Two Challenges
Efficient multi-scale feature fusion
- 기존의 연구들은 multi-scale feature fusion을 사용할 때 단순하게 합하는 방식을 사용해왔다.
- 하지만 서로 다른 input features는 output features에 미치는 영향이 다를 것이므로 본 연구에서는 그 중요도에 따른 가중치를 학습할 수 있도록 만들어주었다.
Model scaling
- 정확도를 향상시키기 위해 input size를 키우거나 layer를 더 쌓는 등의 방식들이 사용되어 왔고 EfficientNet에서는 resolution, width, depth의 스케일을 전부 적절히 조절하는 Compound Scaling을 제안했다.
- EfficientDet 역시 compound scaling method를 사용하였으며 EfficientNet의 backbone, BiFPN, Class/Box prediction network에 전부 적용하였다.
- 그 결과 적은 파라미터와 FLOPs를 가졌음에도 불구하고 정확도에 있어 더 향상된 모습을 보일 수 있었다.
BiFPN
Problem Formulation
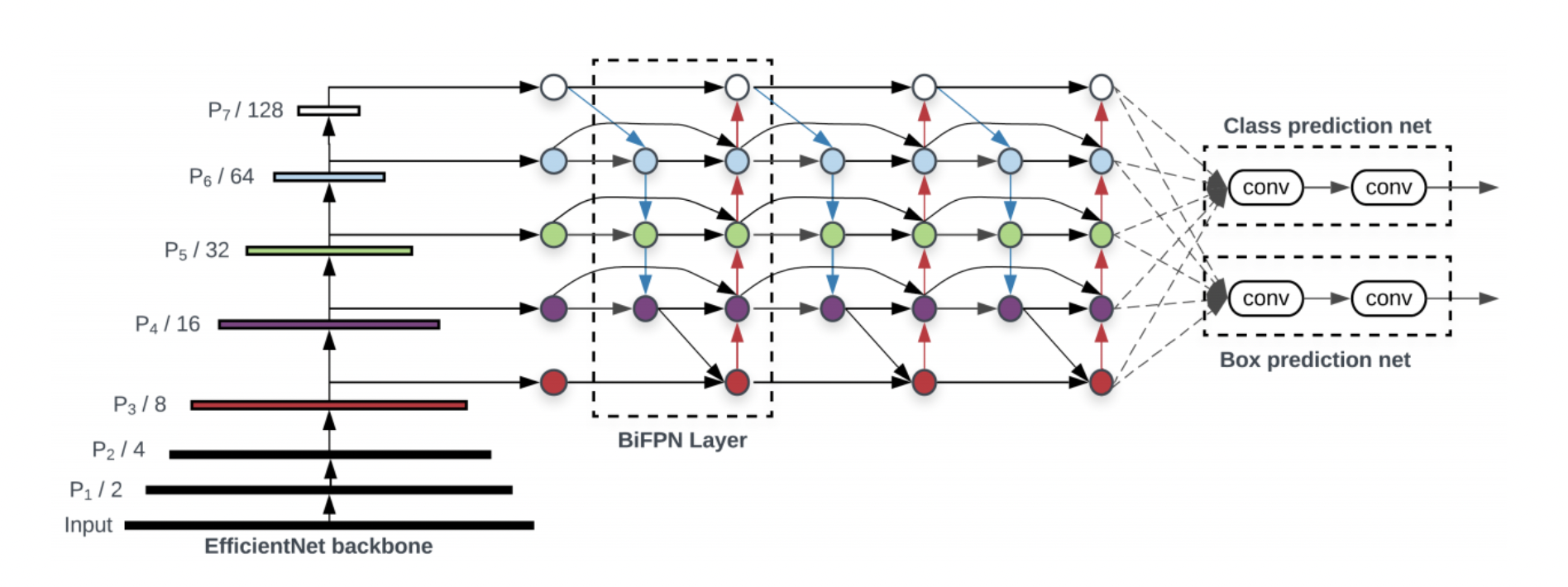
에서 는 레벨 에서의 feature map을 의미하며 BiFPN에서는 이 feature map들을 효과적으로 결합하여 output을 만들어낼 수 있는 함수 를 찾고자 하였다. ()
- level 3-7의 input features를 사용하며 은 resolution의 feature을 의미한다.
- 예를 들어, 640 x 640 이미지의 level3 feature는 이므로 80 x 80의 이미지가 된다.
