딥러닝(Deep Learning : DL)
다수의 은닉층(hidden layer)을 가진 인공 신경망을 적용한 기법
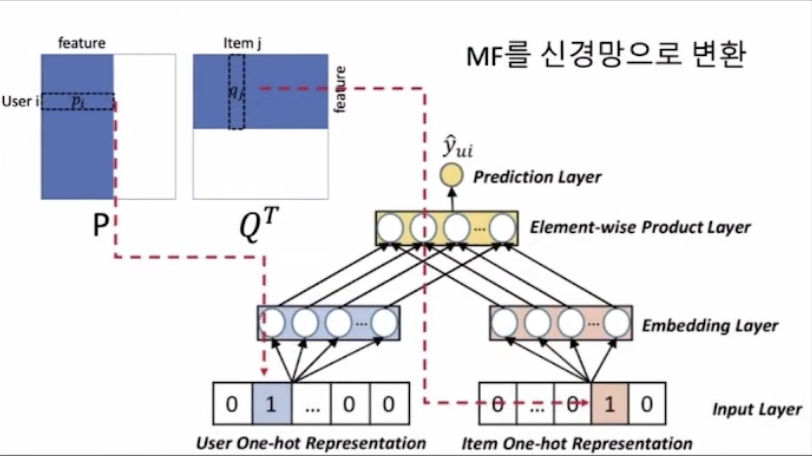
MF를 신경망으로 변환하기(개념)
One-hot Representation
One-hot Representation은 One-hot encoding 개념과 같다.
m명의 사용자가 있고, n개의 아이템이 있다고 가정하면, mxm인 representation과 nxn인 representation이 나온다.
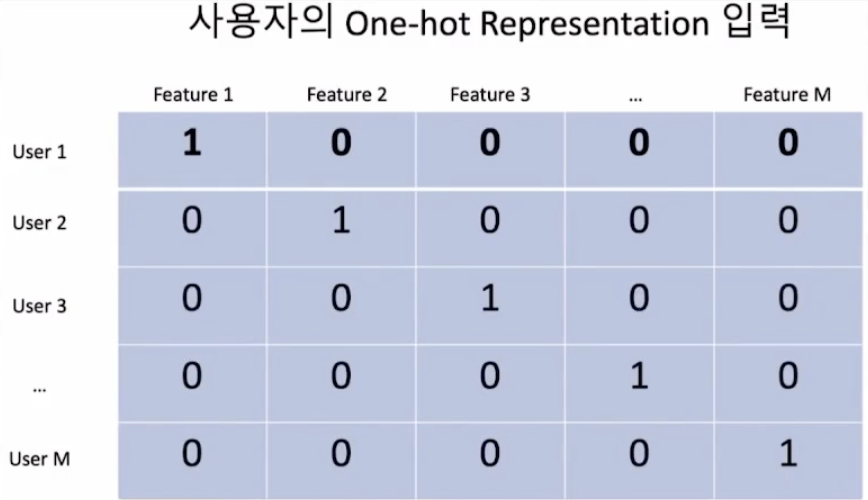
따라서 대각원소에 대해서만 1을 갖고 나머지에 대해서는 0을 갖는 형태이다.
One-hot representation의 목적은 각 사용자를 구분하기 위함이므로 feature 자체를 일종의 dummy variable로 사용해서 사용자 한 명당 하나의 feature만을 1을 갖는 형태이다.
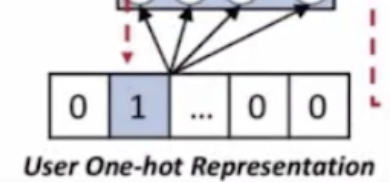
위의 그림에서는 1번째 사용자를 표현한 것이라 보면 된다.
Embedding Layer
MF의 잠재 요인에 해당하는 부분이다.
즉, 사용자에 대해서 K개, 아이템에 대해서 또 다른 K개의 노드를 갖는 레이어라고 생각하면 된다.
