images
-
SCAN NET: 2.5million RGB depth view real data
-
outdoor 3D scene dataset
1) KITTI: LiDAR data labeld by 3D b.boxes
2) semantic KITTI: LiDAR data, labeled per point
3) Waymo open dataset: LiDar dataset labeld by 3D b.boxes
3D tasks
3D recognition
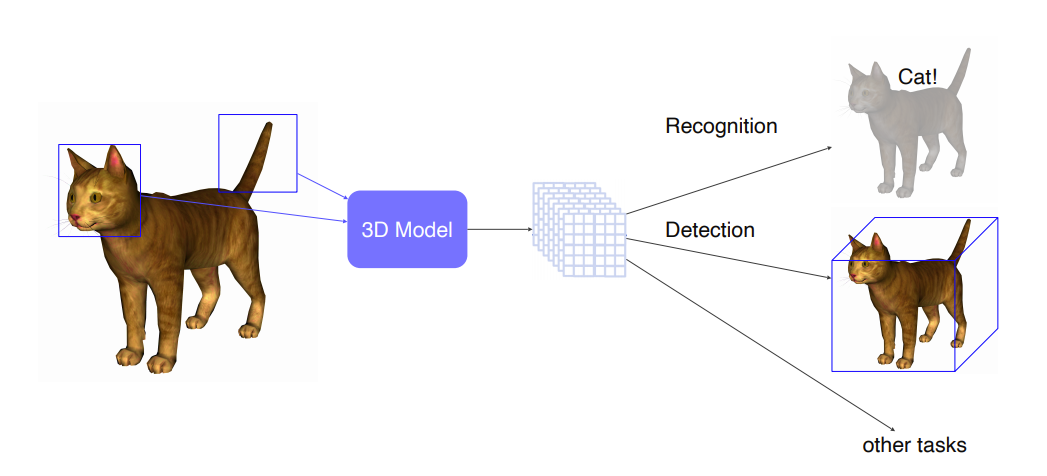
2D 와 마찬가지로 3D역시 3D Model을 거쳐 고양이라고 예측을 하게 된다.
3D object detection

3D semantic segmentation
Conditional 3D generation
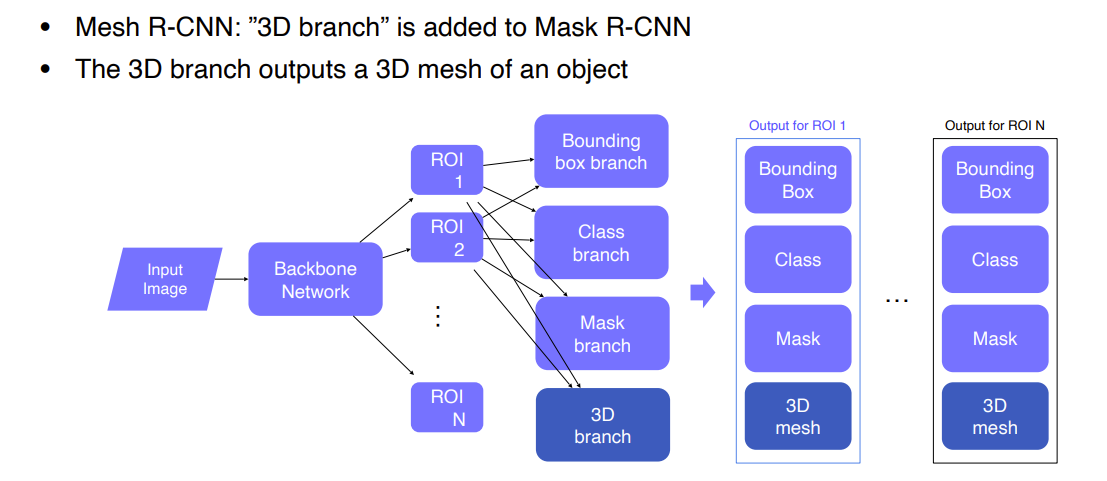
Mesh R-CNN
- Mask R-CNN과 비슷하다. input은 2D, output은 3D
- Mask R-CNN의 head를 mesh형태로 modification함으로써 구현할 수 있다.
- input 이미지가 들어오면 detection하고 그 후에 3D Voxels나 Meshes로 바꾼다.

Mask R-CNN vs Mesh R-CNN
Mask R-CNN의 branch는 BBox와 classes, mask를 예측하는것으로 구성되어있다. output을 낼 때마다 하나의 ROI를 공유하여 각각의 feature로부터 출력을 prediction한다.
Mesh R-CNN은 이 구조에 3D branch를 추가하여 3D mesh를 생성하는 구조이다.
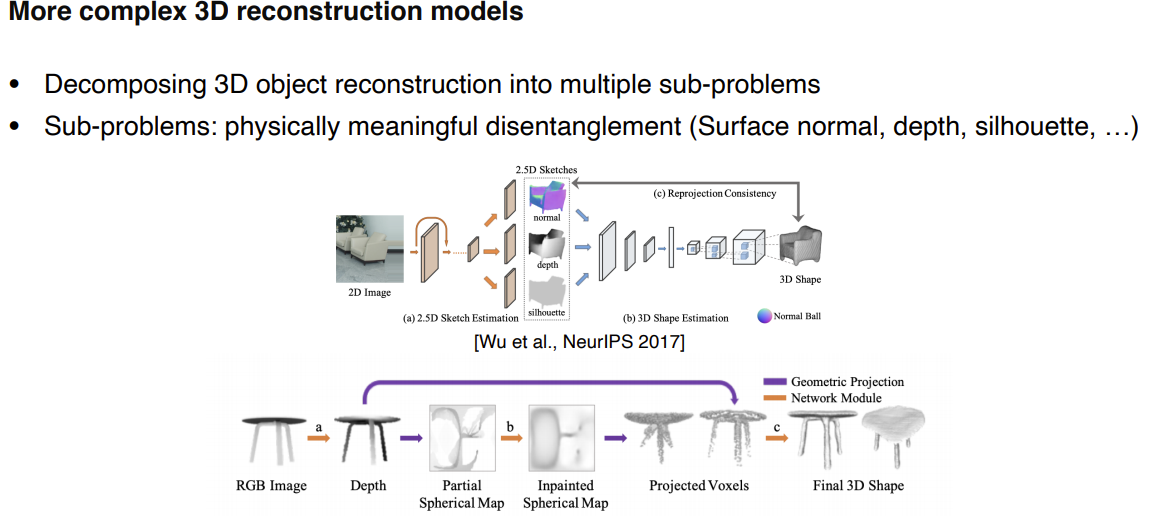
더 복잡한 3D reconstruction model들도 존재한다.
- 3D object를 조금 여러 개의 sub-problem으로 decompose 하면서 더 정교한 3D를 구성하기 위한 방법
- sub-problems : physically meaningful disentanglement, 서브 프라블럼들은 물리적으로 의미 있는 분류, 중간 구성이 사람이 판별 가능한 것들의 구성
- 2D image가 주어지면 CNN의 multi-task head를 이용해서 depth, mask인 실루엣, surface normal을 추정하도록 함. 이것들을 합성해서 Full 3D를 생성
- 다른 방법은 RGB image를 depth형태로 표현 → Spherical Map이라는 도메인으로 바꿔줌, Center점에서부터 방사형 방향으로 값들을 바라보는 map을 생성 → 보이는 부분은 값이 있고 그렇지 않은 부분은 없다, 이것을 추적을 해서 채워줌 → 그 후 3D로 다시 옮겨온다(Voxel)