[논문 리뷰] Scene Graph Expansion for Semantics-Guided Image Outpainting
Notation
- Scene graph S=(O,R)은 N개의 objects O={oi}i=1:N과 relationship matrix R=(rij)∈RN×N으로 구성
- oi는 object label, rij는 object i와 j의 edge label
- rij는 {y1R,y2R,...,yMR}∪{0}, yiR은 relation label, M은 relation label의 수
- Layout은 object의 bounding boxes의 리스트로 B={bi}i=1:N로 표현한다.
bi=(bix,biy,biw,bih)
- D=(dij)∈RN×N×4는 relationship의 bounding box disparity를 의미한다.
dij={bix−bjx,biy−bjy,log(biw/bjw),log(bih)/log(bjh)}
Overview
- 기존의 Transformer는 다음과 같다.
- Input sequence H={hi}i=1:3N2로부터 output sequence H^={hi}i=1:3N2로 mapping하는 multiple transformation layers로 구성된다.
- N개의 node와 N2개의 edges가 input graph에 존재하며 (subject-predicate-object) 형태이므로 길이가 3N2이 된다.
- 각 transformer layer에서 input vector h는 query, key, value vector(q,k,v)로 변환되며 output vector는 h^i=∑jsijvj가 된다. sij=softmax(qi⋅kj/dk), dk는 k의 차원 수.
- 본 논문의 SGT에서는 scene graph를 triplets의 single sequence로 보는 대신 node와 edge를 구분되지만 상호 연관되는 data modality로 본다.
- 즉, edges는 nodes 간의 self-attention 중 regularization 역할을 하며, nodes의 co-occurence가 edges 간의 self-attention을 guide하게 만든다.
