Introduction
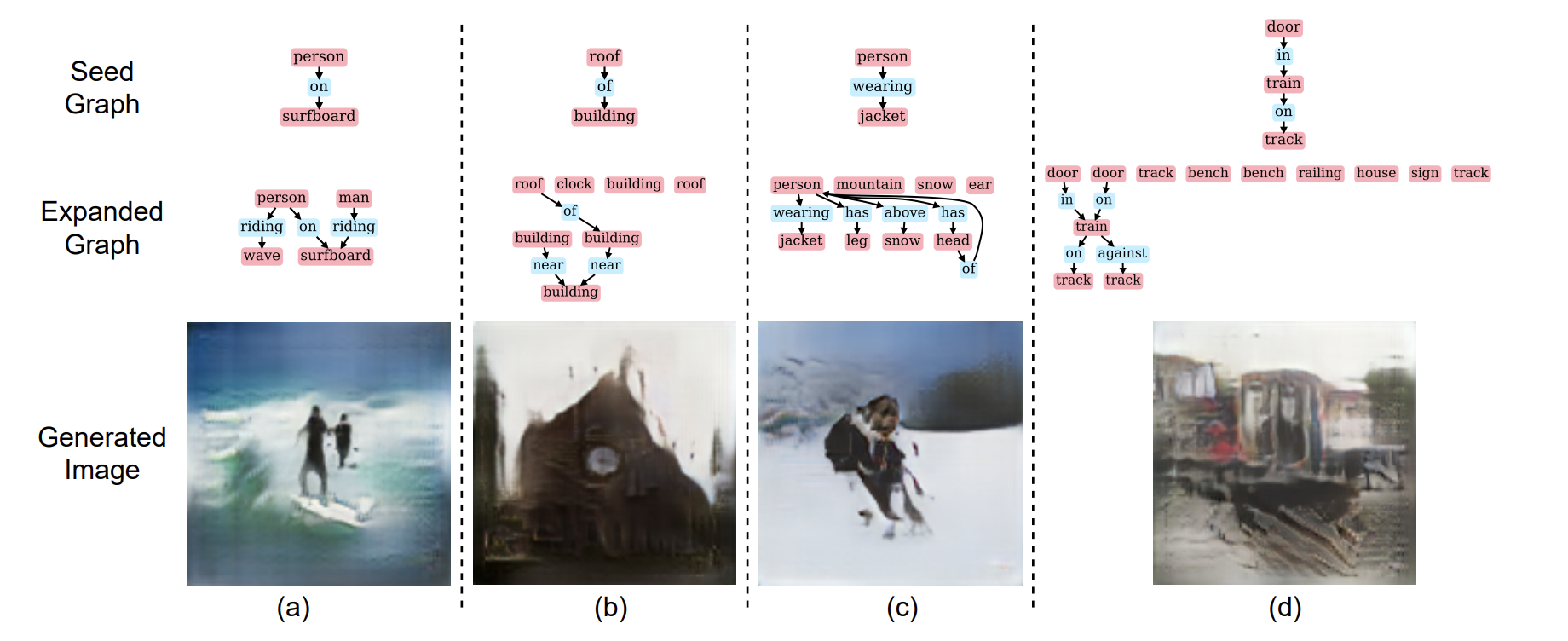
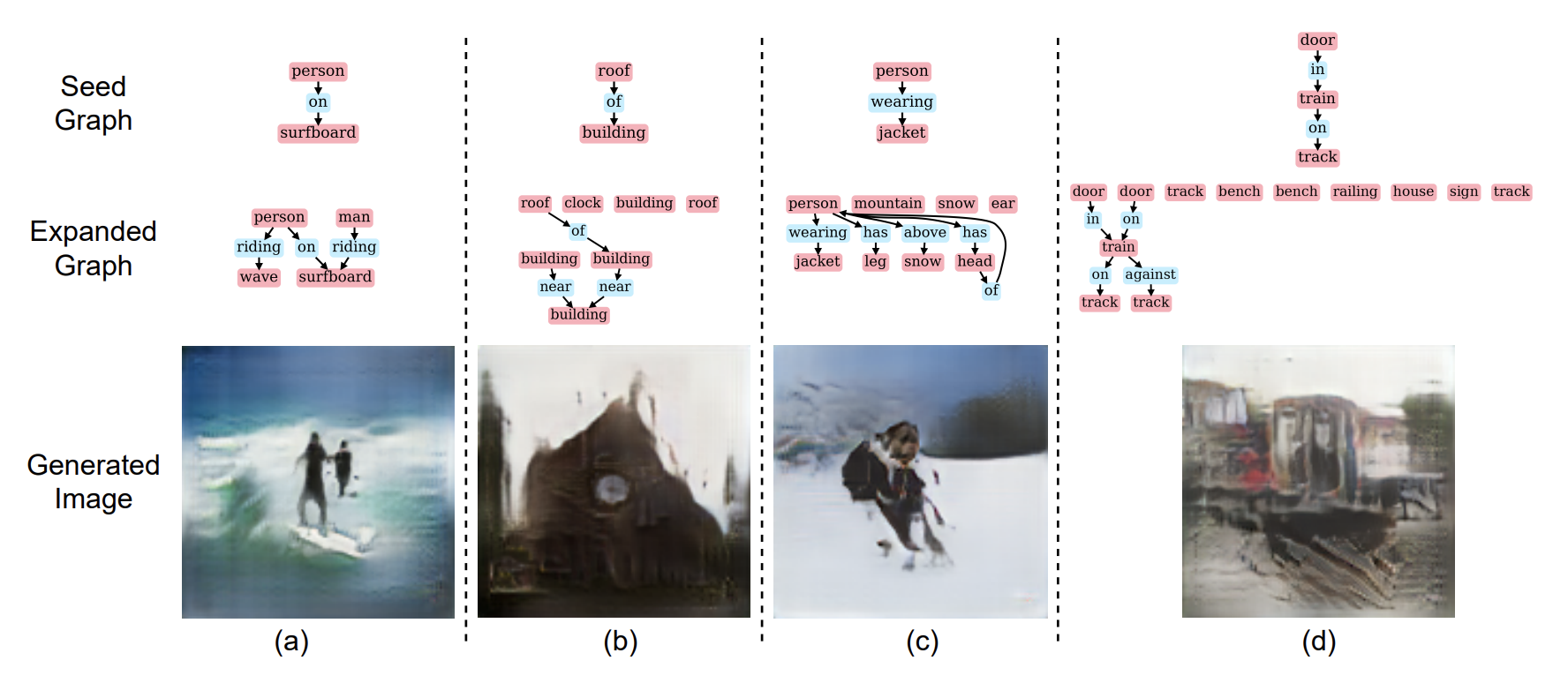
- 본 논문에서는 seed concept을 포함하는 다양한 scene을 제공해줄 수 있는 알고리즘을 제안한다.
- Scene graph expansion을 통해 seed graph에 새로운 object들을 추가하며 이 때 충족해야할 조건들은 다음과 같다.
- 제안되는 추가 object는 training dataset에서의 co-occurence pattern이 반영되어야 한다.
- Enhanced scene graph는 기존 그래프와는 다른 새로운 그래프여야 한다.
- 같은 seed graph에 대해 여러 개의 다른 그래프를 생성해야 한다.
- 최근에 molecular graph에 대해 auto-regressive하게 확장하는 연구들이 있었지만 scene graph에는 적합하지 않은 특성들이 존재하기 때문에 새로운 auto-regressive graph expansion model을 제안한다.
- Node prediction의 일반화를 위해 external knowledge를 활용한 새로운 loss를 제안한다.
- 기존의 evaluation metric의 단점을 보완한 새로운 metric을 제시한다.
Method
Cluster-Aware BFS
- GraphRNN에서는 BFS를, GraphGen에서는 DFS를 통해 ordering을 하지만 두 방식 모두 fully connected graph를 전제로 한다는 문제가 있다.
- Scene graph에서는 disconnected graph가 존재하며 빈번하게 함께 발생하는 object들이 sequence에서 가깝게 위치하기를 기대한다.
