대회 개요
https://github.com/boostcampaitech3/level2-object-detection-level2-cv-18
정리
개인적으로 정말 많은 시간을 쏟았던 대회이다. 이 대회가 진행되는 동안 게임을 거의 하지도 않을 정도로 정성을 쏟았던 대회이다.
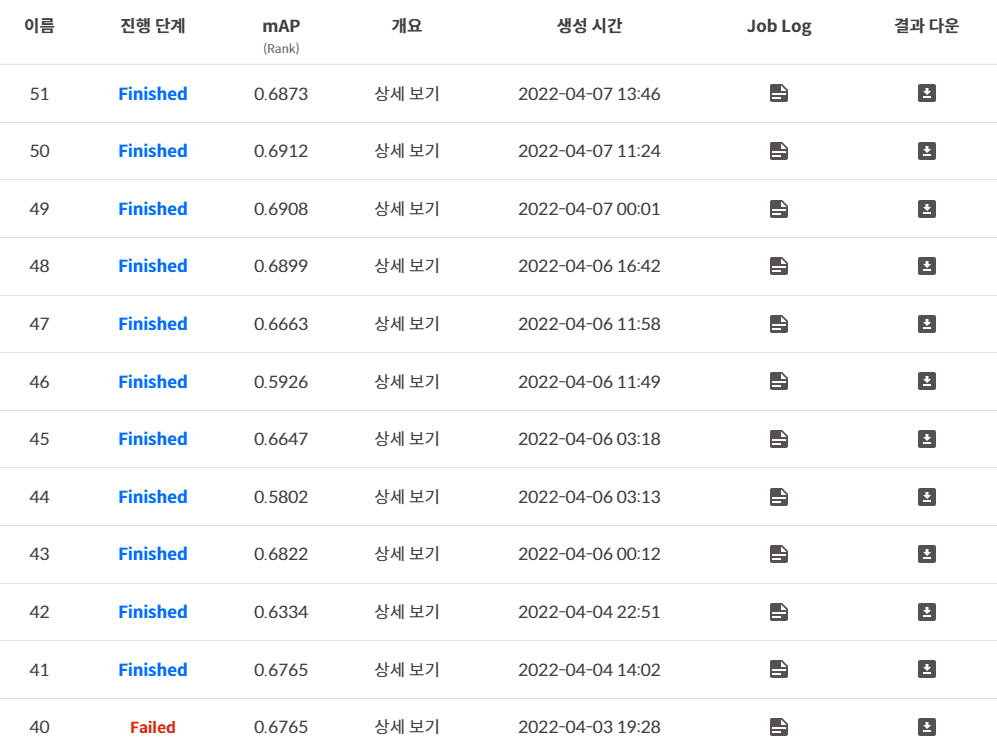
총 제출횟수가 130번정도? 인데 그 중 거의 절반가량을 내가 제출했을 정도로 공을 많이 들인 대회이다.
접근방법
우선 대회 시작부터 YOLO라는 모델이 성능이 괜찮다는 말을 들어서 사용법부터 익혔다. 저번 대회랑 비슷하게 pre-trained된 모델을 불러와서 학습만 시키면 될 줄 알았는데 실상은 전혀 아니었다. 기본적으로 제공된 COCO dataset이 YOLO에는 맞지 않는 dataset이라 그것을 convert2yolo라는 (https://github.com/ssaru/convert2Yolo) 기능을 사용하여 JSON file에서 txt file로 바꿔주는 과정을 수행했다. 그 다음 제공된 데이터셋은 train과 valid가 나눠져있지 않았기 때문에 그것을 8:2로 나누는 과정을 진행했다.(https://github.com/akarazniewicz/cocosplit)
그러나 이렇게 나누면 클래스 불균형 문제가 생길 수 있다.
