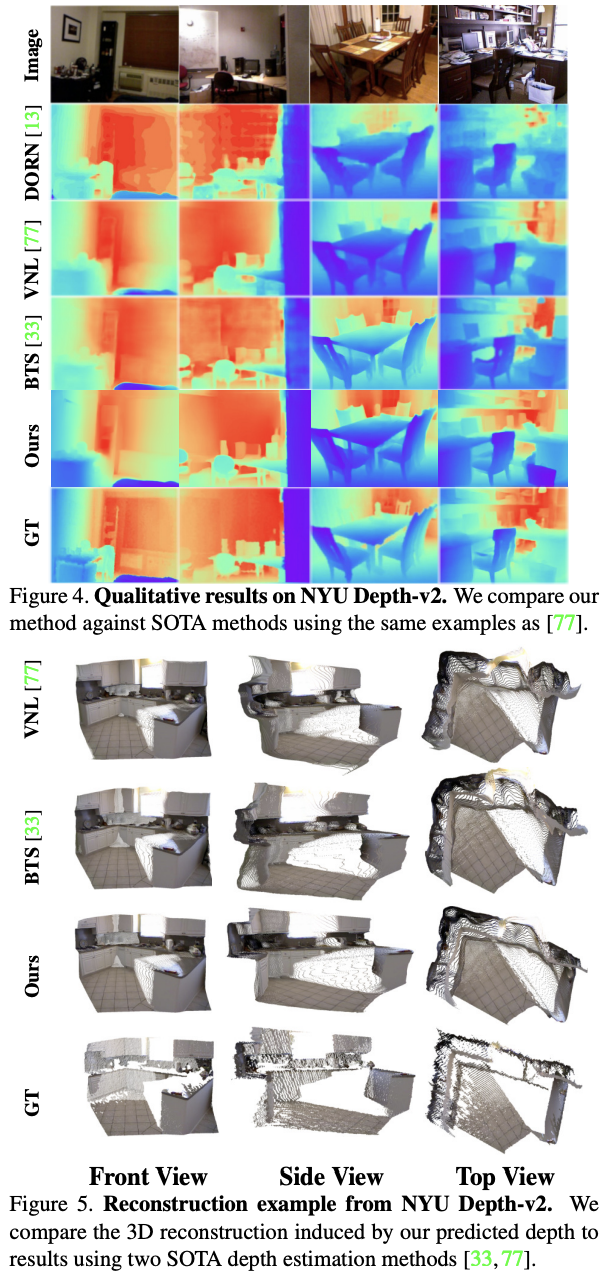
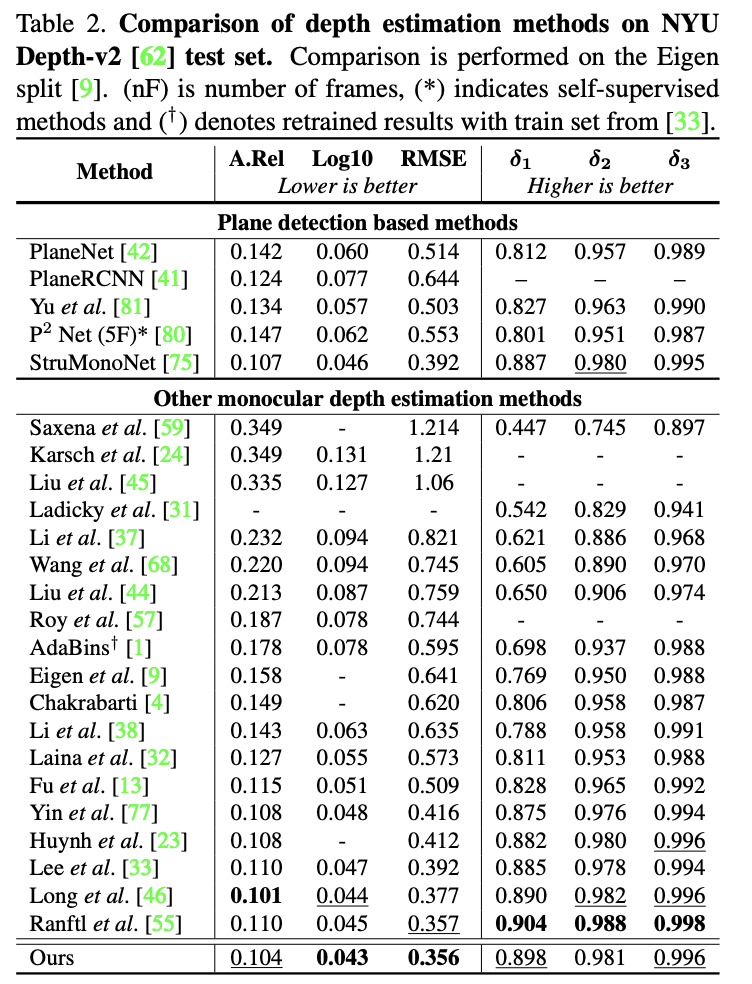
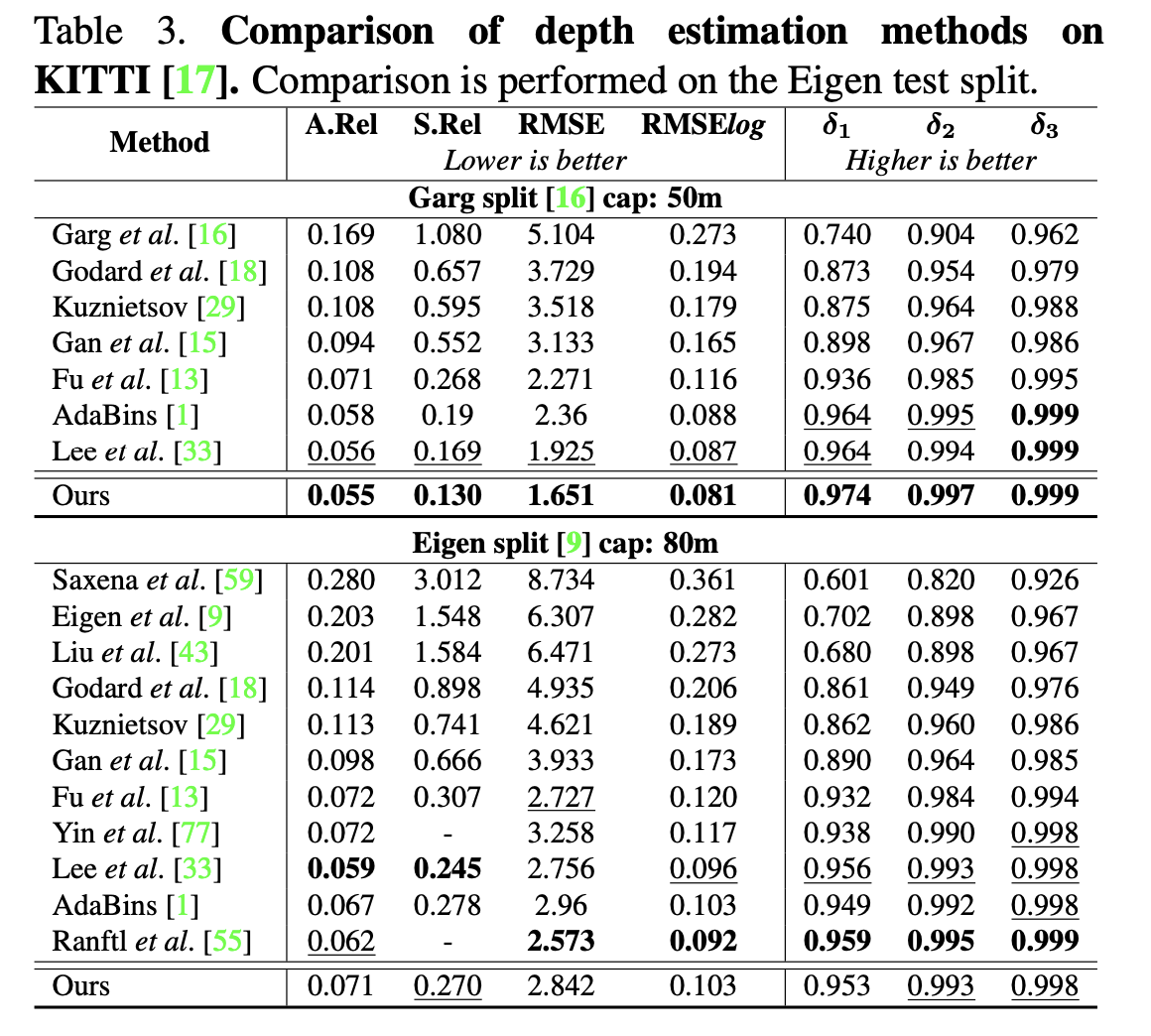
Introduction

- Monocular depth estiation에서 supervised 방식은 대부분 pixel-level loss를 활용하며 이는 실제 3D scene의 regularity를 반영하지 못한다.
