Introduction
- 생성 모델의 유용성으로 text로부터 이미지를 생성하는 모델들이 나왔으나 sentence에 많은 object가 존재할 때는 생성에 어려움이 있었다.
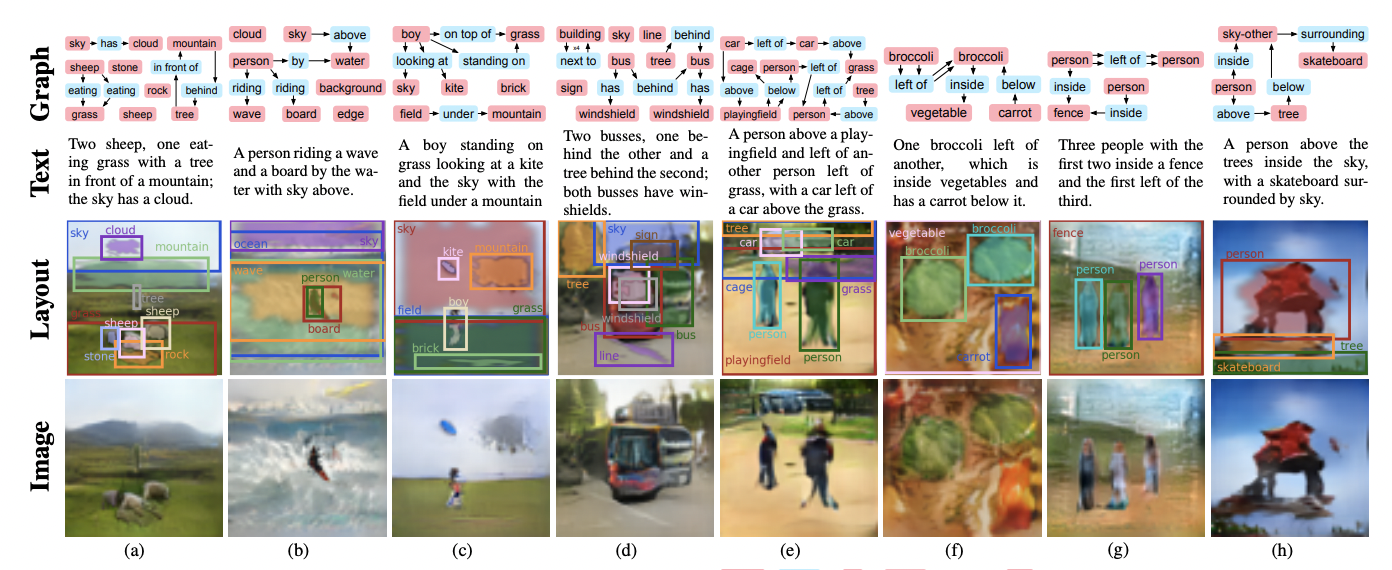
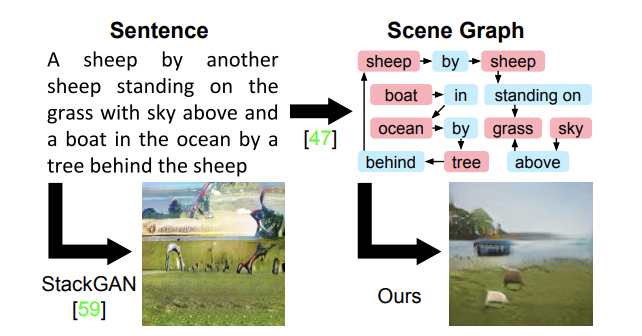
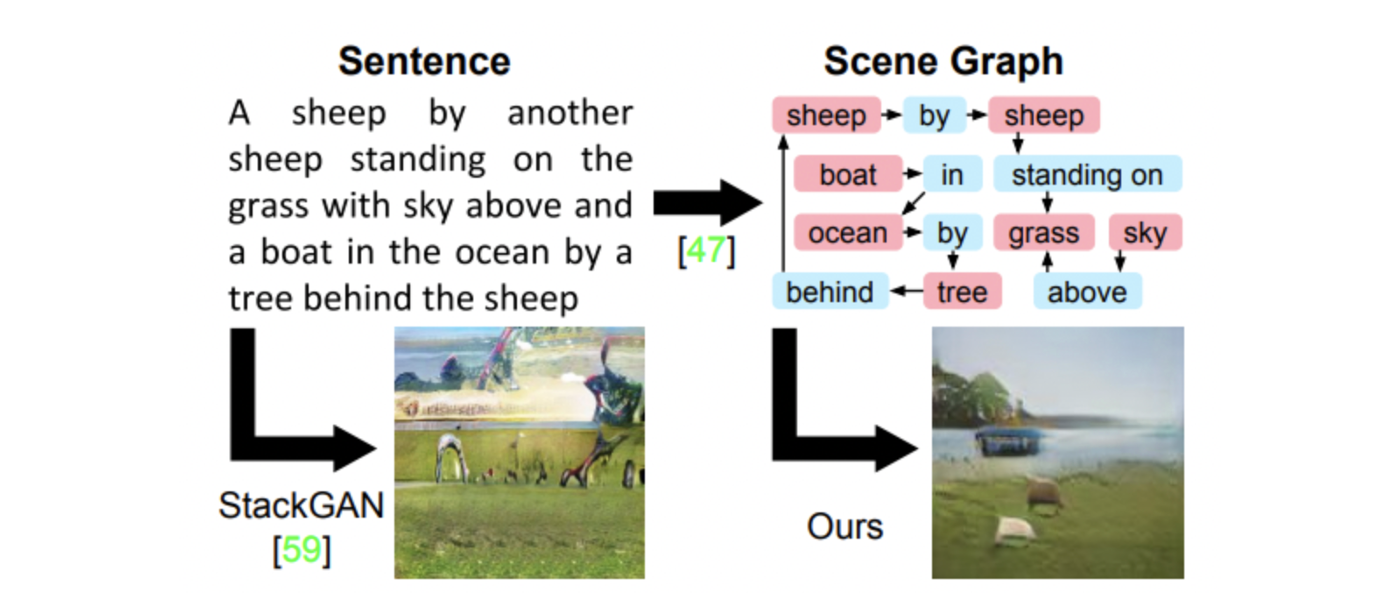
