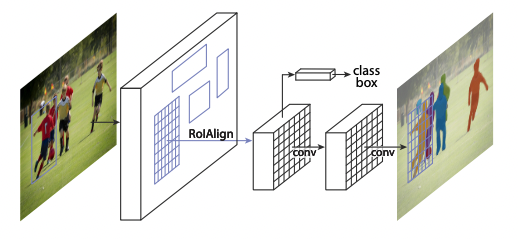
Introduction
- 그동안 Object detection, Semantic segmentation에서는 큰 성과가 있었으나 Instance segmentation은 모든 객체들에 대한 정확한 detection과 segmentation이 이루어져야 하기에 어려움이 있었다.
- 따라서 복잡한 과정이 필요해보이나 본 논문에서는 Faster R-CNN에 small FCN으로 구성된 mask branch를 추가하여 단순하고 빠른 아키텍쳐를 구성하였다.
- Faster R-CNN은 픽셀 단위의 segmentation을 위해 설계되지 않아 RoI Pooling을 RoIAlign로 대체 하여 공간정보를 보존할 수 있도록 한다.
- 그 결과, object detection, instance segmentation, human pose estimation에서 전부 좋은 성능을 보였다.
Mask R-CNN
Faster R-CNN은 class label과 bounding box 좌표라는 두 가지의 output을 낸다. 이에 mask branch를 추가한다는 것은 단순한 아이디어이지만 픽셀 단위의 예측을 더욱 세밀한 공간 정보가 필요하기에 기존의 branch들과는 다른 정보가 필요하다.
Faster R-CNN
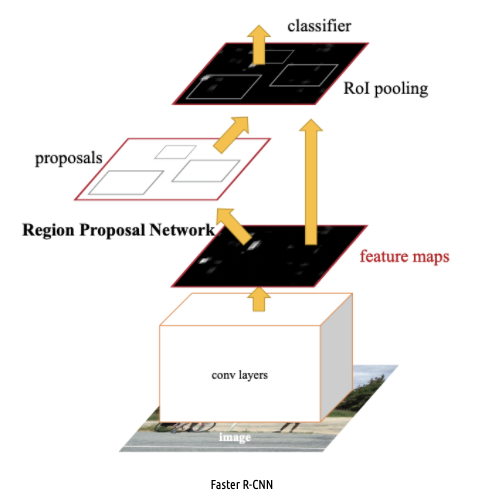
Faster R-CNN은 2-stage로 이루어진다.
- 후보 bounding box들을 제안하는 Region Proposal Network(RPN)
- bounding box들로부터 feature map을 뽑아 classification과 box regression을 수행하도록 하는 RoI pooling
Mask R-CNN
- Multi-task loss
- 와 는 Faster R-CNN과 동일한 Loss를 사용하며, 3가지의 각 Loss들은 전부 독립적이다.
- 는 차원이며 average binary cross-entropy loss를 사용한다. 객체가 속한 class에 대한 loss만 구하므로 binary 연산을 하게된다.
(:class의 수, :이미지 해상도) - 기존의 FCN과 같은 모델들의 경우 픽셀 단위로 전부 class와 mask를 예측하여 연산량이 많았던 것과 달리 Mask R-CNN은 독립적으로 수행하여 효율적이다.
Mask Representation
- mask는 객체의 공간 정보를 담고 있어 FC layer를 거치는 classification, box regression에서의 정보는 사용할 수 없다.
- 따라서, FC layer 대신 컨볼루션을 활용하여 공간 정보를 유지한다.
RoIAlign
RoI pooling이란?
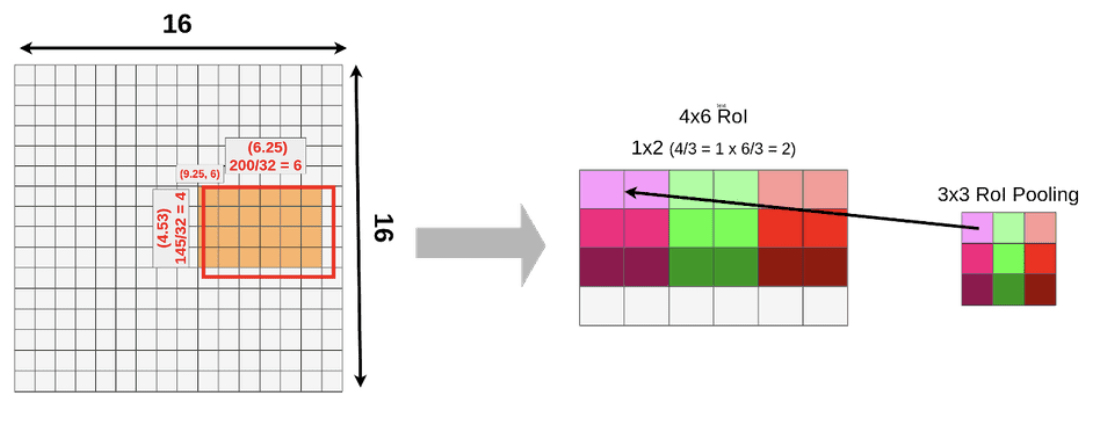
위 그림은 좌측은 RPN을 통해 얻은 RoI를 backbone network에서 추출한 feature map에 투영시키는 모습이다. Input이 512x512, feature map이 16x16, RoI가 145x200일 때 비율에 맞춰 32로 나눠주면 소수점이 나오며 픽셀 미만의 크기로 분할하는 것은 불가능하므로 반올림 하여 4x6 크기의 feature map을 얻는다. 이와 같이 실수값을 정수로 제한하는 방식을 quantization이라고 말한다.