- 따라서, input과 output이 Hn={hin}i=1:N,Hn^={h^in}i,j=1:N,He={hije}i,j=1:N,He^={h^ijn}i=1:N로 구분되며 각 modaltiy에 서로 다른 attention mechanism을 적용한다.
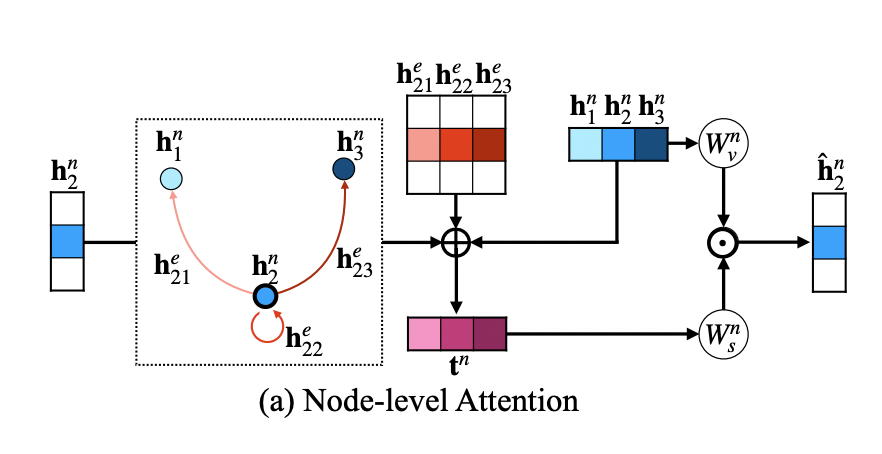
Node-level attention
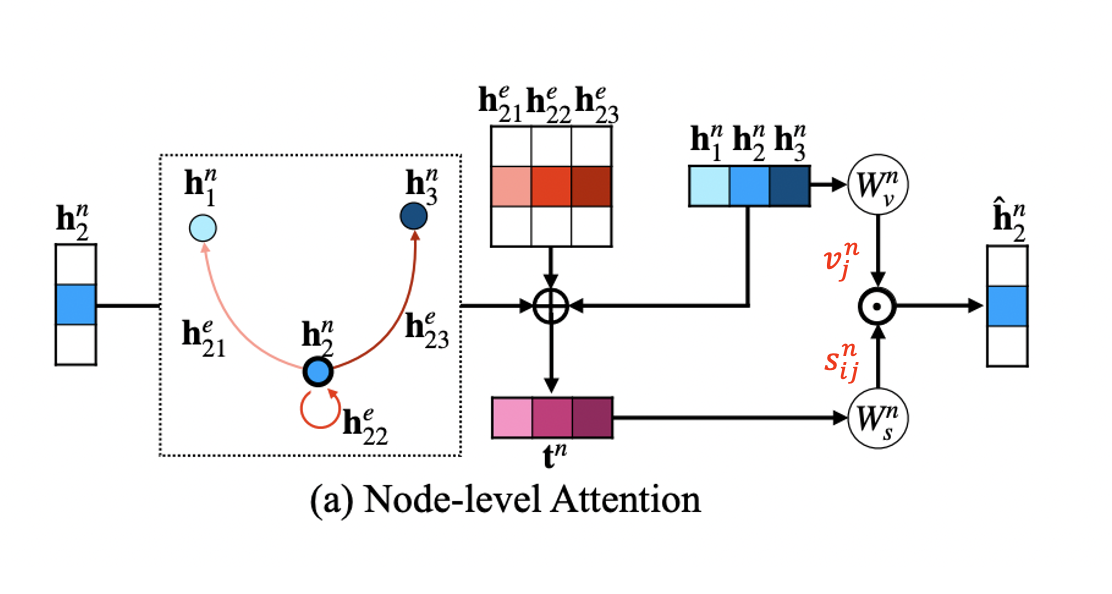
- Node-level attention에서는 edge feature hije의 guidance 하에 node features hin과 hjn 사이의 similarity를 계산한다.
- 기존 transformer의 key, query를 inner-product 한 후 softmax를 취하는 방식을 사용하지 않는데 edge-regularized attention이 구조적인 정보를 제공하며 inner-product는 이러한 정보를 손실시키기 때문이다.
- Output인 h^in은 각 node j들의 value와 attention weight의 element-wise multiplication의 합으로 계산한다.
