Contributions
- 하나의 네트워크로 bounding box 예측과 class 분류를 모두 해결(One-Stage)
- 45FPS로 실시간 detection이 가능(Fast-YOLO에서는 155FPS)
- localization error가 증가했지만 배경에 대해 false positive가 줄었다.
- sliding window나 region proposal 기반의 테크닉들과 달리 전체 이미지를 한번에 보기 때문에 외형 뿐만 아니라 맥락적인 정보도 얻을 수 있다.
- object의 general한 representations를 학습하여 자연 이미지를 학습한 후 그림을 테스트해봐도 성능이 잘 나온다.
Unified Detection
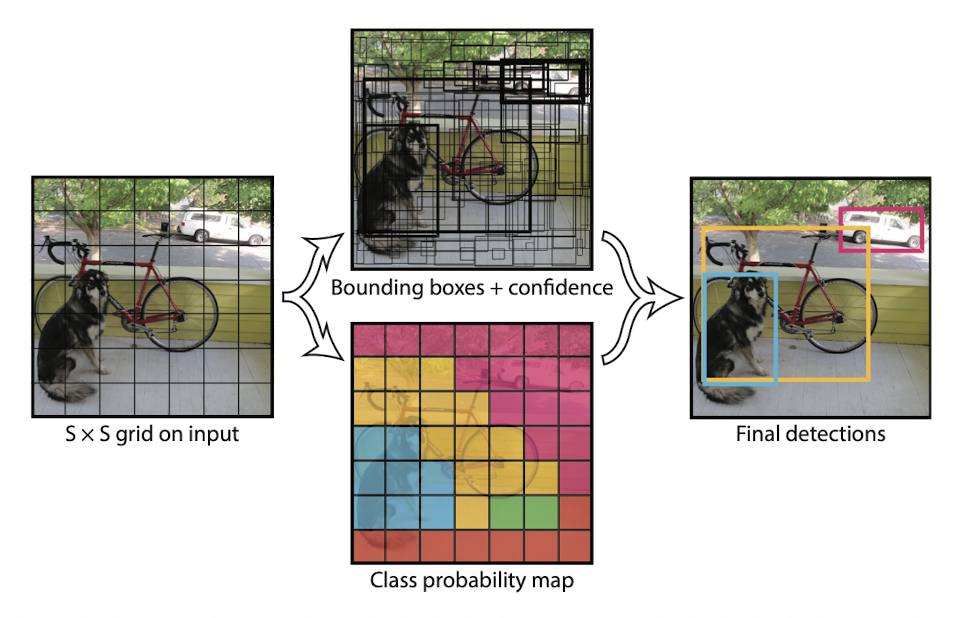
- input image를 SxS의 그리드로 나눈다.
- 각 그리드 셀은 B bounding boxes를 예측하고 confidence score을 계산한다. (x, y, w, h, conf)
Confiendence score =
각 그리드 셀의 크기는 1로 정규화되며 x,y는 bouding box의 center 좌표로 자신이 위치한 그리드 셀에 관해서 정의된다- box의 수와 관계없이 각 그리드 셀에 대해 class probabiliy를 구한다.
IOU가 높은 box가 responsible box가 된다.- Test 과정에서 class probability와 confidence score를 곱한 값으로 클래스별 confidence score를 구한다.