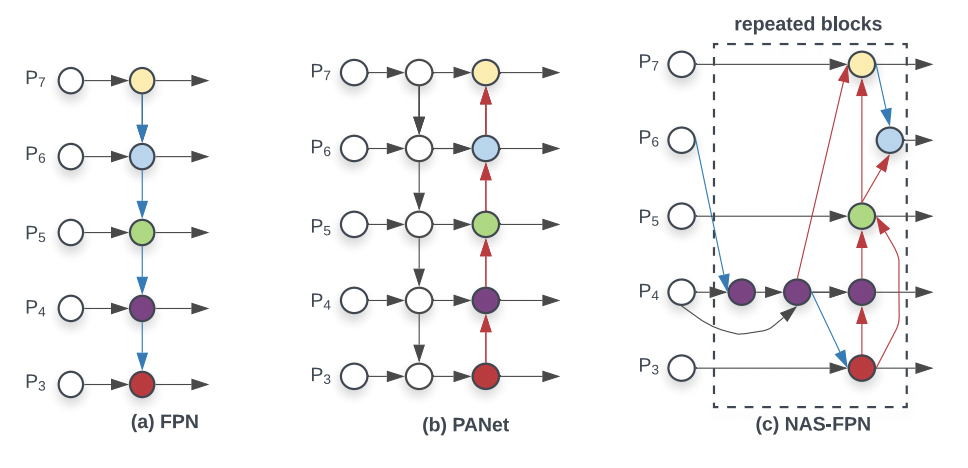
- FPN에서는 top-down 방식으로 여러 스케일의 feature map들을 합쳐주었고 단순하게 resize 후 convolution을 수행한다.
- PANet에서는 bottom-up 방식을 추가하였다.
- NAS-FPN에서는 아키텍쳐를 직접 설계하지 않고 neural architecture search를 통해 학습하는 방식을 사용하였으나 시간이 오래 걸리고 해석이나 수정하는데 있어 어려움이 있다는 단점이 있다.
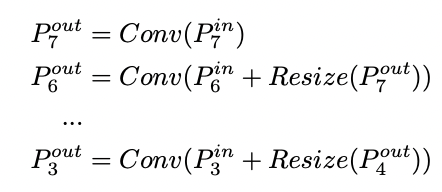
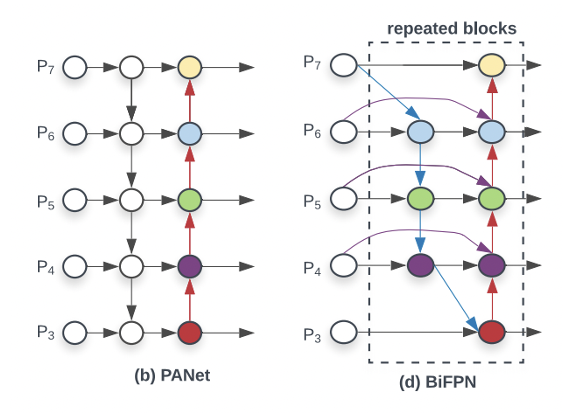
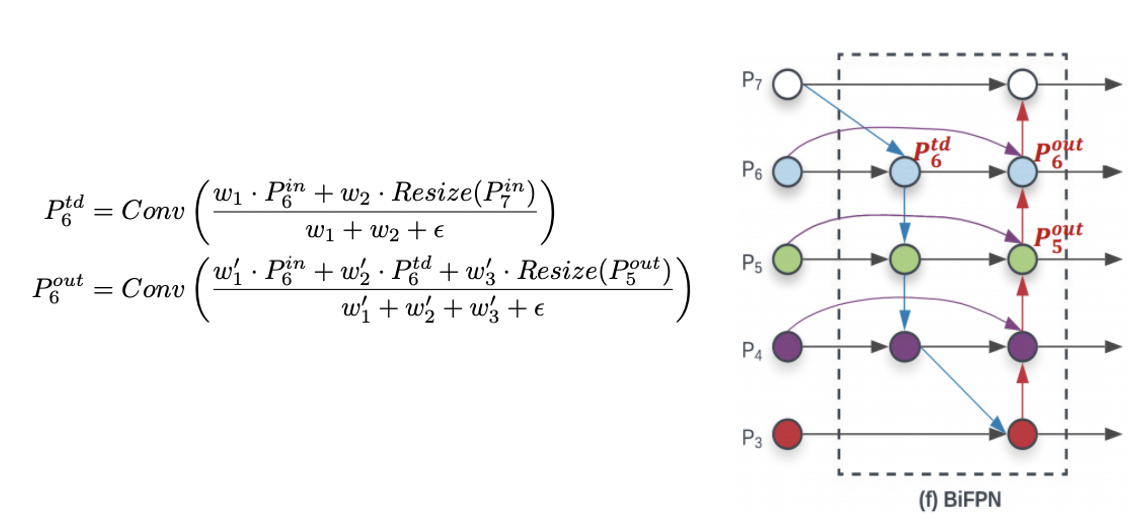
위 세 개의 구조 중 PANet이 가장 높은 정확도를 보였고 BiFPN은 PANet에서 3가지의 변화를 주어 설계되었다.