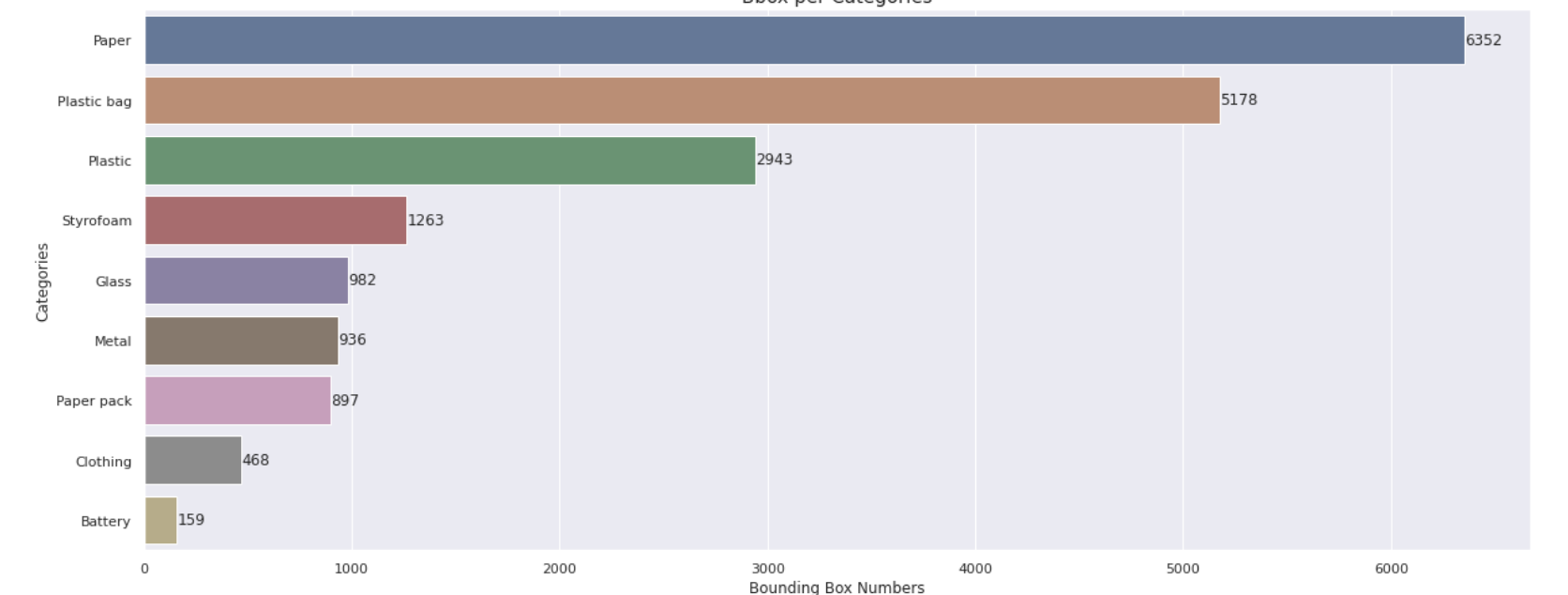
(EDA를 통해 확인한 Train dataset의 클래스 별 분포도)
그래서 추후에 stratified k-fold를 통해 불균형을 해소하는 코드를 작성하여 나중엔 그것으로 학습을 진행했다.
Yolov5를 학습을 시킬때에는 train.py를 구동시켜야하는데 이때 인자로 iou-thres, img size, weight 등의 인자를 받아서 학습을 진행한다. 그리고 multi-scale을 통해 성능을 조금 더 끌어올릴 수 있다는 것을 깨닫고 그것들을 적용해서 학습을 진행했다.
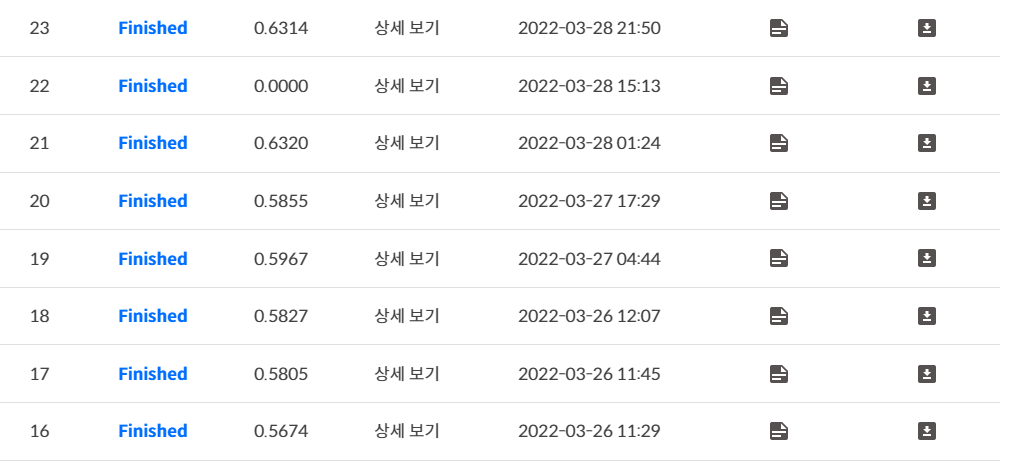
hyper parameter들도 바꿔가면서 최대한 성능을 끌어올려보려고 노력을 많이했었다. 그러다가 나중에 안 사실인데 나는 augmentation을 바꿀 수 없는줄 알고 기본 augmentation만 적용하여 학습을 진행하고있었는데 augmentation.py라는 파일이 따로 존재했었다. 그곳에서 새롭게 augmentation을 조정해서 학습을 진행시켜서 더 좋은 결과를 내게 되었다.
