[논문리뷰] R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation
논문
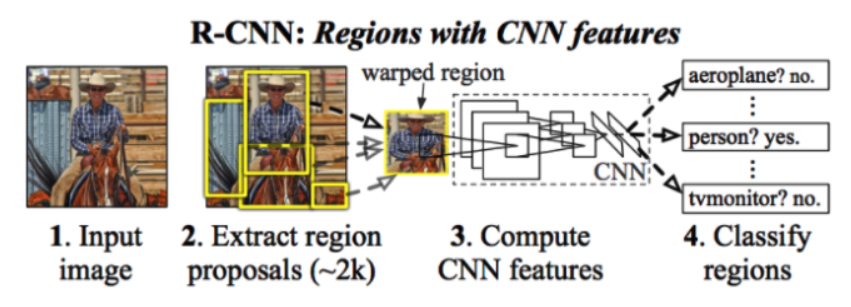
R-CNN
Object Detection
Object Detection이란 물체의 위치 정보를 파악하는 Localization과 어떤 물체인지 분류하는 Classification을 모두 수행하는 알고리즘이다.
Object Detection은 크게 1-stage Detector와 2-stage Detector로 분류된다.
- 1-stage Detector: Localization과 Classification을 동시에 해결하여 비교적 빠르지만 정확도가 낮고, YOLO 계열과 SSD 계열의 모델들이 대표적
- 2-stage Detector: Localization과 Classification을 순차적으로 해결하여 비교적 느리지만 정확도가 높으며, R-CNN 계열의 모델들이 대표적
관련 논문들의 동향은 다음과 같다.

Abstract
그동안 PASCAL VOC 데이터셋에서의 Object Detection은 여러 개의 low-level 이미지 특징들과 high-level context를 결합하는 앙상블 방식을 통해 가장 높은 성능을 보였다. 이 논문은 단순하고 확장 가능한
알고리즘을 통해 mAP(mean average precision)을 30% 향상시켰으며 두 가지 핵심 인사이트는 다음과 같다.
- 객체의 위치를 찾고 분리하기 위해 bottom-up 방식의 region proposal에 CNN을 적용하였다.
- 라벨링이 된 데이터가 부족할 때, supervised pre-training에 이은 domain-specific fine-tuning 성능을 크게 향상시켰다.
Introduction
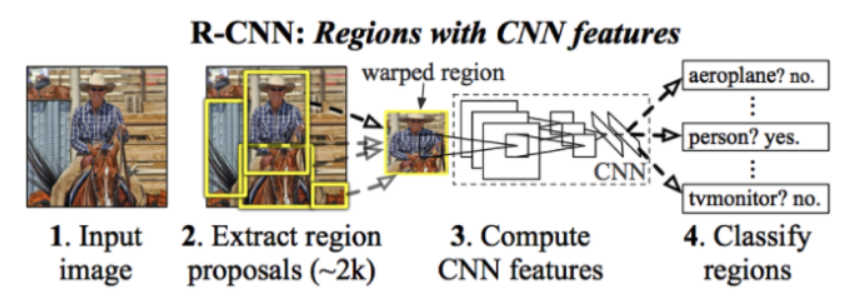
R-CNN의 구조는 다음과 같다.
- 이미지를 iniput으로 집어 넣는다.
- 2000개의 영역을 추출한다.(Selective Search 알고리즘)
- CNN모델을 통해 특징 벡터를 도출한다.
- SVM을 통해 각 영역을 분류한다.
Modules
R-CNN은 2-stage Detector이므로 물체의 위치를 찾는 Region Proposal과 물체를 분류하는 Region Classification을 하게 되는데 이를 위해 3가지 모듈이 구성되어 있다.
- 독립적인 물체의 영역을 생성한다.
- CNN을 이용하여 각 영역으로부터 고정된 크기의 특징 벡터를 추출한다.
- Linear SVM을 통해 영역의 class를 분류한다.
Region Proposal

영역을 생성하는 과정에서 R-CNN은 selective search 알고리즘을 사용한다.
Selective search는 segmentation 분야에서 널리 쓰이는 알고리즘으로 객체와 주변간의 색감, 질감 차이, 다른 물체에 애워쌓여있는지 여부 등을 파악하여 Bounding box들을 형성한다.
위의 그림을 보면 처음에는 Random하게 많은 Bounding box들을 생성한 뒤 점점 합쳐나가면서 물체를 인식하는 방향으로 학습함을 알 수 있다.
Feature Vector

Selective Search를 통해 생성된 각각의 region proposal들을 224x224 픽셀 사이즈로 warping 한 뒤 CNN에 넣어 4096차원의 특징 벡터들을 추출한다.
R-CNN에서는 AlexNet을 사용하며 분류는 SVM을 통해 할 것이기 때문에 softmax는 포함하지 않는다.