- 선형 구조의 sentence를 위 그림과 같이 objects와 relationships로 표현하는 scene grah로 나타낼 수 있다.
- Scene graph는 image와 language를 모두 표현할 수 있기 때문에 본 논문에서는 scene graph로부터 이미지 생성을 하는 네트워크를 제안한다.
Method
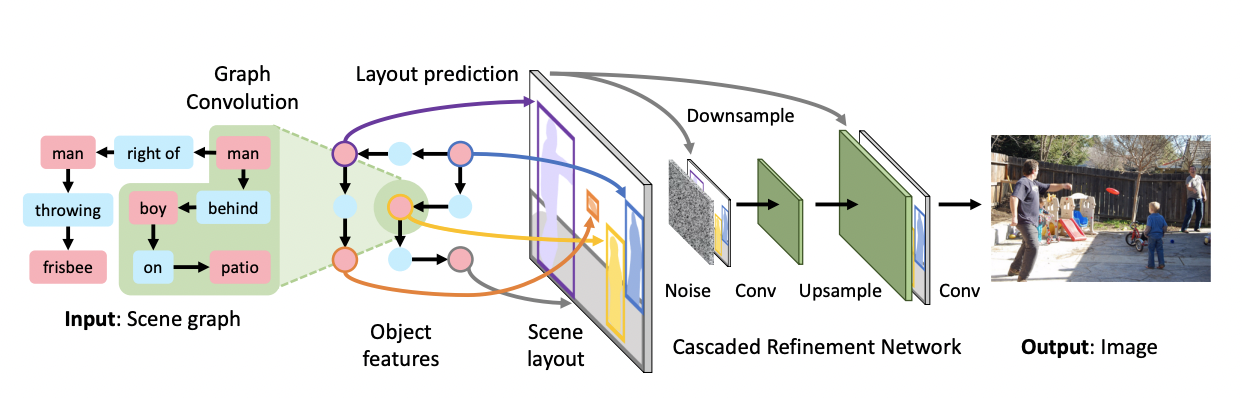
- 생성된 이미지는 그래프에서 명시된 objects와 relationships를 나타내야 하며 relistic 해야 한다.