- 3D scene의 geometric한 특성을 활용하기 위한 전형적인 방법으로 plane을 사전 정보로 사용할 수 있으며 "GeoLayout"에서는 이를 explicit하게 활용하였다.
- 본 논문에서는 planarity priors에 기반한 pixel들 간의 관계를 정의하기 위해 intermediate representation을 활용한다.
Method
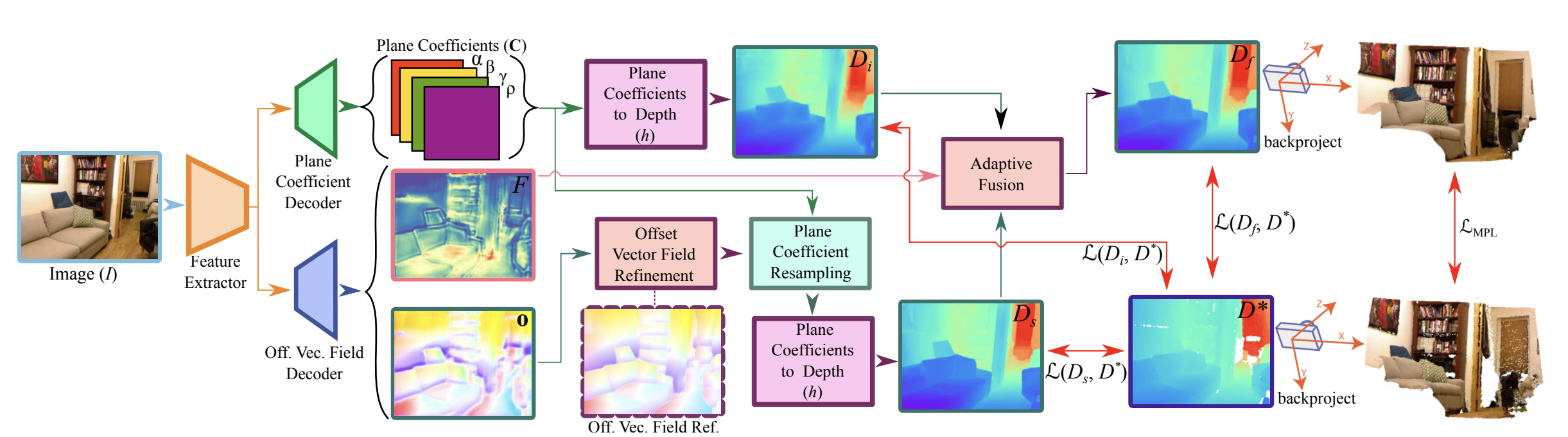
Plane Coefficient Representation for Depth
-
Camera intrinsics와 depth map 가 주어졌을 때 다음 식과 같이 각 픽셀 를 3D point 로 backprojection 할 수 있다.