Classification
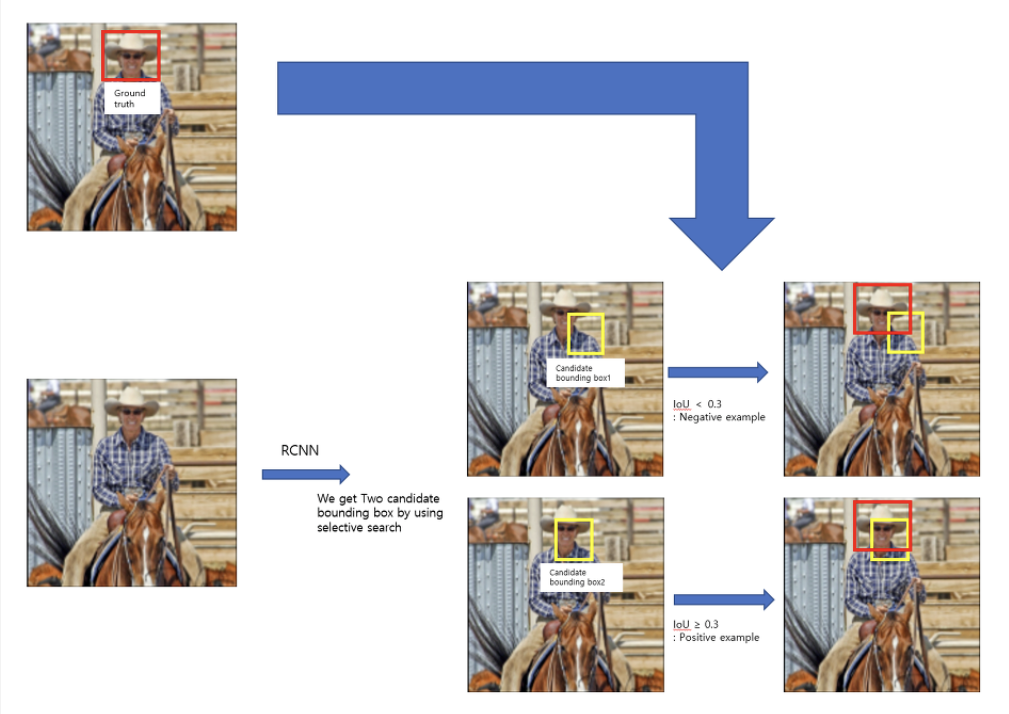
추출한 특징 벡터들은 positive example에 한해서만 SVM을 통해 분류한다.
각 영역은 Ground truth(실제값)와의 IOU가 임계값 이상인 경우 객체를 포함하고 있을 가능성이 높다고 판단하며 학습을 진행하는 반면, IOU가 임계값 이하일 경우에는 배경으로 인식하여 학습을 하지 않는다.
여기서 IOU란 두 영역이 겹치는 부분의 비율을 나타내는 것으로 Ground truth와 겹치는 부분이 많다면 객체를 표시하는 영역이라 볼 수 있고 반대의 경우에는 객체와 무관한 배경이라 보는 것이 타당함을 쉽게 알 수 있다.
Non Maximum Suppresion(NMS)

SVM을 통과한 바운딩박스들은 score를 가지게 되고 한 객체에 대해 여러 바운딩박스가 그려져있는 상태이므로 이 score를 이용하여 최적의 박스를 고르는 NMS를 수행하게 된다. NMS의 과정은 다음과 같다.
- 임계값 이하의 score를 가지는 박스는 제거한다.
- score를 기준으로 내림차순 정렬한 후 한 객체에 대해 가장 높은 score를 가지는 박스와의 IOU가 일정값 이상인 박스들을 전부 제거한다.