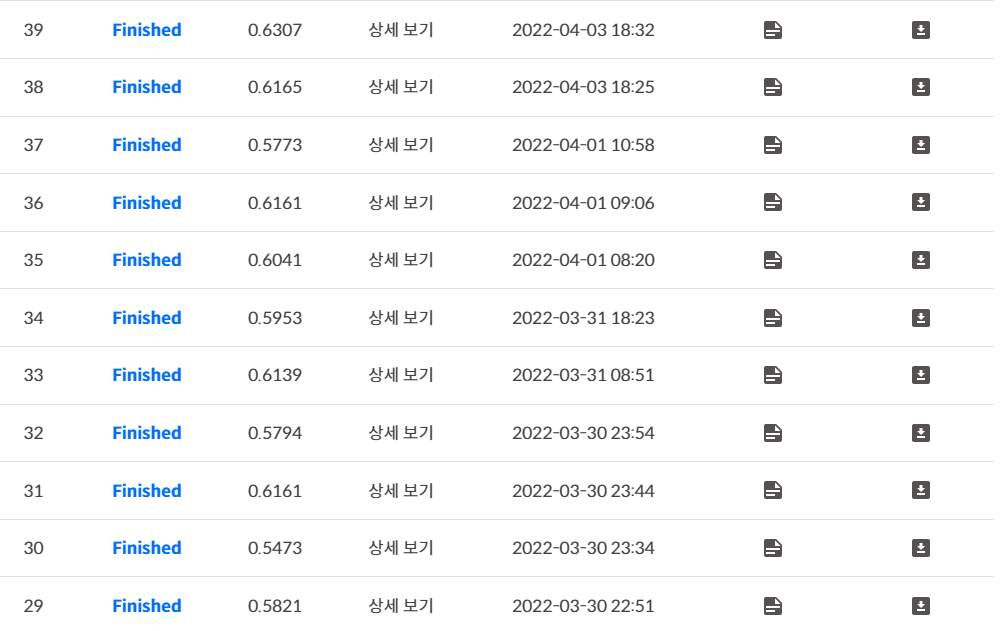
그리고 지금까지 했던 것들중 잘 나온 것들을 합치는 ensemble작업과 학습한 결과를 바탕으로 test dataset에 넣어서 나온 예측값들을 합쳐서 다시 학습을 진행하는 pseudo labeling까지 한 결과 다음과 같은 성능을 얻게 되었다.

나는 이것을 YOLOv5에서 낼 수 있는 최고의 성능이라고 생각을 했고(물론 더 시도하면 올라갈 여지는 충분히 많지만 시간이 없었다.) 다른 모델과 ensemble을 하기위해 Swin 모델을 학습시켜보기로 생각을 했다.
Swin은 YOLO와는 다르게 수업시간에 알려준 방식대로만 해도 학습을 진행시킬 수 있었다. baseline으로 제공된 fast_rcnn train과 inference를 통해 학습을 진행하고 inference까지 할 수 있는데 swin_L을 적용하기 위해선 config 파일을 수정하는 작업이 필요했다. 처음엔 막상 어려웠지만 구조를 파악하고 난 뒤에는 크게 손댈 곳이 없었다. 다만 시간이 엄청나게 오래걸렸기 때문에 12 epoch밖에 학습을 진행하지 못했다. 그렇게해서 나온 값이 
아무 효과도 적용하지 않고 multi-scale만 적용했을 뿐인데 꽤 괜찮은 성적이 나왔었다. 그것을 바로 ensemble을 적용해보니
꽤 많은 성적 향상을 경험할 수 있었다. 이것으로 다양한 모델을 ensemble 시키는 것이 매우 중요하다는 것을 깨닫게 되었다. Swin 모델에서의 아쉬운 점은 너무 늦게 시작을 해서 pseudo-labeling도 ensemble도 해볼 시간이 없었다. 그래서 결국 한번 돌려서 학습한 결과만 최종 ensemble된 결과에 반영이 되게 되었다. 최종 점수는 다음과 같다.

아쉬운 점
모델적인 측면에서 접근하기 이전에 데이터적인 측면에서 labeling 수정을 통해 좀 더 깔끔한 학습 데이터셋을 만들어보고 싶었는데 그렇지 못했다. 시간이 너무 부족해서 하고싶었던 시도를 다 하지 못했던 점 또한 많이 아쉽다. 더 다양한 모델들을 돌려보고 ensemble시켜보고 싶었느데 그렇지 못했던 점이 너무 아쉽고 그렇게 했다면 0.7을 넘지 않았을까 하는 생각이 든다.
의문점
박스를 무조건 많이 치면 점수가 높게 나오기는 한다. 그러나 원본 사진조차 알아볼 수 없을 정도로 많이쳐지는데 이것이 점수가 더 높은것이 모순이라고 생각이 들고 이 지표가 모델의 성능 평가 지표라는데에 의구심이 들었다. 그리고 또 한가지 ensemble에 관한 것인데 좋은 score을 기록한 모델끼리 합쳤는데 오히려 그렇지 않은 것들도 섞어서 합친것이 점수가 높게 나왔다. 어떤 기준으로 ensemble을 해야하는지 명확한 기준이 서지 않아서 나중에는 학습한 결과물들이 10개정도 되었는데 어떤것들을 합칠까 고민이 많이 되었다.
결론
첫번째 대회보다 성적이 잘 나오지 않아서 많이 아쉬웠다. 그러나 개인적으로 시도한 것이 많았던 대회였고 전반적으로 YOLO의 구조와 Swin이 있는 MMdetection의 구조를 공부할 수 있어서 굉장히 뜻깊었던 대회였다.

혹시 convert2yolo 사용법에 대해 정확하게 알수있을까용??