h^in=∑jsijn⊙vjn
- Value vector vj는 hjn이 single MLP Wvn을 거쳐 형성되며, attention weight sijn은 tijn을 또 다른 MLP Wsn에 통과시켜 얻는다.
- tijn은 (nodei,edgeij,nodej) triplet의 representation이다.
tijn=hin⊕hjn⊕hije
Edge-level attention
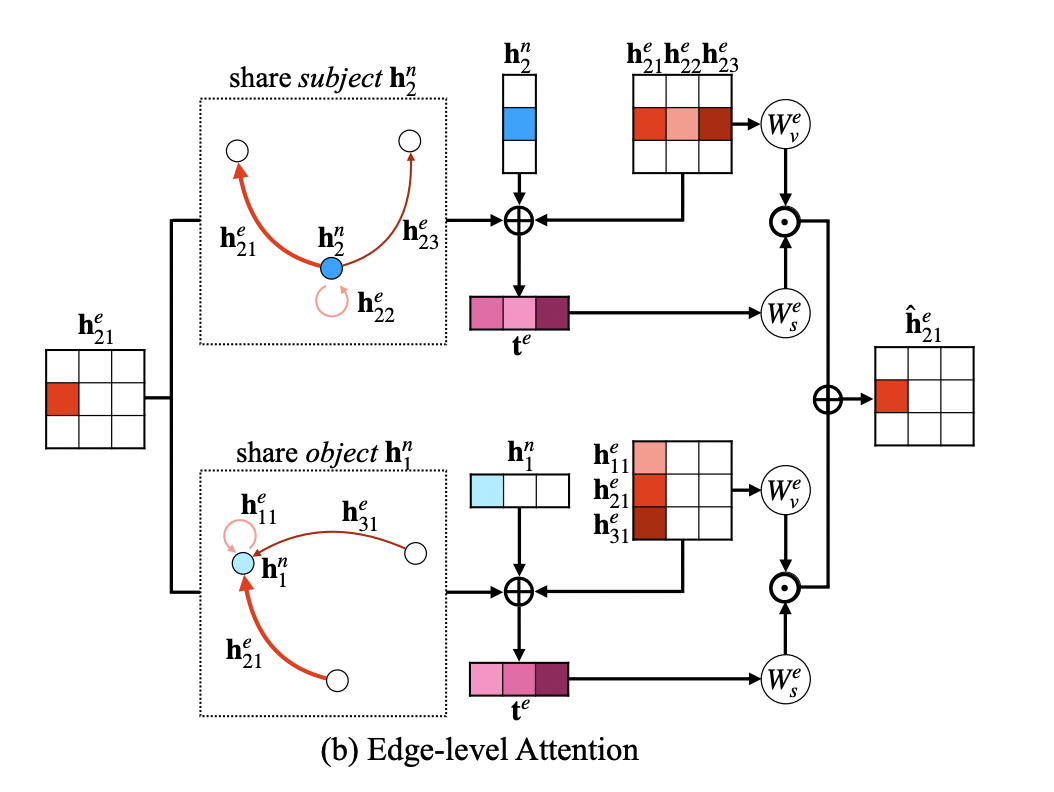
- tijn=hin⊕hjn⊕hije에서는 유사한 노드 사이의 엣지는 동일한 h^ije를 가지게 되어 노드가 반복되고 불필요한 엣지들을 가지는 문제가 발생할 수 있다.
- 따라서, 노드 i,j와 연결된 엣지들까지 고려한다.
{hkle∣k=i∨l=j},tij,kle=hije⊕hkle⊕{hin, if k=ihjn, if l=j
- 이를 통해 기존의 edge-level attention matrix N2×N2에서 N2(edge number) ×2N(N subjects + N objects)=2N3개만이 edge로 고려되어 연산량이 감소한다.