Bounding Box Regression
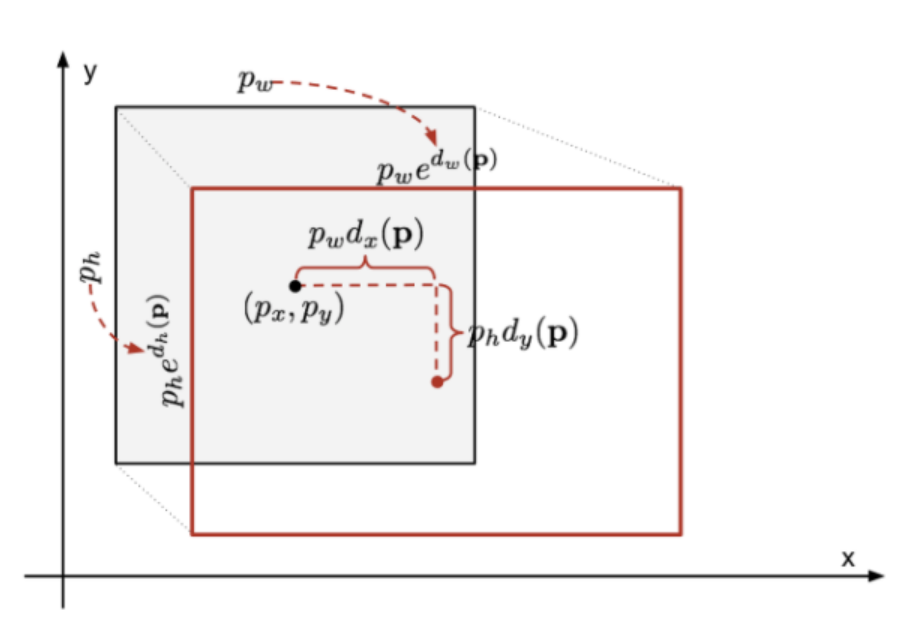
selective search를 통해 얻은 Bounding Box는 Ground truth와 완벽하게 일치하지 않을 수 있기 때문에 조정 과정이 필요하다. 즉, Ground truth와 최대한 가까워질 수 있도록 loss function을 통해 조정하는 regression 문제로 정의하게 되는데 수식은 다음과 같다.
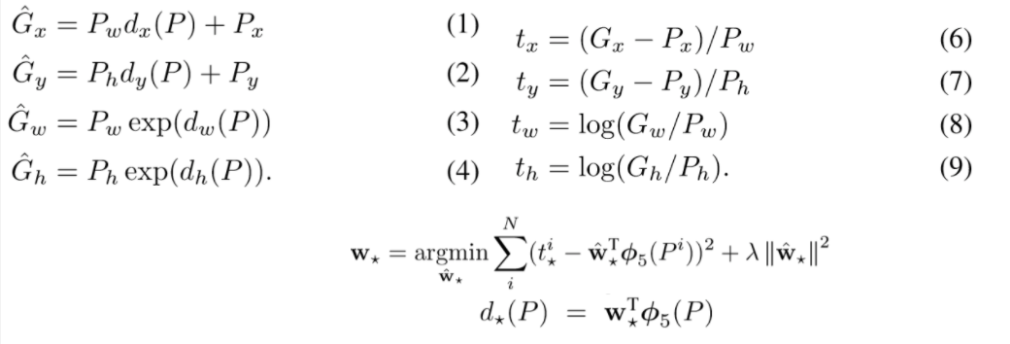
는 각각 좌표(위치), width(너비), height(높이)를 의미하며, 는 Bounding box, 는 Ground Truth(실제값)이다.
아래의 식에서는
: CNN에서 학습된 에 해당하는 특징 벡터
: 특징벡터를 4차원 벡터로 만들어주는 Linear layer의 학습되는 가중치
: 릿지 회귀에서 regularization을 위한 상수
를 통해 라는 transformation 함수를 정의할 수 있으면 를 추정할 수 있다.
(1),(2),(3),(4)의 은 와 최대한 가까워질 추정량을 의미하므로 이 식을 변형시킨 (6),(7),(8),(9)의
(의 치환)는 최종적으로 결정되는 함수라고 할 수 있다.
따라서, 와 의 차이를 최소화시켜주는 loss function이 적용되어 Bounding Box의 위치, 크기가 조정된다.
Pre-training/Fine-tuning
앞서 언급했듯이 R-CNN에는 AlexNet이 쓰이는데 이를 새로 만들어 Pascal VOC 데이터로 학습시키는 것이 아니라 기존에 ILSVRC 2012에서 학습된 모델을 사용한다. 이를 pre-training이라고 말하며
두 데이터셋의 객체들의 형태가 크게 다르지 않을 것이므로 pre-trained model에 Pascal VOC dataset을 조금만 학습시키는 fine-tuning을 거치면 좋은 성능을 보이는 모델을 만들 수 있다.
이러한 방식은 학습시간을 줄일 수 있고, 더 많은 데이터셋을 활용할 수 있다는 점에서 매우 효율적이다.
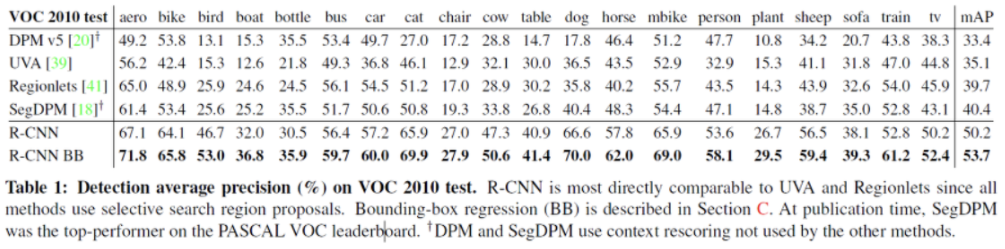
Result
References
https://nuggy875.tistory.com/21