- 각 subgraph 내에서는 BFS를 통해 배열하며 subgraph끼리는 random order를 적용하여 input seed graph에 robust한 모델을 만든다.
- Scene graph에 대한 matrix 는 번째 노드 이전의 정보를 담은 로부터 번째 노드 와 와 로부터 예측한 엣지 의 곱으로 구한다.
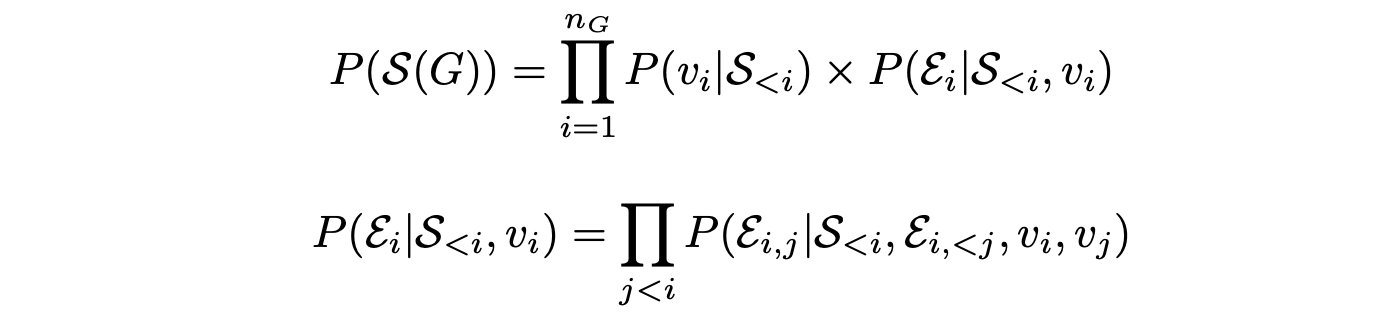
Hirarchical Node and Edge Prediction
- 각각의 RNN 네트워크를 통해 노드를 먼저 예측한 후 그 노드와 이전 노드들 사이의 엣지를 예측한다.
- 번째 노드의 예측은 이전 노드의 정보와 이전 스텝에서의 의 hidden state를 통해 구한다.
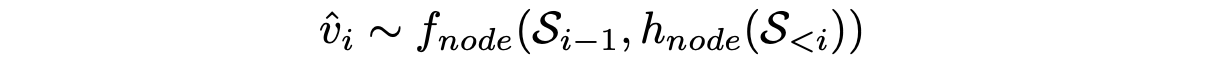
- 엣지는 양방향으로 예측하며 local context가 중요하기 때문에 를 explicit하게 input으로 준다.
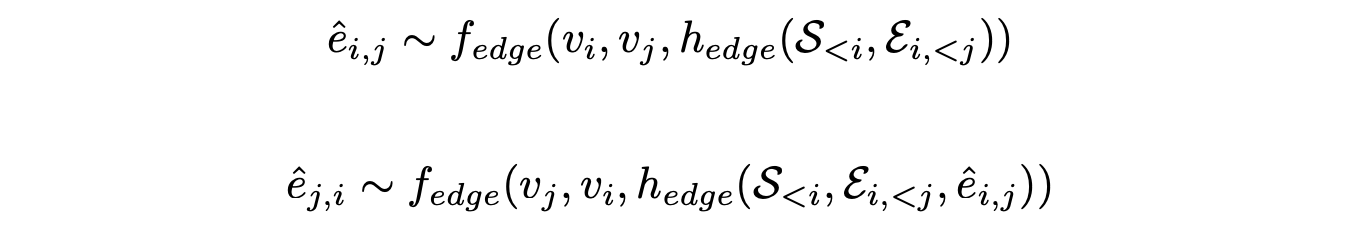
- Loss를 cross entropy 를 활용하며 엣지는 class imbalance 문제를 해결하기 위해 데이터셋 내에서의 해당 엣지의 개수를 통해 weight를 준다.
