MF와 SVD
데이터 분석과 기계학습에서 많이 사용되는 MF와 SVD 개념을 헷갈려하는 사람들이 많다고 한다. 그렇지만 명백히 다른 기법이라고 한다.
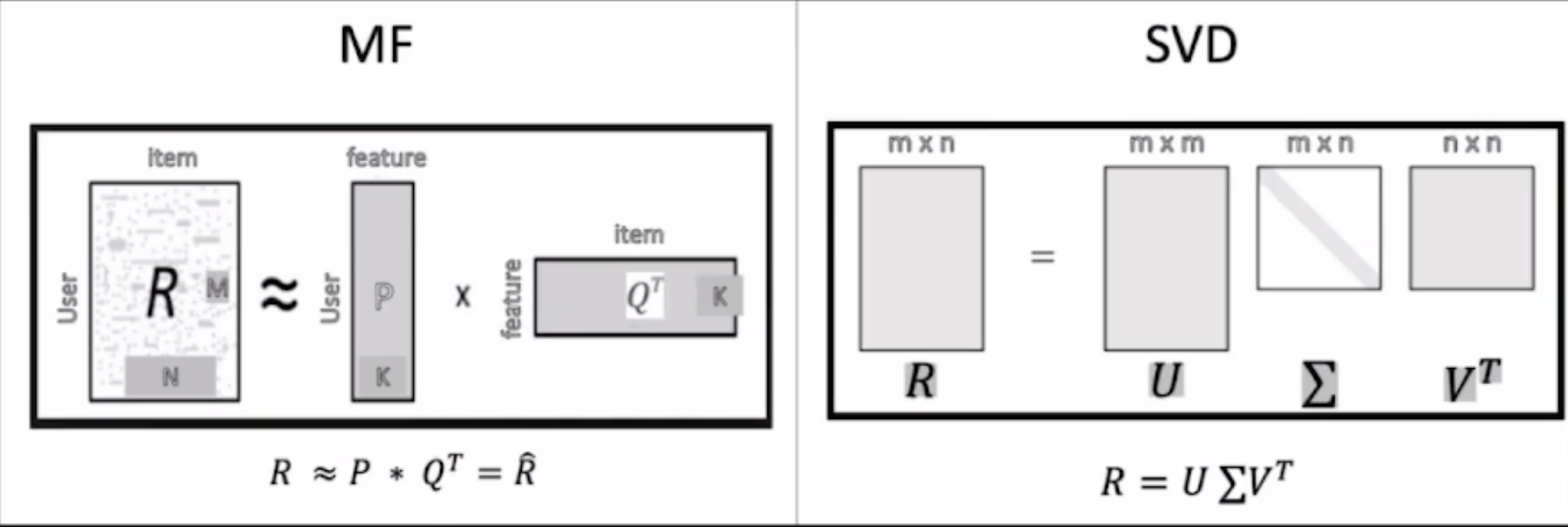
MF Matrix Factorization
반면, MF의 경우 2개의 행렬로 분해하고, k개의 잠재요인을 사용해서 표현된다.
null값을 0의 값으로 표현했고, P 행렬과 Q 행렬을 학습시킬 때에는 평가한 값만을 가지고 계산하기 때문에 사실상 null값은 제외하고 학습시키는 구조이다.
원래의 평가표에 null값이 있다 하더라도 P,Q 행렬은 null이 없이 학습되어 나오기 때문에 학습이 끝나고 나면, P, Q 행렬을 사용해서 원래의 평가표에 빠져 있는 null값에 대해서도 정확하게 예측할 수 있다.
SVD Singular Value Decomposition
R을 3개의 행렬로 분해해서 학습시킨 다음, 3개의 행렬로 원래의 행렬을 다시 재현하는 기법이다.
원래 행렬의 null값을 허용하지 않기 때문에 null값을 예측하는 데에는 어려움이 있다.
null값을 0으로 채운다면, 0 또한 하나의 값으로 인식하여 0을 재현하려 노력하기 때문에 (0에 근사하는 값이 나옴)
평가하지 않은 항목을 0으로 채운 후, 평가한 값만 가지고 학습 시킨 후, null값을 다시 예측할 수 없는 구조이다.
SVD는 차원축소에서도 많이 쓰이는데, 변수가 1000개가 있을 때, 유의미한 변수를 추리기 위해 쓰인다.
하지만, 추천시스템 분야에서는 거의 사용이 되지 않는다.

data analysis, data science