- input edge가 하나인 노드들은 영향력이 적을 것이므로 제거해주었다.
- 더 많은 feature fusion을 하기 위해 보라색 엣지를 추가해주었다.
- 점선으로 된 layer 구조를 여러번 반복하여 high-level feature fusion이 가능하게 해주었다.
Weighted Feature Fusion
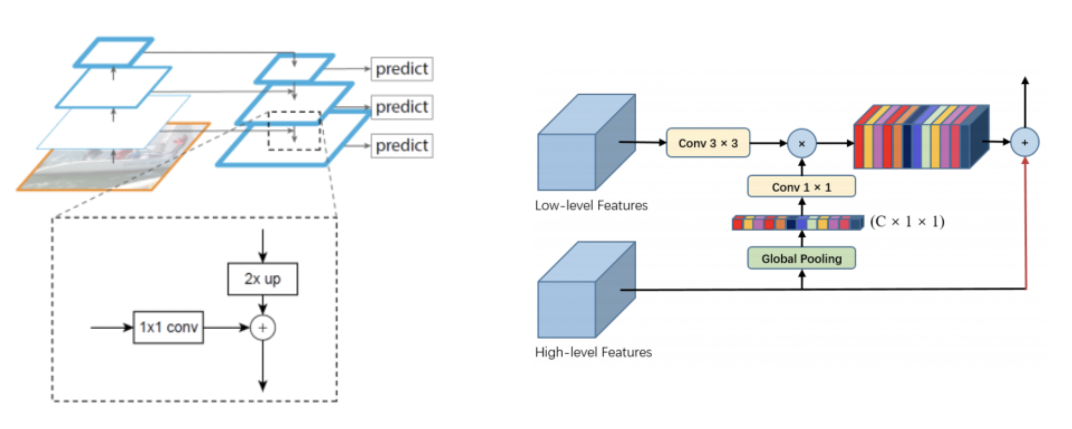
이전 연구들에서는 Feature fusion을 할 때 위와 같이 같은 resolution으로 resize를 하여 단순히 합해주거나 global self-attention upsampling을 사용하였다.
EfficientDet에서는 input이 output에 얼마나 영향을 미치냐에 따라 가중치를 부여하였으며 발전 과정은 다음과 같다.
Unbounded fusion
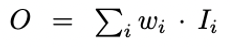
- featur map에 weight를 곱해 합해주는 방식
- 는 scalar(per-feature)일수도, vector(per-channel)일수도, multi-dimensional tensor(per-pixel)일수도 있다.
- scalar weight 값이 무한하여 학습이 불안정하다는 단점
Softmax-based fusion
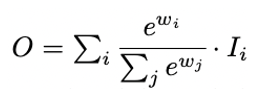
- Unbounded fusion의 단점을 보완하기 위해 weight가 0과 1 사이의 값을 가지도록 Softmax를 활용한다.
- GPU에서 연산 속도를 떨어뜨린다는 단점
Fast normalized fusion
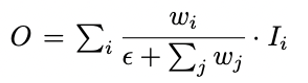
- 정규화를 할 때 단순히 모든 가중치의 합으로 나눠준다.
