MF 최적의 파라미터 찾기
최적의 k와 iteration 값을 찾아 과적합을 방지한다.
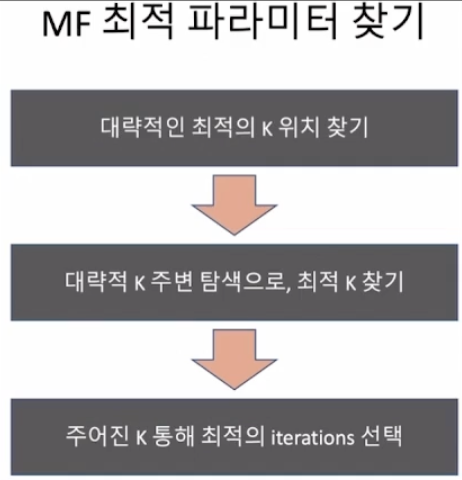
10씩 k값을 조정해나가면서 RMSE값을 계산해 대략적인 최적의 k값을 찾은 후, 대략적인 최적의 k값에서 전후로 1씩 조정해나가며 최적의 k값을 찾는다.
최적의 k값을 고정해두고, iteration을 같은 방식으로 찾는다.
실험을 반복하면서 어떤 특정 k값과 iteration 값이 가장 좋은 성능을 보인다는 패턴을 관찰할 수 있다. 이러한 패턴을 통해 두 하이퍼파라미터 간의 연관성을 이해하고, 최적의 조합을 찾을 수 있다.
해당 방법은 sklearn의 그리드 서치(GridSearchCV) 방식과 동일하다.
# 최적의 k값 찾기
results = []
index = []
R_temp = ratings.pivot(index = 'user_id',
columns = 'movie_id',
values = 'rating').fillna(0)
for K in range(50, 261, 10):
print(f'K : {K}')
hyper_params = {
'K' : K,
'alpha' : 0.001,
'beta' : 0.02,
'iterations' : 300,
'verbose' : True
}
mf = NEW_MF(R_temp, hyper_params)
test_set = mf.set_test(ratings_test)
result = mf.test()
index.append(K)
results.append(result)K값의 변화에 따른 RMSE 변화
summary = []
for i in range(len(results)):
RMSE = []
for result in results[i]:
RMSE.append(result[2]) #test RMSE 값을 계속 append하고
min = np.min(RMSE) #그 중 가장 작은 값을 받아와
j = RMSE.index(min) #index를 찾는다.
summary.append([index[i], j+1, RMSE[j]])
summary 그래프 표현
from matplotlib import rc
import matplotlib.pyplot as plt
import seaborn as sns
rc('font', family = 'AppleGothic')
x = [x[0] for x in summary]
y =[y[2] for y in summary]
min_rmse = np.min(y)
min_x = y.index(min_rmse)
plt.xlabel('K')
plt.ylabel('RMSE')
plt.title('RMSE 변화')
plt.grid(True)
plt.plot(x, y)
plt.scatter(x[min_x], min_rmse, c='red', marker='o')
plt.legend(['RMSE'])
plt.show()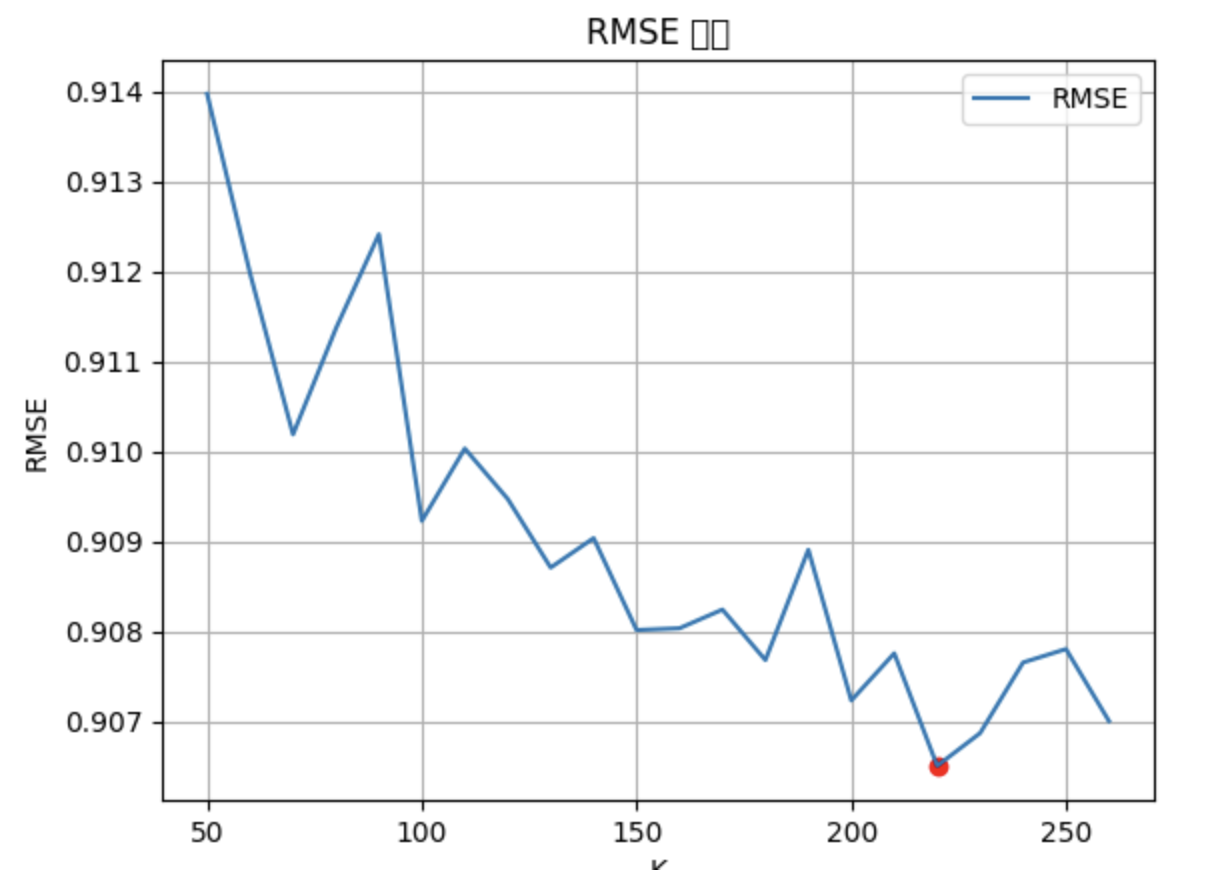
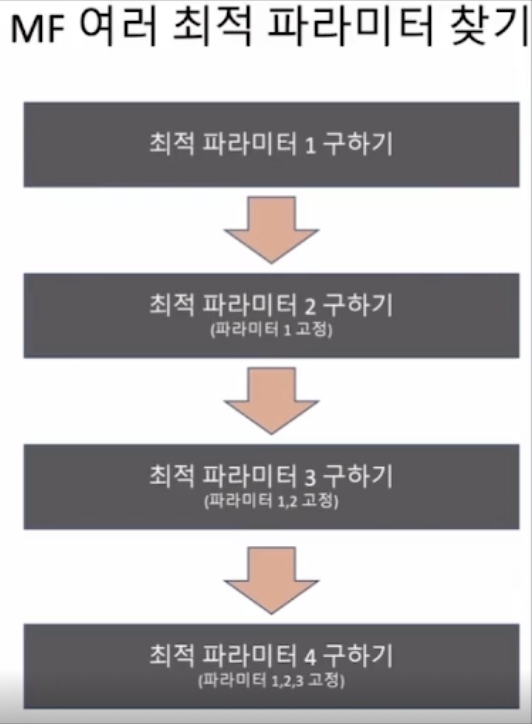
MF 여러 최적의 파라미터 찾기
개별적인 최적의 파라미터를 찾아냈다 할지라도, 이들의 단순 조합이 최고의 결과를 낼 것이라는 보장은 없다.
개별의 파라미터들은 독립이 아니라 어느정도의 상관관계를 가지고 있기 때문에
첫번째 최적의 파라미터 값을 구한 다음에 첫번째 최적의 파라미터 값을 고정한 채로 두번째 최적의 파라미터 값을 구하고, 첫번째 두번째 파라미터 값을 구해 놓고 고정한 다음 세번째 최적의 파라미터 값을 찾고, 이러한 과정을 반복해야 한다.

data analysis, data science