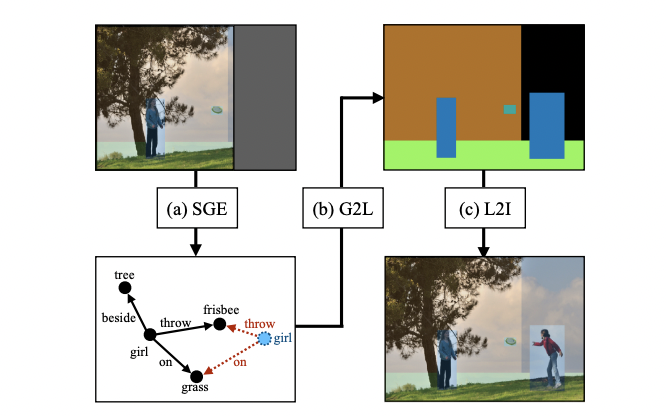
Semantic-Guided Image Outpainting
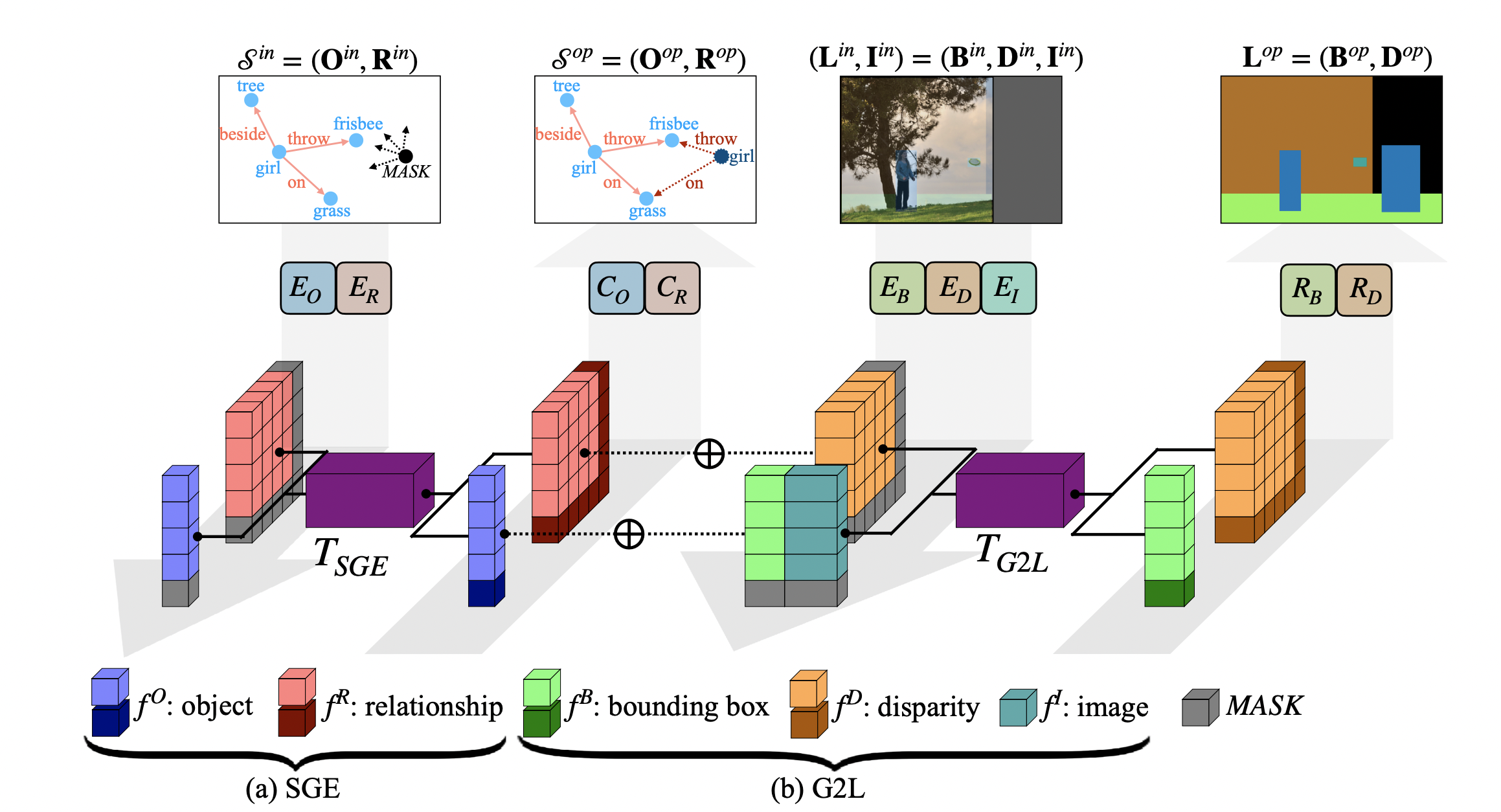
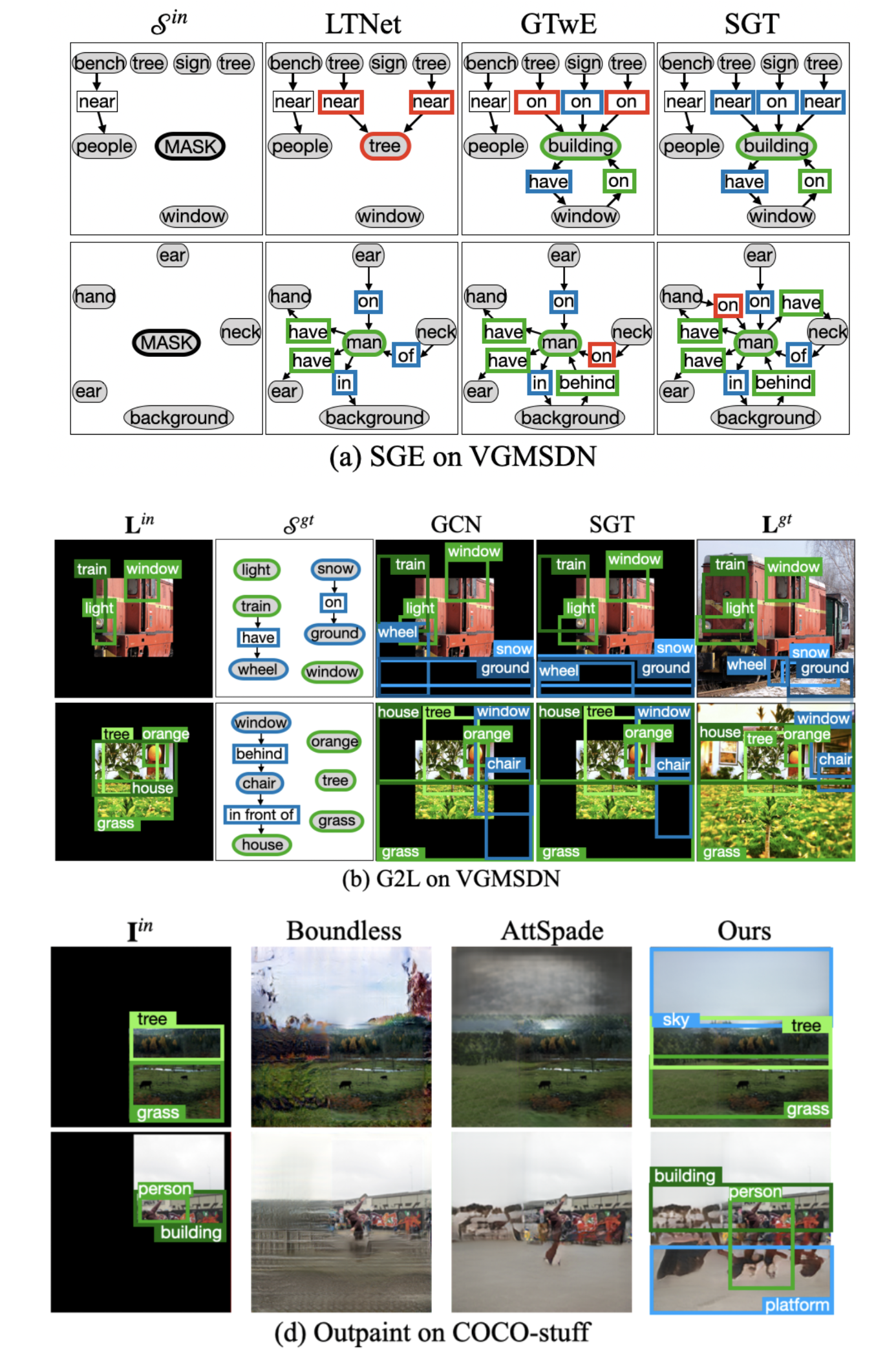
Scene Graph Expansion
Converse relationship
- R=(rij)∈RN×N은 rij=yR과 rji=y~R가 반의어 관계를 가지므로 skew symmetric 형태를 가진다.
- Scene graph에서는 명시된 relation이 한정적이므로 이러한 관계를 활용하여 converse label y~R을 부여한다.
- Converse relation으로 1대1 맵핑을 하기 위해 feature converter EC를 활용하며 아래와 같은 loss를 통해 학습한다.
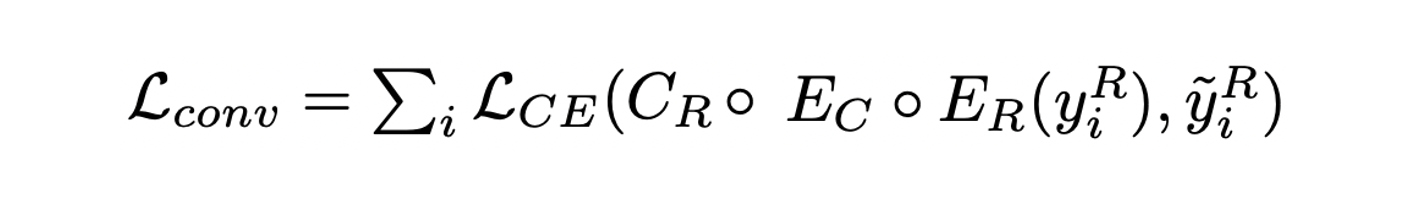
SGE Training
- SGT를 활용한 Scene Graph Expansion 모델을 TSGE라고 칭한다.