- 단, 이때 가중치들은 Relu를 통과하여 0 이상의 값을 가지며, 분모가 0이 되지 않도록
=0.0001을 더해준다. - softmax-based fusion과 유사한 성능을 보이면서 속도는 30% 개선
EfficientDet
Architecture
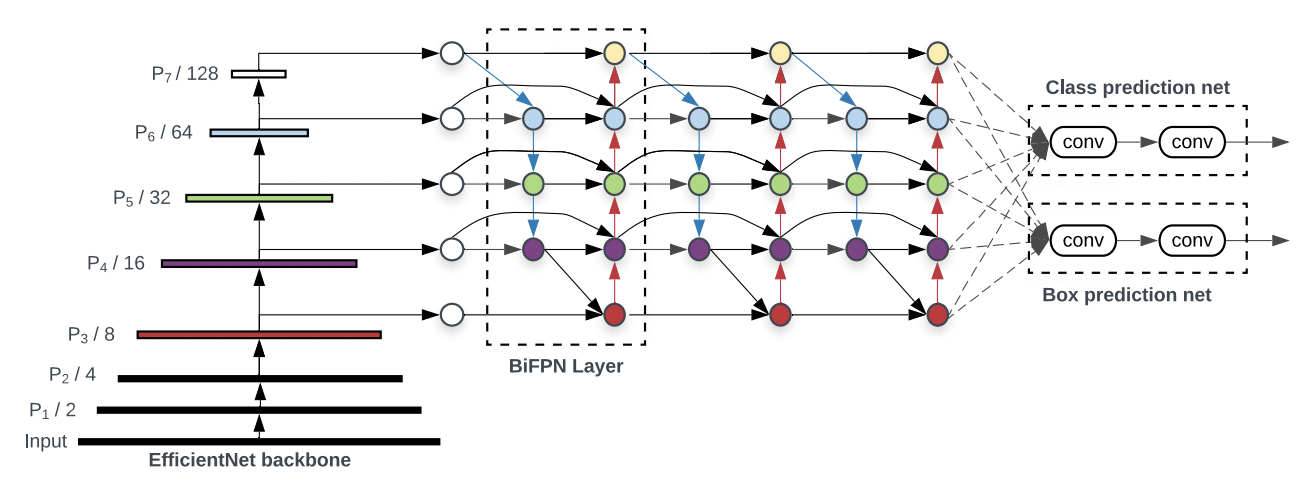
ImageNet에 pretrained된 efficientnet을 backbone으로 사용하며 레벨 3-7을 BiFPN에서 반복하여 fusion해준다. 이후 output을 clssification / box prediction network을 통해 detection을 수행한다.
Compound Scaling
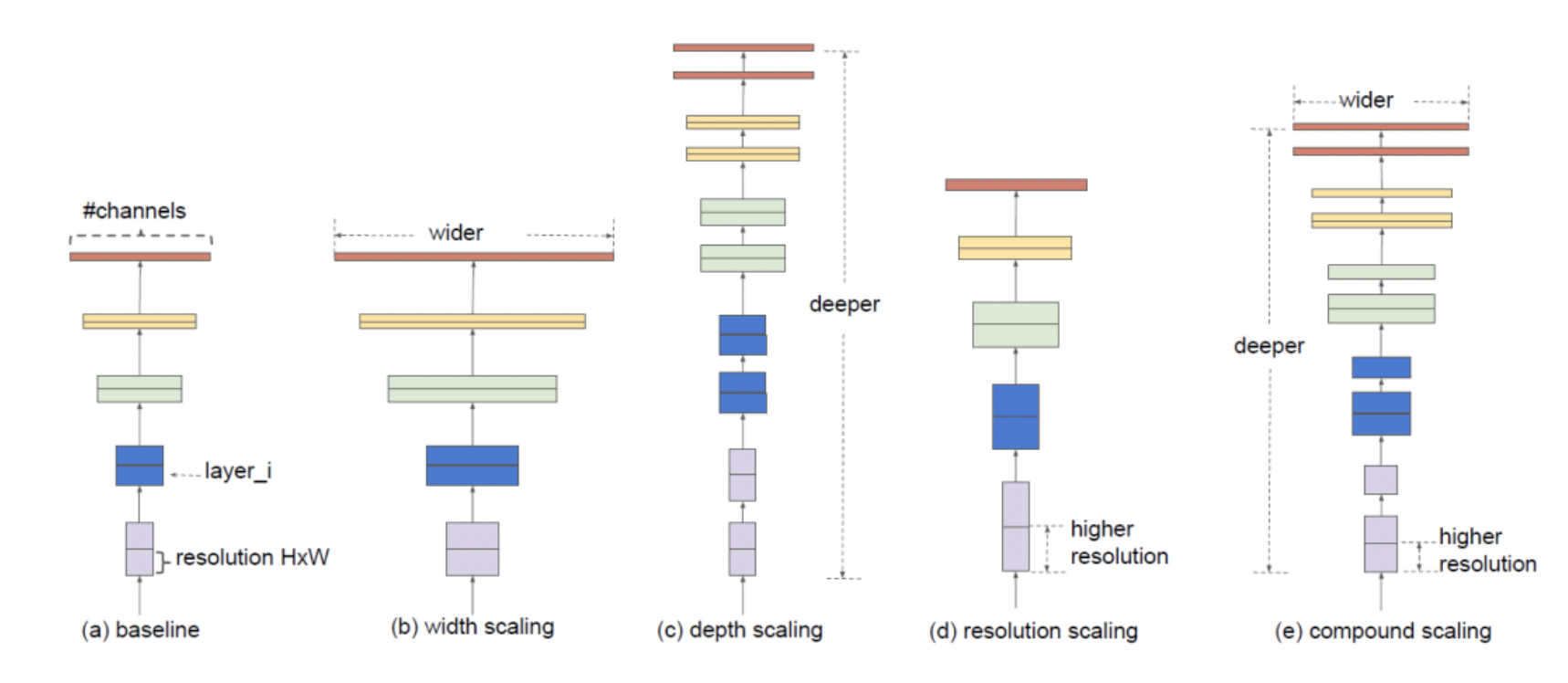
width(channel)을 늘리거나 depth(layer)를 늘리거나 resolution을 늘리는 다양한 방식들이 있으나 본 연구에서는 이 세가지를 전부 적절히 늘려 효율적인 모델을 구축하고자 하였다.
object detector는 classification에 비해 많은 scaling dimensions를 가져 그리드서치를 하는 것은 아주 큰 연산량을 요구한다. 따라서, 경험과 직관을 통해 일반적으로 좋거나 보다 간단한 해결법을 찾는 heuristic scaling approach를 사용한다.
Backbone network
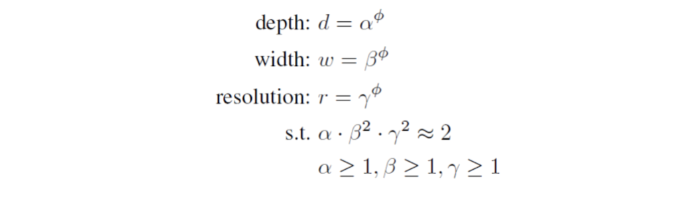