우측은 RoI pooling을 수행하는 과정이다. RoI pooling은 입력값의 크기와 무관하게 같은 크기의 feature map을 얻을 수 있다는 장점이 있지만 위의 예시와 같이 정보가 손실될 수 있다는 단점이 있다.
Object detection에서는 미세한 소수점의 차이가 크게 중요하지 않으므로 위와 같은 방식을 사용하였지만 segmentation에서는 픽셀 단위의 계산을 하기 때문에 위와 같은 misalignment가 큰 악영향을 미친다. 따라서 본 논문에서는 RoIAlign 방법을 적용한다.
RoIAlign 과정
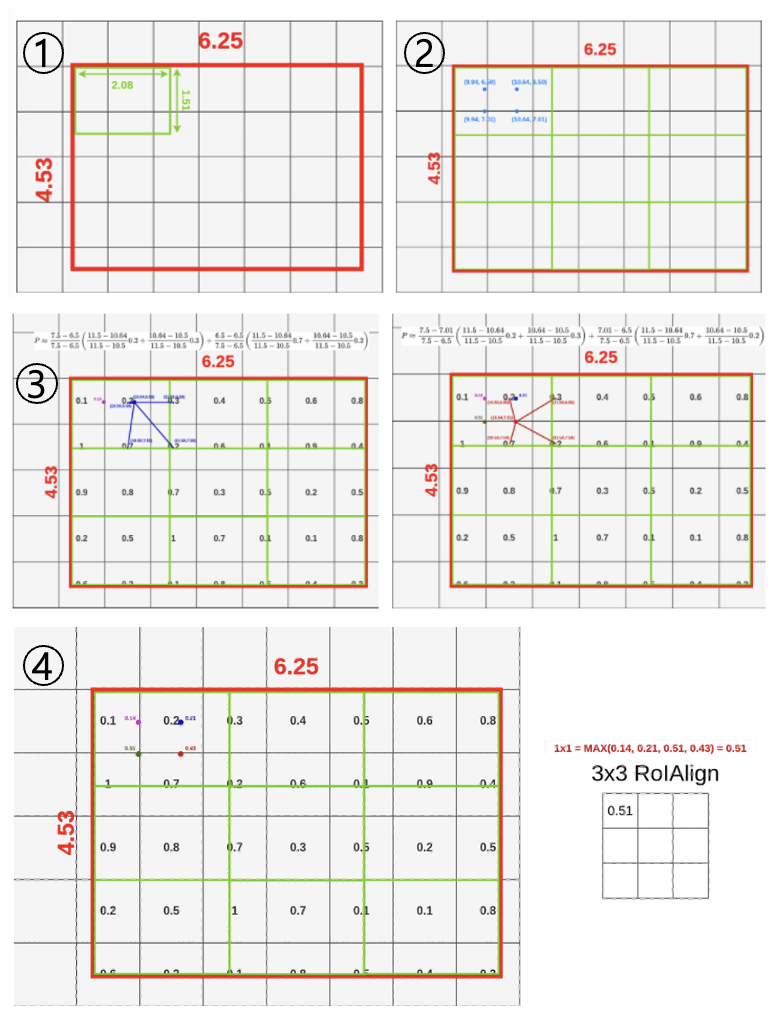
- RoI projection을 통해 얻은 feature map을 quantization 없이 그대로 사용. 위 예시에서는 3x3 feature map을 출력한다고 가정하고 wideth, height를 각각 3등분하여 9개의 셀을 만들어준다.
- 각 셀의 height, width를 다시 3등분하여 4개의 sampling point를 찾는다.