- Masked language model인 BERT을 활용하며 학습 시 complete scene graph에서 일부 object 및 연결된 relationship들을 마스킹한다.
- Node/edge-level attention을 활용하기 위한 encoder인 EO,ER와 분류를 위한 CO,CR이 있다.
- Object와 relation에 대한 예측과 GT의 cross entropy를 통해 학습하며 converse relation도 함께 활용한다.
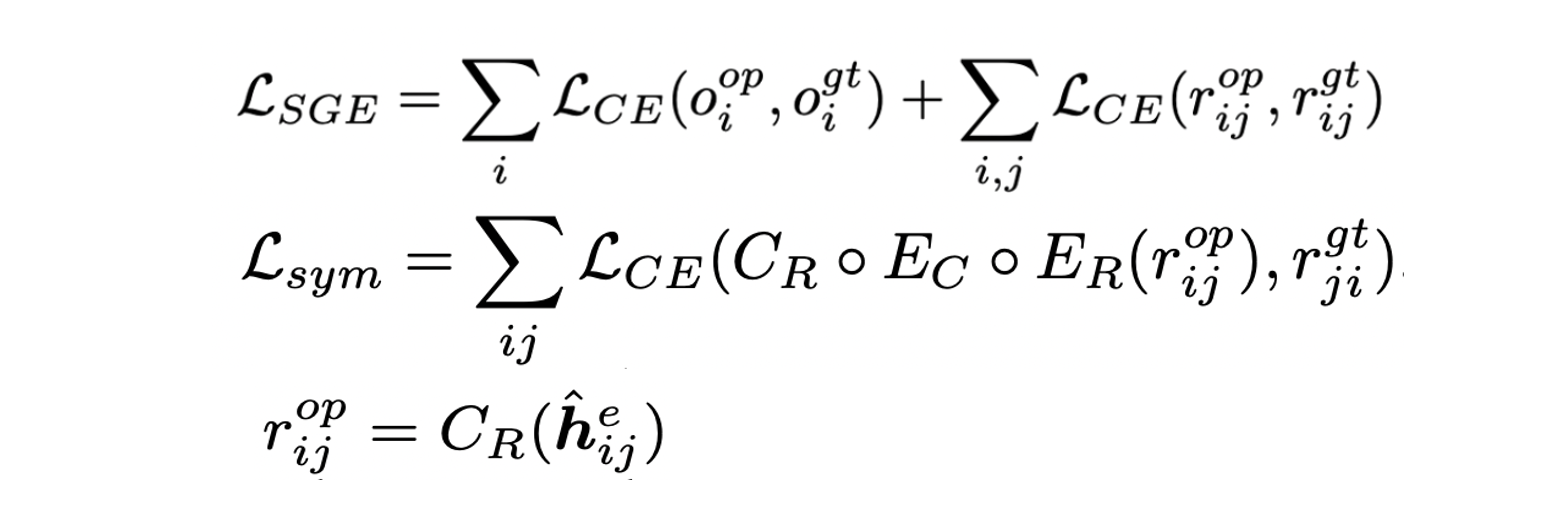
Scene Graph to Layout(G2L)
- Partial image Iin, layout Lin, expanded scene graph Sop가 주어졌을 때 Lop를 생성한다.
- Bounding box의 encoder 및 regressor EB,RB와 disparity의 encoder 및 regressor ED,RD, image encoder EI가 활용된다.
- EI는 object가 mask 영역에 의해 잘린 부분이 있는지를 구분하여 incomplete bounding box를 확장할 수 있도록 돕는다.