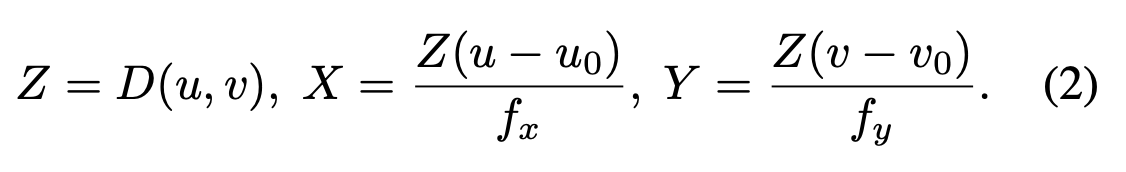
-
는 3D scene에서 어떤 plane에 해당하기 때문에 다음 식으로 표현할 수 있다.
, 은 normal vector -
식(2)로 를 치환하면 아래의 식을 얻을 수 있으며 계수 는 3D plane과 camera intrinsics 정보를 인코딩하고 있다.
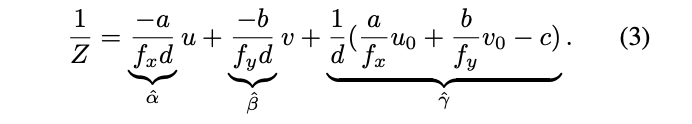
-
계수들을 정규화하여 표현하면 이며 는 다음과 같이 쓸 수 있다.
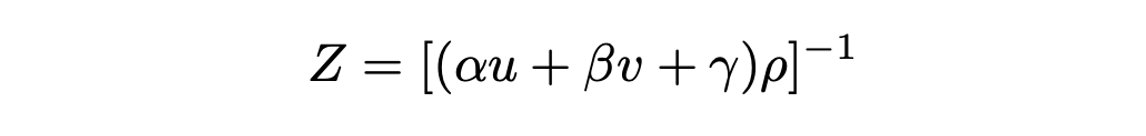
-
를 plane coefficient라고 칭하며 가 된다.
-
Dense plane coefficient 를 거쳐 예측한 initial depth map은 로 표기한다.
Learning to Identify Seed Pixels
- 동일한 plane 상에 있는 2개의 픽셀은 같은 를 가지지만 일반적으로 다른 depth를 가진다.
- 어떤 픽셀 에 대해 동일한 plane에 있는 다수의 픽셀들 를 seed pixel이라 정의한다.
- Prior가 유지 될 때 에 대한 depth는 를 확인하여 예측 가능하므로 offset 를 활용할 수 있다.
- Offset vector field 를 다른 decoder를 통해 만들며 plane coefficient를 재샘플링하기 위해 활용한다.
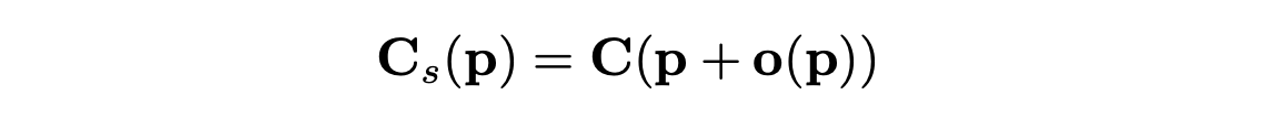
- 재샘플링 된 plane coefficient는 second depth prediction을 위해 사용된다.
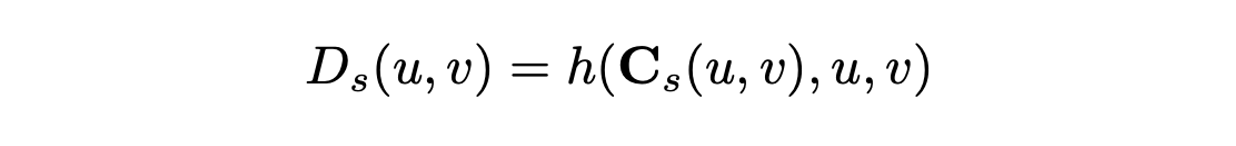
- 하지만, prior가 항상 valid 하지는 않아 initial depth prediction 가 seed-based prediction 에 비해 중요도가 높으므로 second head에서 confidence map 를 함께 뽑아 두 prediction을 adaptive하게 fusion 할 수 있도록 만든다.
