Abstract
- NLP에서 transformer는 큰 성과를 이루며 실질적인 표준이 되었으나, CV에서의 응용은 제한적
- 그동안 vision 분야에서는 attention을 CNN과 혼용하여 사용하거나, CNN의 구조는 유지하되 일부 요소들만 대체하는 방식으로 사용해왔다.
- 본 논문에서는 CNN이 필수적이지 않으며 pure transformer를 이미지 패치들의 시퀀스에 직접 적용하여 Classification을 효과적으로 수행할 수 있음을 보인다.
- 대용량의 데이터셋에서 pretrain한 후, 중~소 사이즈의 벤치마크(ImageNet, CIFAR10)에 전이학습 할 때 ViT는 CNN기반 SOTA모델에 비해 효율적이면서도 훌륭한 성과를 보였다.
Introduction
- NLP에서 self-attention 구조는 일반적으로 대규모의 corpus에 대해 pretrain한 후 더 작은 데이터셋으로 fine-tuning하는 방식으로 사용되어 왔다.
- Vision 분야에서는 CNN에 구조에 self-attention을 혼용하거나, convolution layer를 전부 attention으로 바꿔버리기도 했는데 후자의 경우 이론적으로는 효율적이나 현대의 하드웨어 가속기로는 아직 효율적으로 확장되기 어려웠다.
- 본 연구에서는 Transformer 구조의 수정을 최소화하여 적용하기 위해 이미지들 패치들로 분할하고 이 패치들의 linear embedding의 시퀀스를 인풋으로 전달했다.
- 위 구조를 사용했을 때 mid size의 데이터셋에서 성능이 좋지 못했는데 이는 Transformer가 inductive bias를 학습하기에 부족하기 때문이다.
- 하지만, 대규모 데이터셋에서 학습을 할 경우에는 부족함을 보완할 수 있음을 보였고 대규모 데이터셋에서 사전학습한 후 작은 특정 데이터셋에서 전이학습하는 방식으로 효과를 보았다.
Inductive bias란
"지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용되는 추가적인 가정"
- CNN에서는 locality라는 가정이 있고 지역적인 영역에서 Spatial한 정보를 잘 뽑아낸다. 반대로 RNN에서는 시계열적인 요소가 들어가 가까운 토큰들끼리 더 큰 영향력을 주도록 설계되어 있다고 할 수 있다. Transformer는 전체적인 정보를 이용하여 지역적인 정보를 뽑아내기에는 부족했을 것으로 추정된다.
Method
Vision Transformer(ViT)
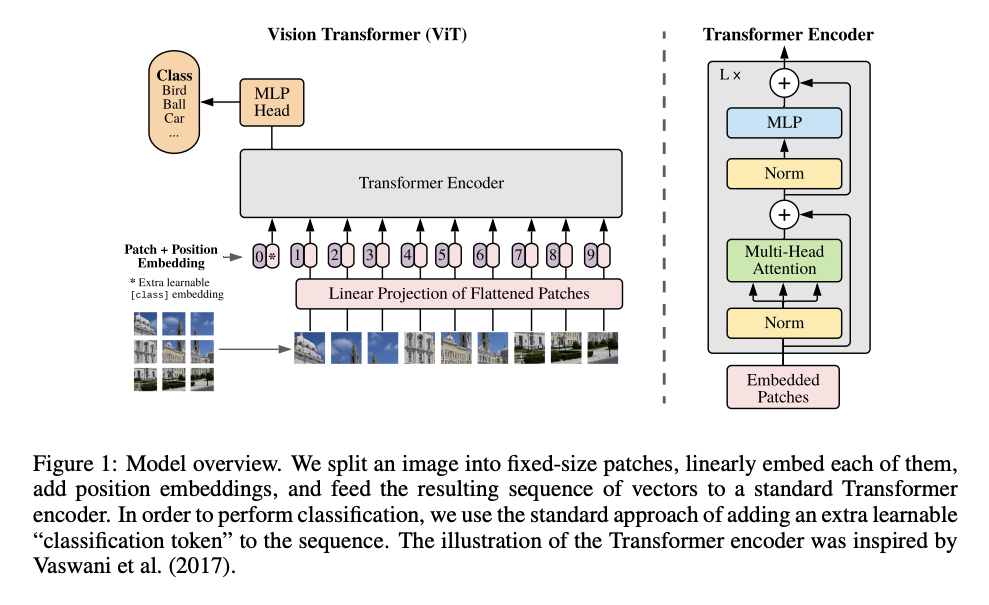
- 3차원 이미지 를 1차원 토큰 임베딩 시퀀스를 인풋으로 받는 트랜스포머에 적용하기 위해 2차원 패치들 으로 Flatten 시킨다. P는 패치의 해상도, N은 패치의 수를 의미한다.
- Patch embedding: 트랜스포머에서는 동일 사이즈의 latent vetor가 레이어를 거치기 때문에 2차원 패치들을 크기의 1차원으로 다시 Flatten하고 이를 linear projection을 통해 D차원 벡터로 매핑시킨다.
- Classification head: 임베딩된 패치들의 맨 앞에 학습 가능한 class 토큰 임베딩 벡터를 추가한다. 이 벡터는 encoder층을 거쳐 최종 ouput으로 나왔을 때 이미지에 대한 1차원 representation vector로써의 역할을 수행한다.
- Position embeddings: 위치 정보를 담기 위한 학습 가능한 임베딩 벡터.
수식을 살펴보면 다음과 같다.
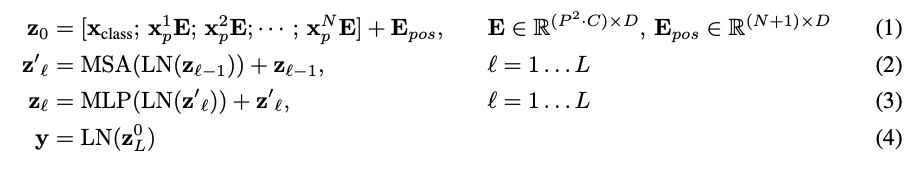
(1) Patches and Position embeddings
는 n번째 패치를 의미한다. 각 패치들을 에 곱해 [cls] 토큰을 연결한 후 Position embedding을 더해준다.
(2),(3) Encoder
Multi head attention과 MLP를 거치며 각 레이어로 들어오기 전에 Layer normalization 과정을 거친다. 두 레이어에서 모두 skip connection을 이용한다.
(4) MLP Head
[cls] 토큰의 최종 출력은 LN을 거치며 사전학습 시에는 하나의 은닉층을 가진 MLP로, 파인 튜닝 시에는 단일 Linear layer를 통과하여 결과값을 얻는다.
Fine-Tuning and Higher Resolution
- 사전 학습시 사용한 head를 제거하고 zero-initialized 의 linear layer가 부착된다.(K는 class의 수)
- 사전학습할 때보다 높은 해상도의 이미지를 사용하되 패치의 크기는 동일하다.(즉, 파인 튜닝 시 패치의 수가 더 많다)
- 트랜스포머에서 시퀀스의 길이(패치의 수)가 길어져도 처리하는데는 문제가 없으나 사전 학습된 position embedding은 의미를 잃게 된다. 이는 2D interpolation을 통해 해결하였다.