- Graph Convolution Network(GCN)을 통해 scene graph를 만든 후 layout을 뽑고 이미지를 생성하는 과정을 거친다.
Scene Graph Generation
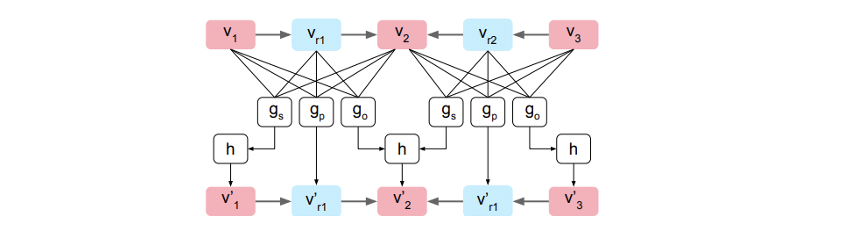
- 각 노드와 엣지로부터 dimension의 input vector를 받아 dimension의 새로운 vector를 계산한다.
- 각 graph convolution layer는 엣지를 따라 정보를 전달한다.
- 엣지에 대한 output vector 은 연결된 object들로부터 정보를 받는다.
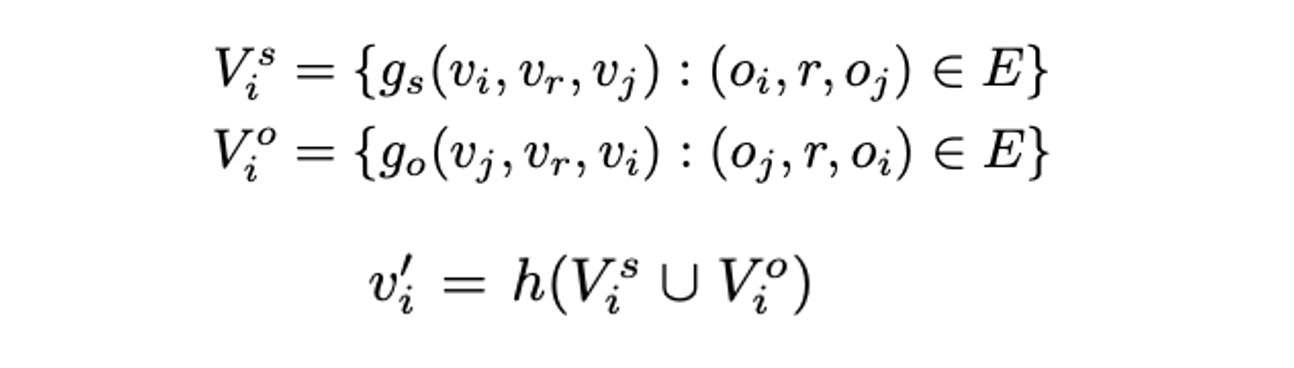
- Object 에 대한 output vector 는 엣지로 연결된 모든 object의 정보를 전달 받으며 로부터 시작하는 경우와 끝나는 경우를 각각 계산 한 후 합쳐준다.
- 는 4개의 input vectors를 concat 한 후 MLP를 통과하며 최종적으로 fc layer를 통과한 값이 output으로 나온다.