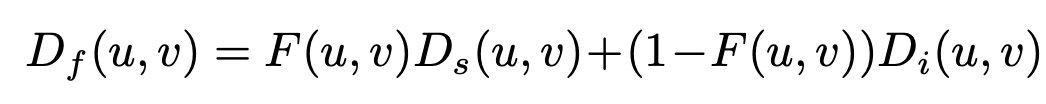
- 에 전부 supervision을 적용하여 optimize 한다.
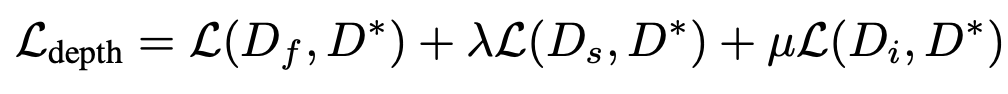
- 이러한 방식을 통해 plane coefficient head는 모든 픽셀에 대해 정확한 representation을 얻을 수 있으며, offset head는 planarity prior가 hold되는 픽셀들에 대해서는 높은 confidence를 그렇지 않은 픽셀들에 대해서는 낮은 confidence를 갖도록 만든다.
Mean Plane Loss
- Normal 은 overdetermined system으로 noise가 껴있는 groud-truth depth로는 optimal solution이 보장되지 않는다.
- 하지만 여전히 depth는 scene structure에 대한 comprehensive detail을 가지고 있으므로 local하게 aggregate 될 수 있다.
- 하나의 input patch에 대해 normal 은 를 만족한다. 는 patch 내의 3D point들을 쌓은 matrix, 는 그 중 하나의 벡터로 이는 closed form이다.
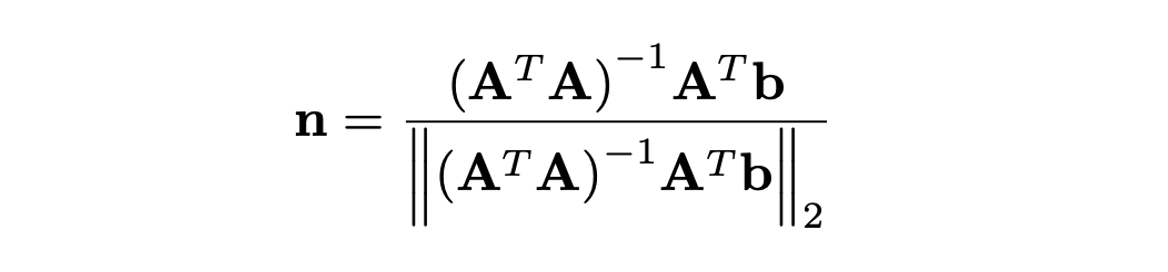
- Mean plane loss를 계산하기 위해 와 로부터 개의 모든 non-overlapping patches의 surface normal를 추정한 후 그 차이를 penalize 한다.
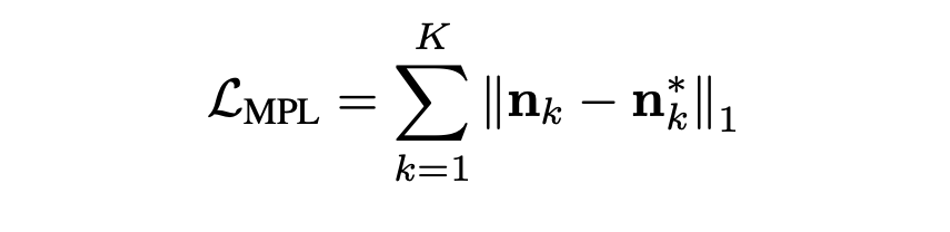
Experiments