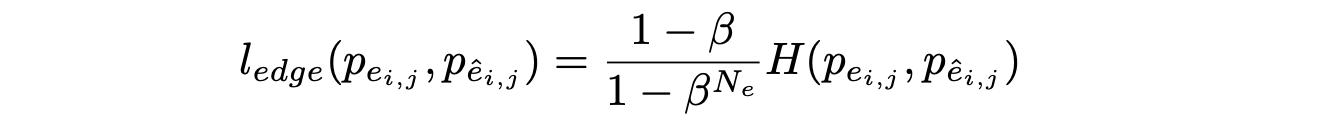
External Knowledge
- Cross entropy는 stric한 loss로 유사하게 예측한 것과 명백히 다르게 예측한 것의 구분이 없다.
- 따라서 language domain의 external knowledge를 활용한다. 는 예측 노드와 ground truth 사이의 similarity를 의미한다.
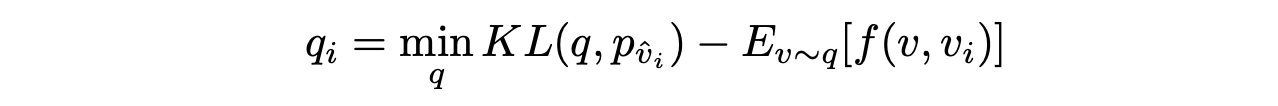
- 노드에 대한 loss는 기존의 cross entropy loss와 유사도를 고려한 벡터와의 cross entropy loss를 모두 활용한다.
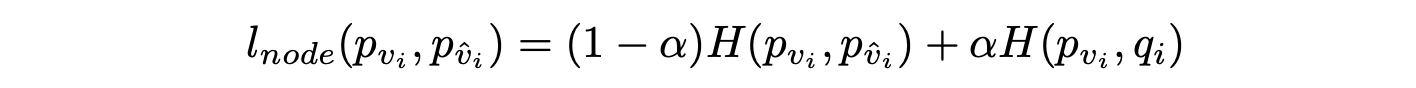
Experiments
Common Evaluation Metric
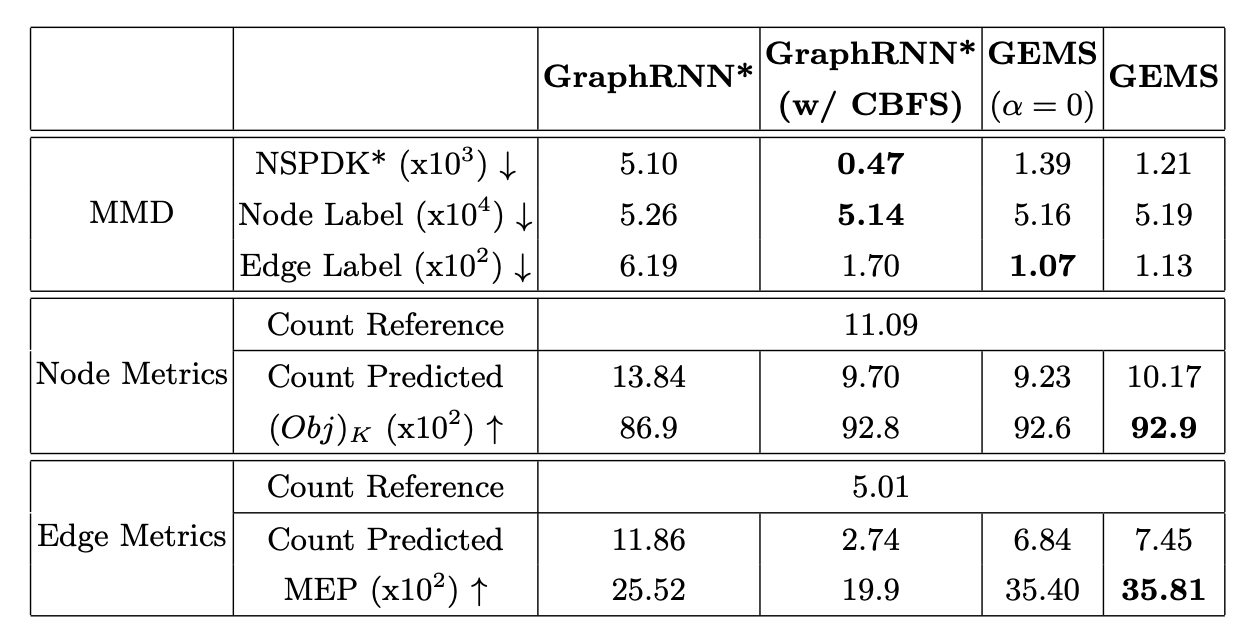
- Graph generation에서 사용되는 일반적인 metric은 Maximum Mean Discrepancy(MMD)로 두 그래프를 비교한다.