- Bilinear interpolation을 적용하여 sampling point의 값을 추정한다.
- 하나의 셀에 있는 sampling point에 대하여 max pooling을 수행한다.
Bilinear interpolation
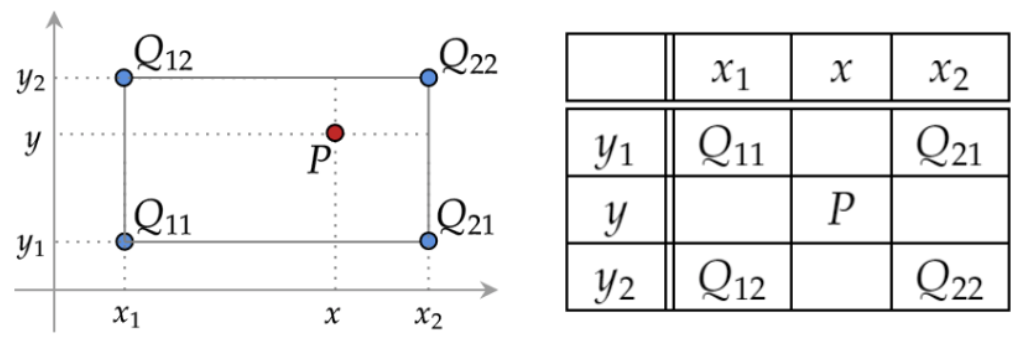
Bilinear interpolation은 주변 좌표들이 주어졌을 때 중간에 있는 값을 추정하는 방법으로 공식은 다음과 같다.
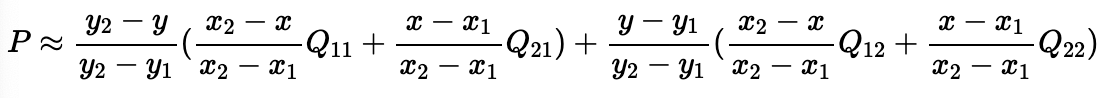
: 추정하려는 sampling point의 4개의 인접 셀의 값
: 추정하려는 sampling point의 좌표
: 인접 셀들의 좌표
Process
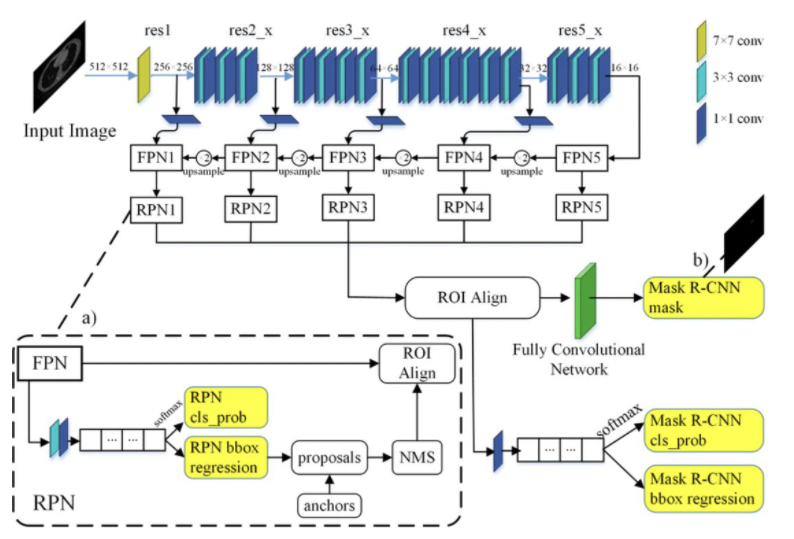
- 800~1024 사이즈로 이미지를 resize해준다. (using bilinear interpolation)
- Backbone network의 인풋으로 들어가기 위해 1024 x 1024의 인풋사이즈로 맞춰준다. (using padding)
- ResNet-101을 통해 각 layer(stage)에서 feature map (C1, C2, C3, C4, C5)를 생성한다.
- FPN을 통해 이전에 생성된 feature map에서 P2, P3, P4, P5, P6 feature map을 생성한다.
- 최종 생성된 feature map에 각각 RPN을 적용하여 classification, bbox regression output값을 도출한다.
- output으로 얻은 bbox regression값을 원래 이미지로 projection시켜서 anchor box를 생성한다.
- Non-max-suppression을 통해 생성된 anchor box 중 score가 가장 높은 anchor box를 제외하고 모두 삭제한다.
- 각각 크기가 서로다른 anchor box들을 RoI align을 통해 size를 맞춰준다.
- Fast R-CNN에서의 classification, bbox regression branch와 더불어 mask branch에 anchor box값을 통과시킨다.