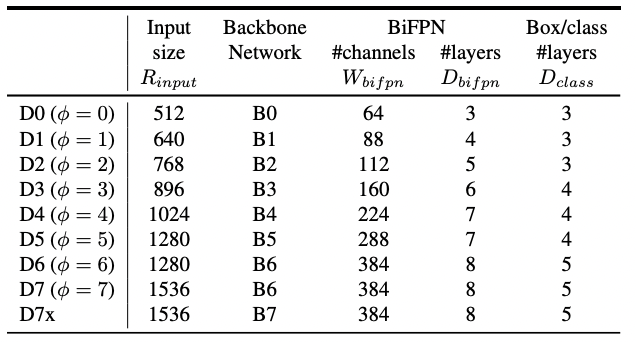
backbone에서는 EfficientNet-B0 to B6의 width/depth scaling coefficient를 그대로 사용한다.
는 그리드서치에 의해 결정되는 상수이며, 는 사용자가 설정할 수 있다.
BiFPN network
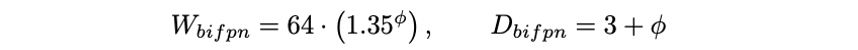
BiFPN에서는 width(channel)은 지수적으로, depth(layer)는 선형적으로 증가시켜준다.
width는 {1.2, 1.25, 1.3, 1.35, 1.4, 1.45} 중 그리드서치를 통해 최적값인 1.35를 선택하였고 depth는 heuristic하게 정수가 나올 수 있도록 설정해주었다.
Box/class prediction network
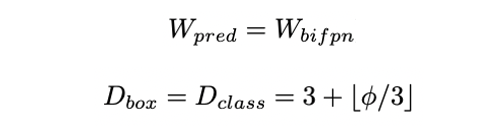
Box/class prediction network의 width는 BiFPN과 동일하게 유지하며 depth는 를 3으로 나눈 값은 내림한 후 3을 더해준다.
Input image resolution
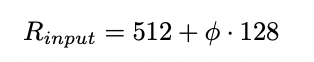
resolution은 BiFPN에서 level 3-7을 사용하므로 level7에 해당하는 을 적용할 수 있도록 128을 배수가 되게 만들어준다.
Compound scaling의 조합을 표로 정리하면 다음과 같다.