Introduction
- Scene understanding은 AR/VR, robot navigation 등 여러 분야에 유용하지만 scanned 3D data는 incomplete하기 때문에 scene을 정확하게 이해하는데 어려움이 있다.
- 사람은 scene에 대해 이해할 때 visual perception 뿐만 아니라 흔히 지식 혹은 상식(knowledge)이라 부르는 class 간의 관계나 조합을 고려한다.
- Scene graph prediction에 있어 prior knowledge를 활용하는 방법에는 한계점이 존재한다.
- Static knowledge는 knowledge sources나 domain에 따라 불완전하거나 부정확할 수 있다.
- Visual information으로부터 학습하는 learning-based knowledge는 perceptual confusion이 knowledge embedding에 담긴다.
- 본 논문에서는 class-dependent하게 학습한 prior knowledge와 geometric feature를 활용해 scene graph prediction을 수행한다.
Method
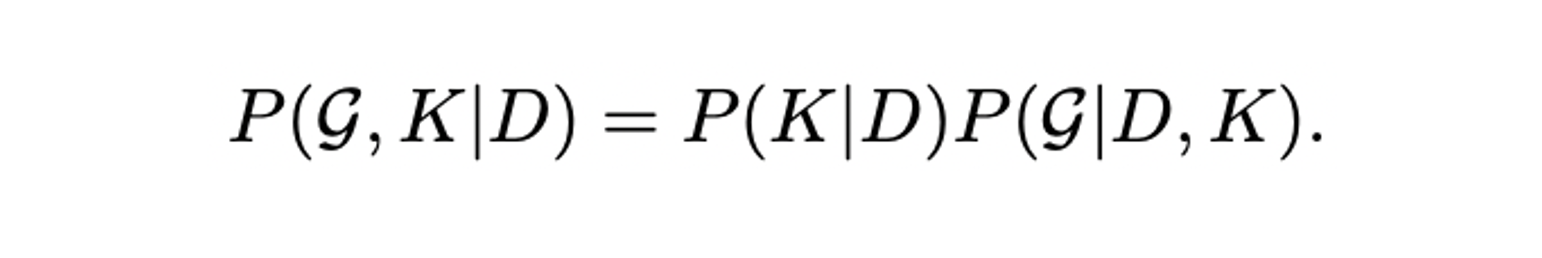
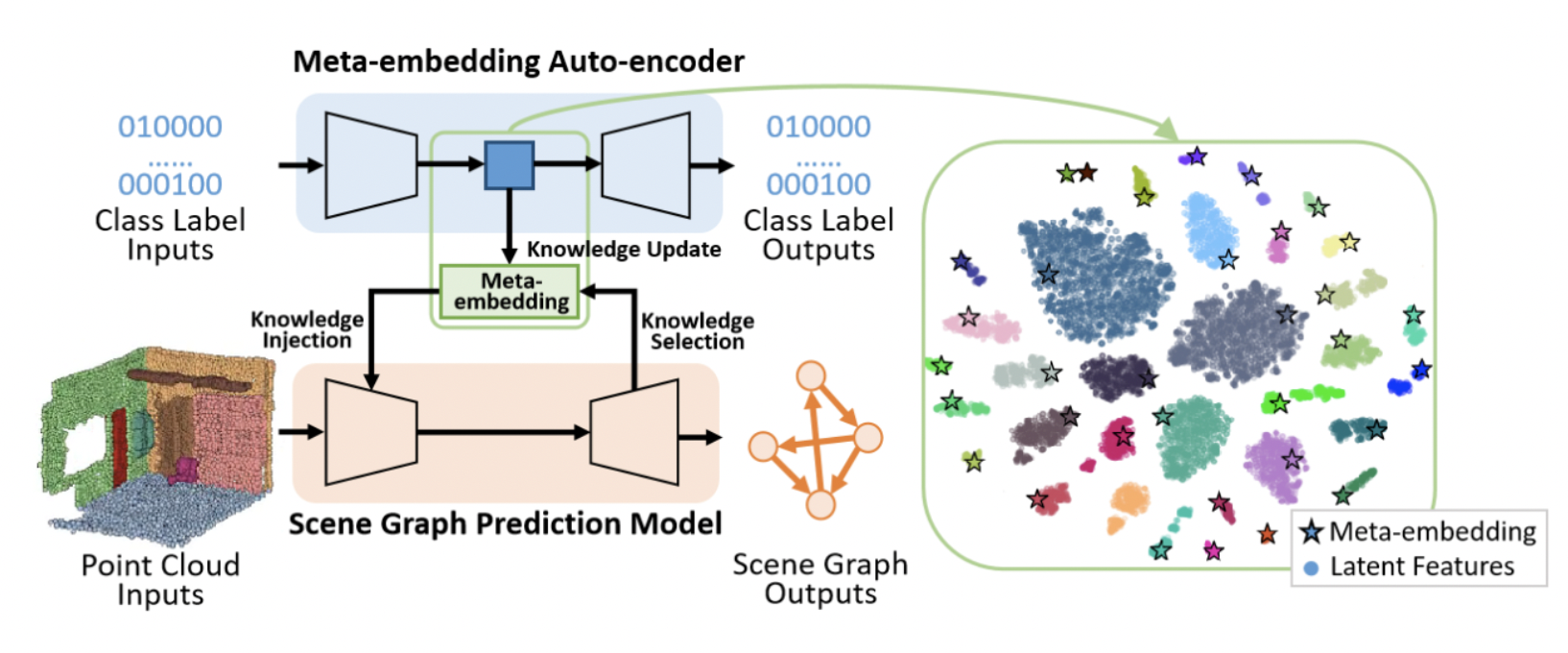
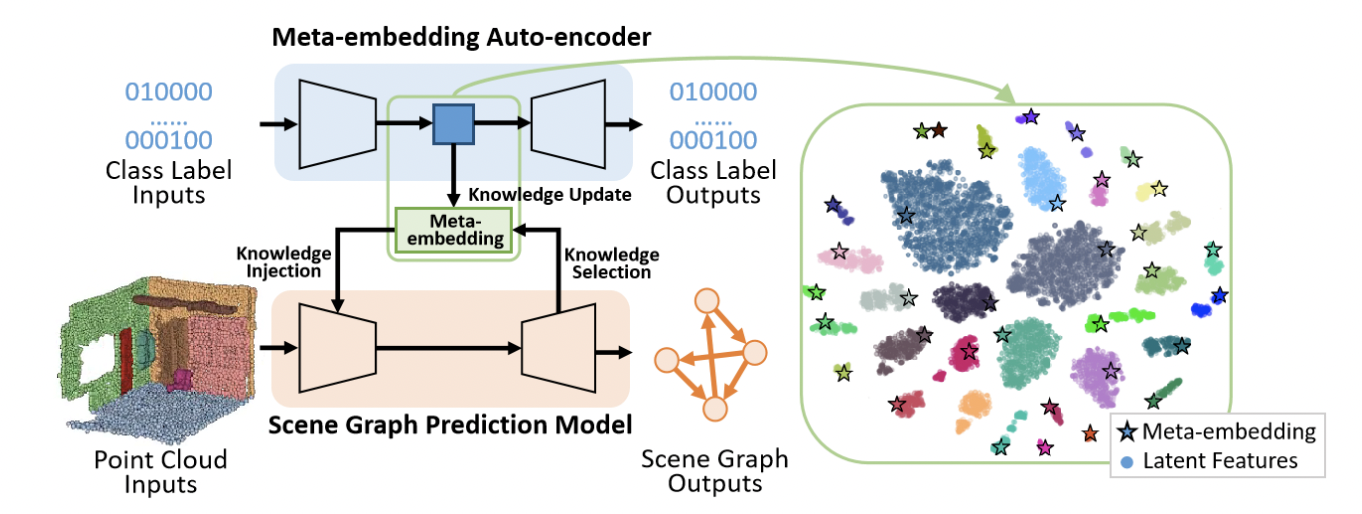
- Scene graph 에 대해 는 모든 object instances에 대한 노드 집합, 은 노드들을 연결하는 triplet 의 predicates 집합을 나타낸다.
- 는 prior knowledge, 는 3D scene data로 가 주어졌을 때 와 를 예측하는 task이지만 를 먼저 예측하고 와 를 통해 를 예측하는 두 개의 task로 볼 수 있다.