- 의 output은 pooling function으로 input vectors를 평균내어 MLP에 통과한 결과이다.
Scene layout
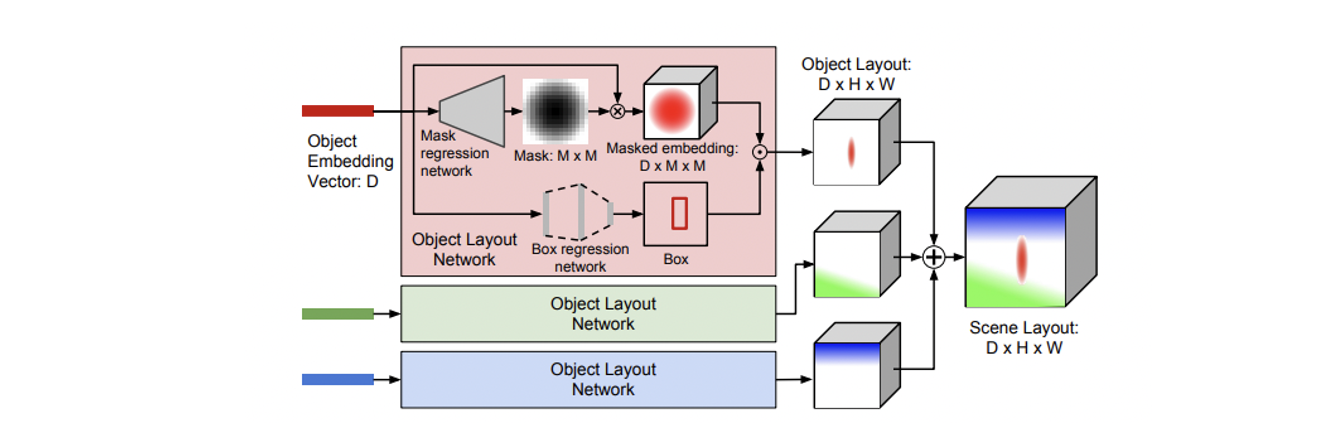
- 차원의 object embedding vector 를 사용하여 차원의 segmentation mask와 boudning box를 예측한다.
- Transposed convolution들로 이루어진 mask regression network를 통과 후 sigmoid를 거쳐 (0,1)의 값이 나오며 는 mask 과 elemenwise 연산되어 bounding box로 warping 된다.
- Training 시에는 scene layout을 계산하기 위해 GT bounding box 를 쓰며 test 시에는 예측된 bounding box 를 사용한다.
Cascaded Refinement Network
- Cascaded Refinement Network(CRN)은 resolution을 두 배로 만드는 연속된 convolutional refinement module들로 이루어진다.
- 각 module은 input으로 해당 module의 resolution으로 downsampling 된 scene layout과 이전 module의 output이 channelwise로 concat 되어 들어가며 coarse-to-fine 방식으로 학습된다.
- 첫번째 module의 input에는 가우시안 분포로부터 뽑은 noise 가 들어가며 마지막 module의 output은 2개의 convolution layer를 거쳐 최종 이미지를 만든다.
Loss
-
loss로 bounding box에 대한 오차를 측정한다.
-
Mask loss 는 pixelwise cross-entropy를 사용한다.
-
GT와의 픽셀별 difference도 측정한다.
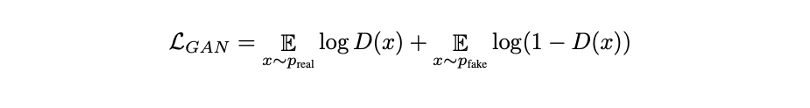
-
Image와 object가 실제와 유사하게 생성되었는지 확인하기 위해 와 도 활용한다.
-
Object discriminator 에는 object가 recognizable 한지를 보장하기 위해 category를 예측하는 auxiliary classifier를 활용해 또한 loss로 사용한다.
Experiments