- 그래프의 distribution을 뽑아내는 descriptor function과 distribution의 거리를 측정하는 kernel function으로 구성된다.
- Descriptor function은 노드 및 엣지의 수, node degree 등의 정보를 담은 Structural, 노드 및 엣지의 type을 담은 Label, sub-graph들의 유사도를 담은 Sub-Graph Similarities를 인코딩한다.
- Novelty를 측정하기 위해서는 GraphGen에서 제안한 방식을 사용하며 확장된 scene graph가 training set의 그래프와 isomorphic한지를 측정한다.
New Metric
- 본 논문에서는 scene graph generation을 측정하기 위한 2가지의 metric을 제안한다.
Top-K Object Co-occurence
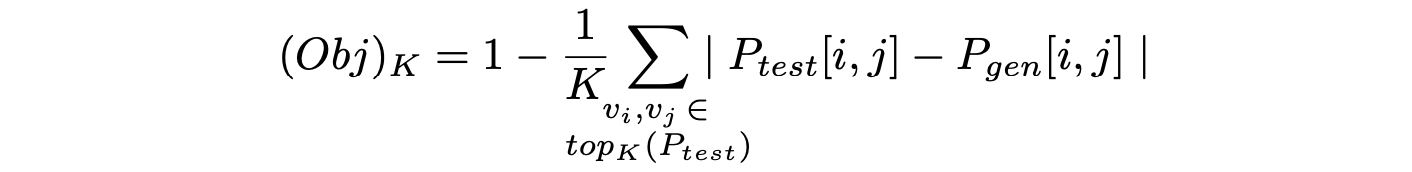
-
Co-occurence는 어떤 object가 그래프에 존재할 때 다른 object가 있을 조건부확률로 정의할 수 있다.
-
위 식을 통해 test set과 generated set의 co-occurence를 비교한다.
-
은 각각 test set과 generated set에서의 co-occurence 값이 담긴 matrix를 의미한다.
Modified Edge Precision(MEP)
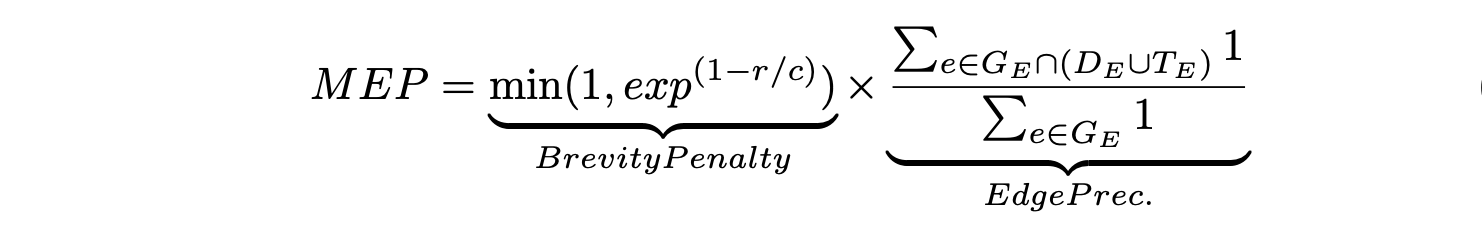
- 는 각각 generated graph, trainig graph, test graph에서의 directed edges set를 의미한다.
- 은 reference graph의 평균 edge의 수, 는 확장된 그래프읭 평균 edge의 수를 의미한다.
- 확장된 엣지의 비율이 높을수록 edge precision에 대해 더 큰 가중치를 부여한다.
Results