Meta embedding
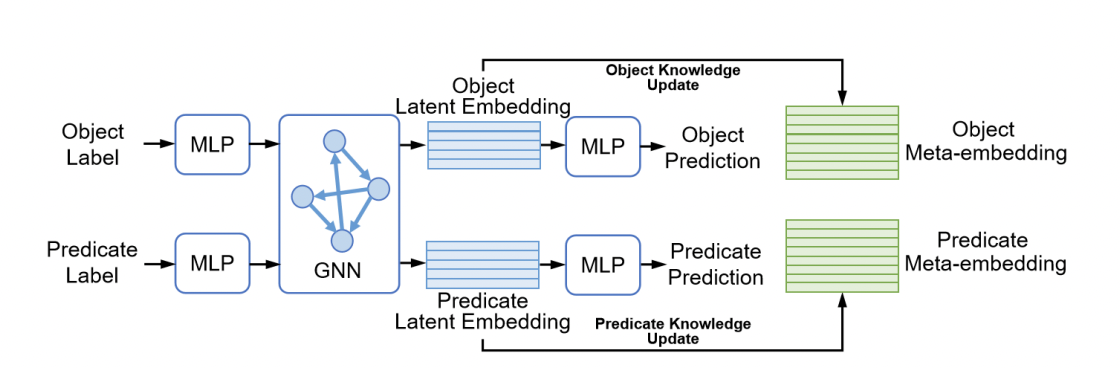
- Semantic meta embedding 는 semantic class와 class 간의 regular pattern을 담아야 한다.
- 이를 위해 graph auto-encoder netowrk를 사용하여 아무런 perceptual 정보 없이 one-hot label만 input으로 넣어준다.
- MLP를 통해 one-hot vector를 동일한 사이즈의 latent space로 보내주며 모든 obeject는 연결해주고 predicates는 엣지로 표현된다.(Including non relation)
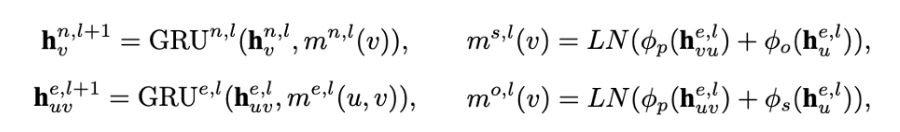
- 노드, 엣지에 대한 latent representation
- 노드, 엣지의 layer 에서의 message를 계산하기 위한 parameterized neural networks
- 노드는 subject와 object로 나뉜다.
- subject, predicate, object에 대한 non-linear transformation
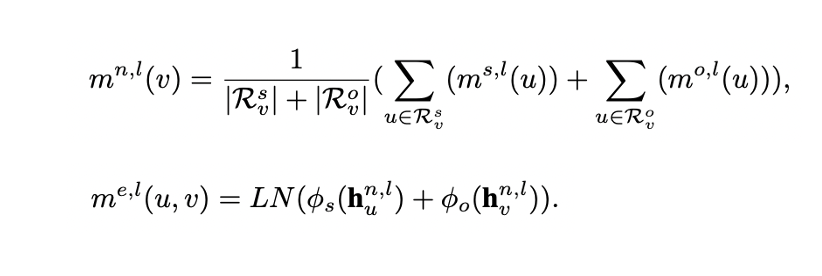
- 노드에 대한 최종 messages는 의 평균이며 엣지에 대한 최종 messages는 graph encoder의 output에 sum pooling 연산을 해주어 구한다.
- 은 각각 노드 에 subject와 object로 연결된 집합을 의미하며 은 cardinality이다.
- Metric space에서 corresponding meta-embedding vectors의 거리가 작아지도록 update 한다.
- 최종적으로 MLP를 거쳐 one-hot label을 예측하여 latent embedding이 class와 연관되도록 학습시킨다.