- SGT를 활용해 TG2L은 (Hn,He)로 구성된 그래프로 표현된다.
- hin은 object category embedding fiO=EO(oi), bounding box feature fiB=EB(bi), visual feature fiI를 concat 하여 표현한다.
- hije는 relationship category embedding fijR=ER(rij), disparity feature fijD=ED(dij)를 concat하여 표현한다.
- Masked object는 bigt에 의해 bounding boxes biop를 예측하도록 학습하며 RD는 node와 edge의 output이 consistency를 유지하도록 dijgt에 의해 학습한다.
- LcIOU는 "Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression"를 참고
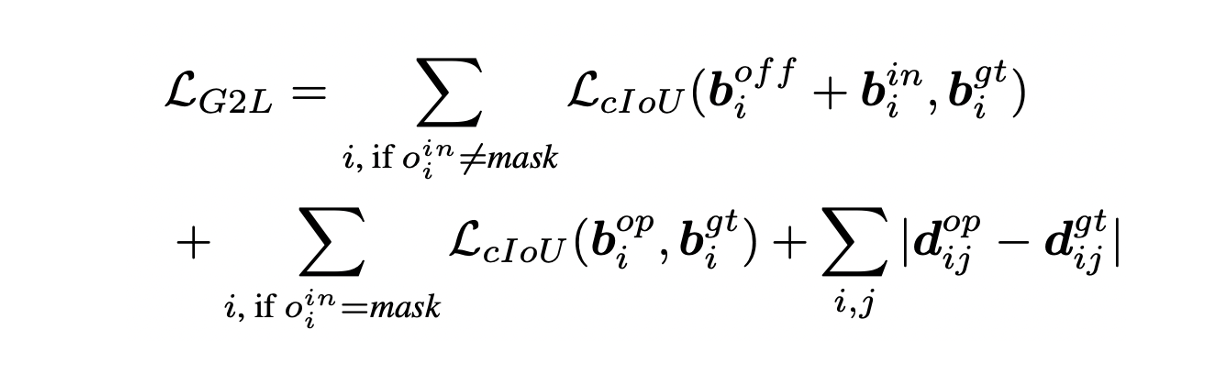
Layout to Image(L2I)
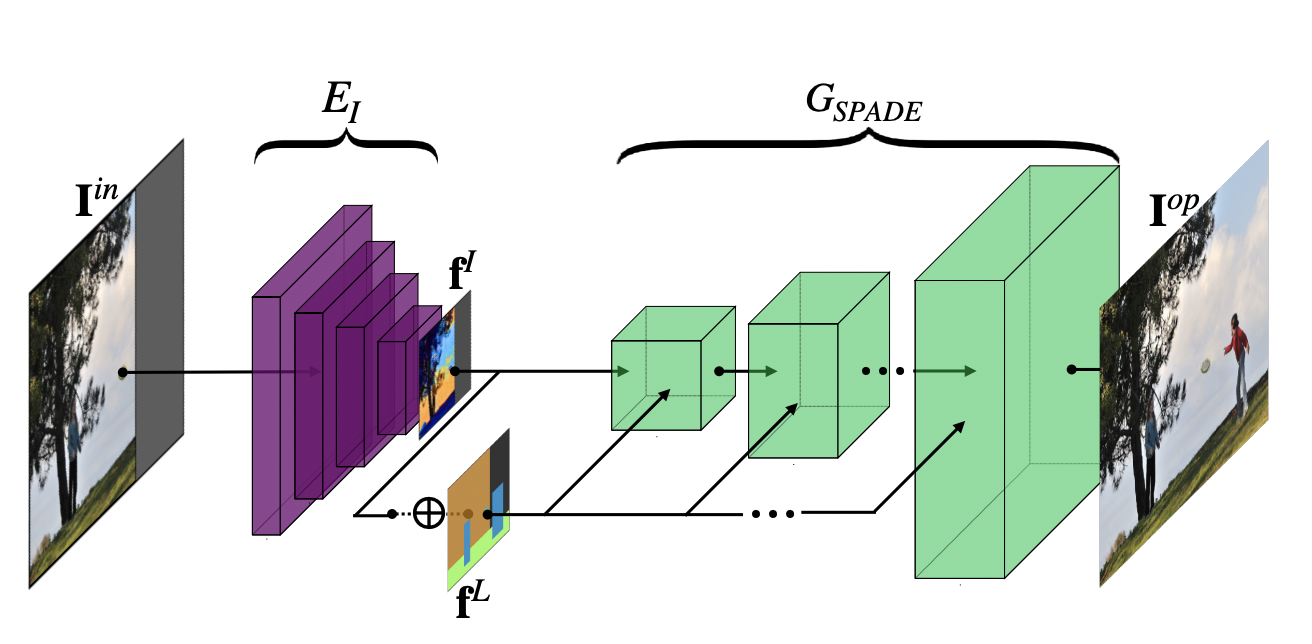
- GL2I는 Sop와 Lop가 주어졌을 때 AttSpade를 활용해 partial input image를 outpainting 한 Iop를 생성한다.