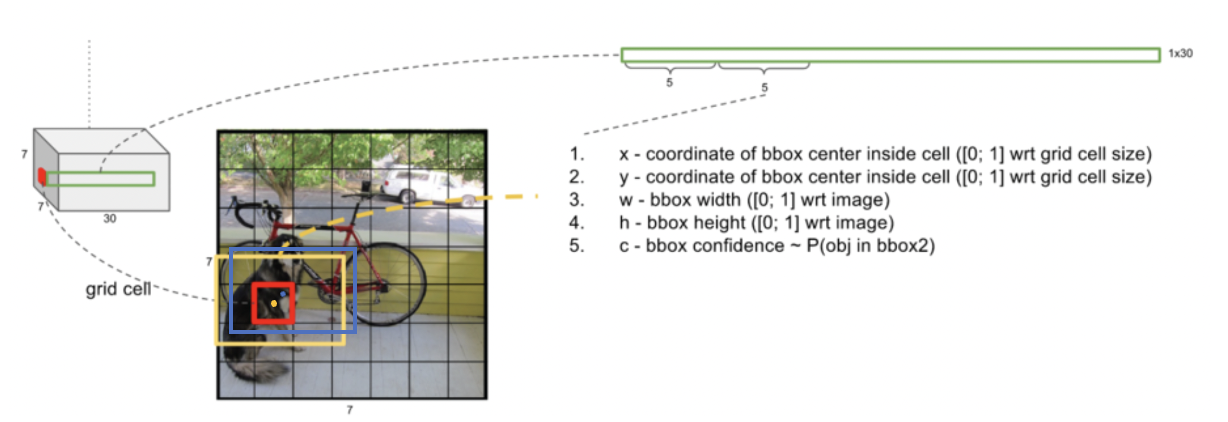
위 그림에서 노란색 bounding box는 대략 (0.5, 0.5, 3/7, 2/7)과 같은 좌표를 가지며, 파란색 bounding box는 대략 (0.8, 0.2, 3/7, 2/7)과 같은 좌표를 가지게 될 것이다.
논문에서는 Pascal VOC 데이터셋을 사용하여 클래스의 종류는 20개, S=7, B=2로 설정하였다. 각 그리드 셀에 대해 bouding box1의 (x, y, w, h, conf) bouding box2의 (x, y, w, h, conf), 20개의 클래스에 대한 probability 총 2*5+20=30차원이 ouput으로 출력되어야 하므로 최종적으로 7x7x30의 텐서가 나오게된다.
Network Design
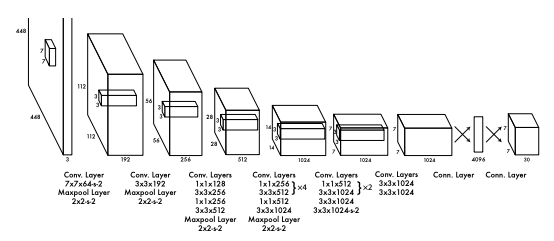
네트워크 구조는 GoogLeNet을 변형시켜 사용하였다. 첫 20개의 layer는 ImageNet의 1000개의 class를 pretrain 시킨다. 이후 4개의 convolution layer와 2개의 fc layer를 연결하여 detection을 수행하게 되는데 이 때의 가중치는 랜덤하게 설정한다.
Loss function
YOLO v1에서는 Sum squared error를 사용하면서 예상되는 2가지 문제점에 대해서 약간의 변형을 사용하여 해결하였다.
- localization error와 classification error의 가중치가 같은 것은 적절하지 못하므로 가중치를 조정한다.
- 대부분의 셀들이 배경이므로 confidence가 0이다. 이로 인해 confidence score가 0에 가까워지도록 학습하므로 배경 class의 경우 confidece error에 대한 가중치를 낮춰준다.
- 작은 박스에서의 편차가 큰 박스보다 더 중요하므로 width와 height에 루트를 씌워 그 영향력을 줄인다.

- localization error의 영향력을 높이기 위해 5의 가중치를 준다.
- i번째 셀의 j번째 bounding box가 responsible box일 때만 x, y좌표에 대한 error를 계산한다.
- 배경 class의 경우 학습에 영향을 덜 미치도록 가중치를 0.5로 설정해준다.
- i번째 셀, j번째 bouding box가 배경일 경우에만 confidence error를 계산한다.
- 객체를 포함한 bounding box에 대한 confidence error.
- bouding box와 관계없이 각 셀마다 클래스를 분류하기 위한 오차.
Limitations
-
bouding box의 수에 제한을 두어 한 셀에 여러 객체가 있을 경우 detection이 불가능하다.
-
데이터에 기반하여 추출한 bounding box로 학습시키기 때문에 새로운 객체나 일반적이지 않은 aspect ratio에 취약하다.
-
multiple downsampling을 하여 bounding box 예측에 있어 coarse features를 사용하게 된다.
-
작은 박스에서의 오차가 IOU에 더 큰 영향력을 미침에도 불구하고 박스의 크기와 무관하게 동일한 error를 적용한다.
References
-
http://blog.naver.com/PostView.nhn?blogId=sogangori&logNo=220993971883