Knowledge-inspired Scene Graph Prediction Model
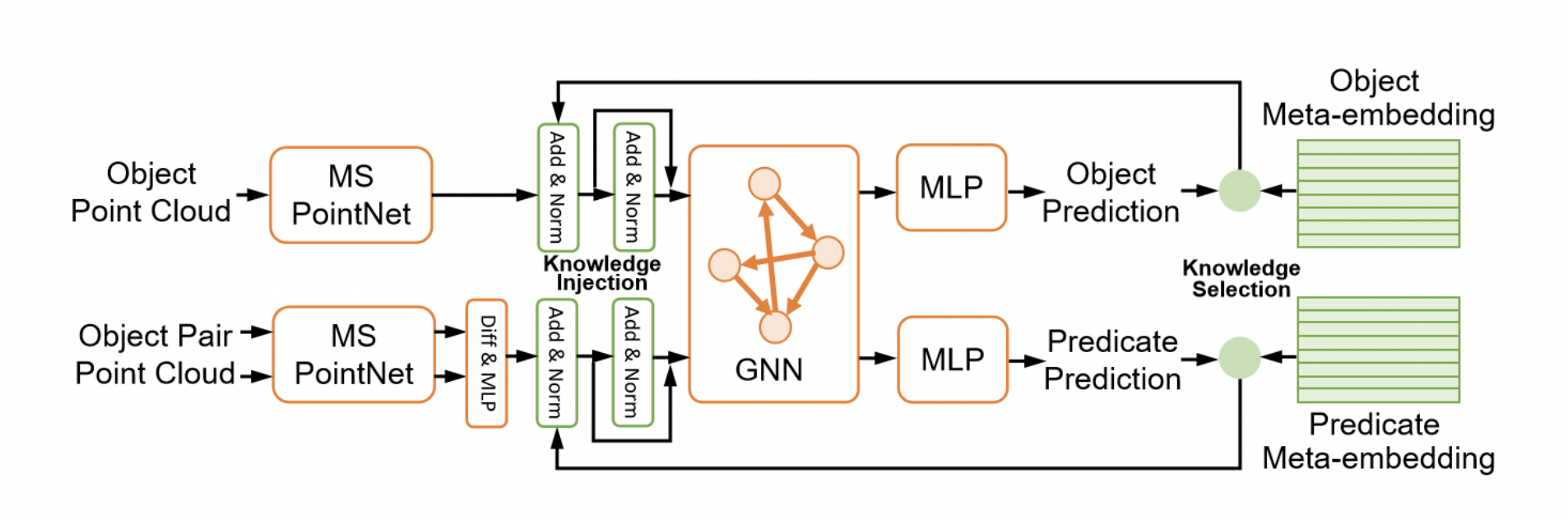
-
Instance 마스킹된 scene point cloud를 input으로 받아 objects와 object pairs의 gemetrical feature를 encoding하는 것이 목적이다.
-
Multi-scale geometric 정보를 잡아내기 위해 multi-scale PointNet(MS PointNet)을 통해 point set를 encoding 한다.
-
Object set와 subject set를 각각 encoding 한 후 latent feature와 center coordinate를 concat 하여 object-pair edges의 initial embedding을 얻는다.
(left and right와 같은 contradictory 관계를 잘 encoding 하기 위해 features 간에는 subtraction을 활용한다.) -
Perceptual information과 함께 global context를 잡아내기 위해 meta-embedding 과정에서 쓰였던 GNN을 동일하게 사용한다.
-
첫번째 iteration에서는 PoinNet의 geometric feature만을 input으로 받아 GNN과 MLP를 거쳐 노드와 엣지에 대한 class를 예측한다.
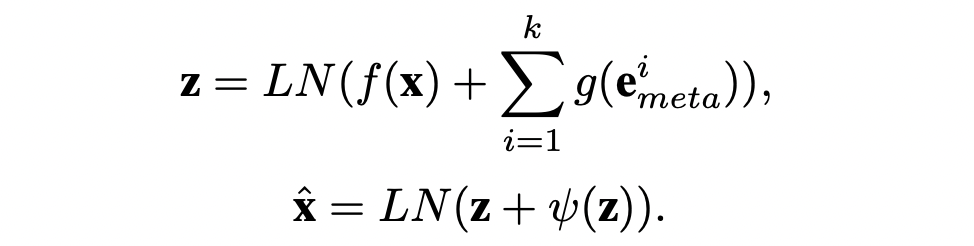
-
두번째 iteration에서는 각 노드 및 엣지에 상위 5개의 meta-embedding과 perceptual embedding을 fusion 하여 input으로 사용한다.
-
Feature vector 와 meta embedding vectors 는 서로 다른 latent space에 있으므로 two-layer feed forward networks 와 를 통해 transform 한 후 합쳐준다.
-
는 two-layer MLP이다.
Loss function
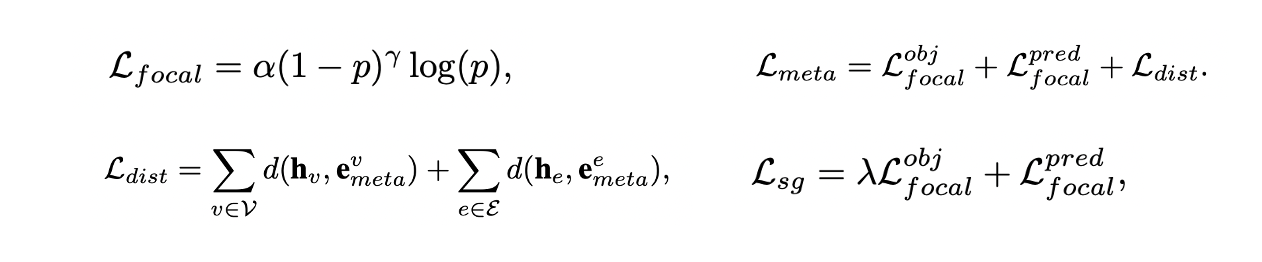
- 데이터 불균형이 있으므로 meta-embedding learning과 scene graph prediction에서 모두 focal loss를 사용한다.