- Consistency를 위해 image feature fI와 layout feature map fL을 concat해서 활용하며 SPADE의 adversarial loss와 더불어 Iop와 Igt 간의 reconstrunction loss를 추가한다.
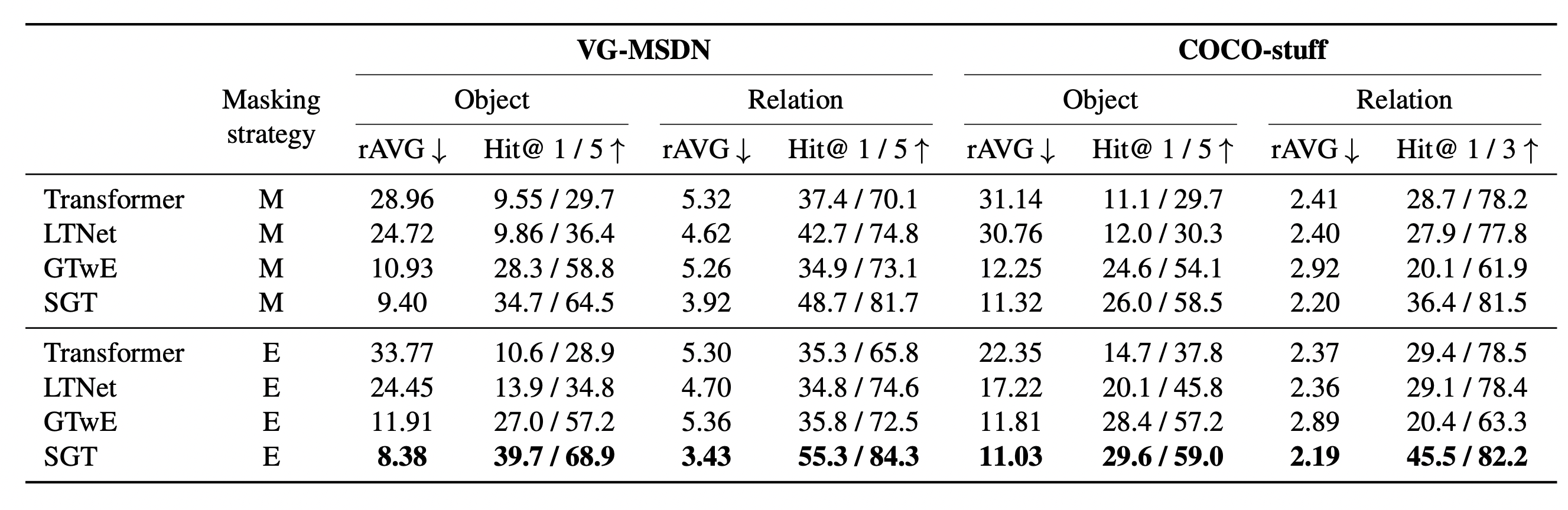
Experiments
Reference