- Graph encoder의 output 와 corresponding meta-embedding 가 가까워지도록 euclidean distance 를 활용한다.
- meta learning task에서는 object와 predicate에 대한 focal loss와 meta-embedding distance를 통해 학습한다.
- Scene graph prediction task에서는 object와 predicate에 대한 focal loss만 활용하여 학습한다.
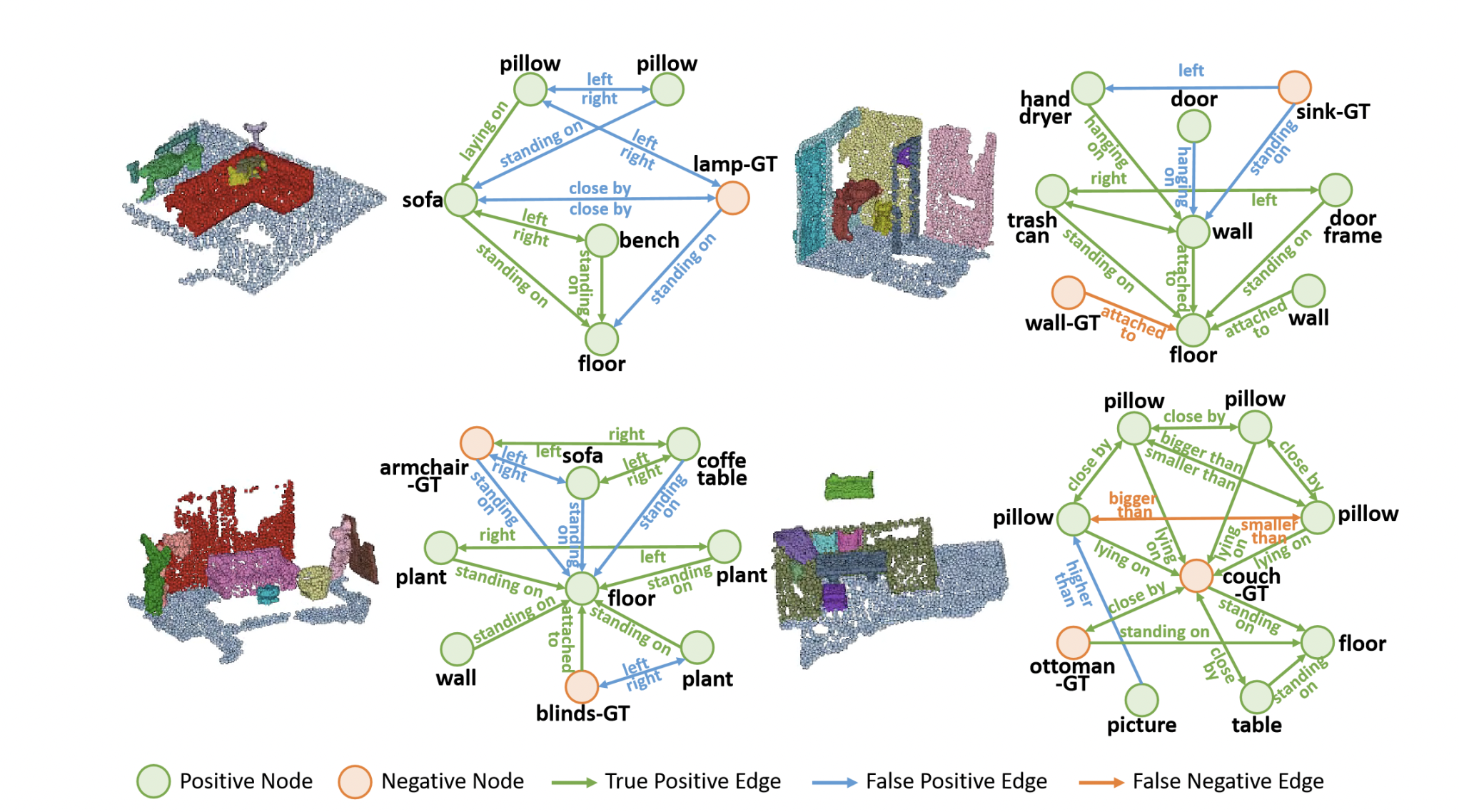
Result