노드의 개수 = K개
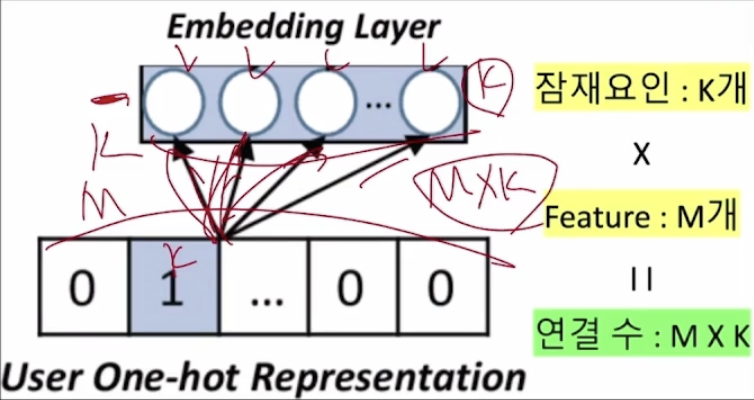
따라서, M x K개의 화살표가 있고, Embedding layer와 one-hot representation을 연결하고 있다.
(한 사용자당 K개의 화살표가 있다는 의미)
아이템도 마찬가지이기 때문에 N x K개의 화살표가 있고, 한 아이템 당 K개의 화살표가 연결되어 있다.
input layer에서 embedding layer의 각 요소로 가는 이 연결이 MF의 P, Q 행렬의 원소를 나타내게 된다.
- 사용자 부분에서의 연결 크기 = (M, K) = P의 크기
- 아이템 부분에서의 연결 크기 = (N, K) = Q의 크기
Element-wise Product Layer
embedding layer의 두 요소를 연산하기 위한 layer이다.
MF의 P와 Q의 전치행렬을 내적한 것이라고 보면 된다.
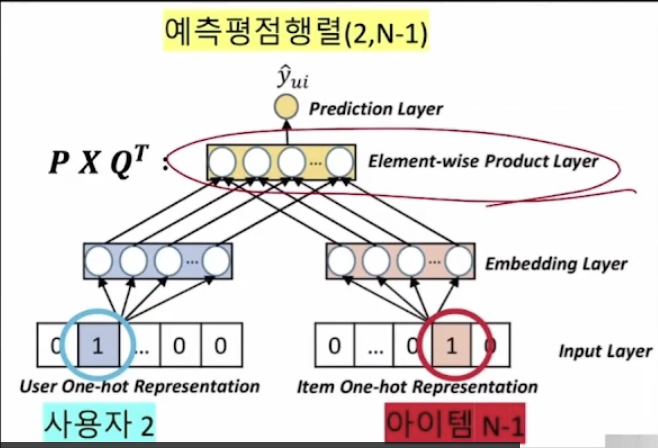
위와 같은 그림에서는 2번 사용자가 N-1번 아이템에 대한 예측 평점을 구한 것이라 보면 된다.
Prediction Layer
Element-wise Product Layer가 최종적으로 Prediction Layer에 연결된다.
위 그래프에서 추가적으로 고려해야 할 사항은 MF의 사용자와 아이템의 평가 경향이다.
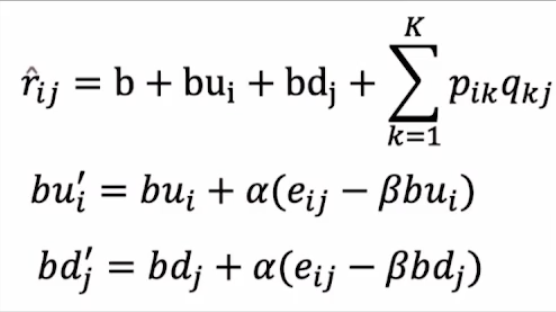
사용자 bias와 아이템 bias 모두 각각의 하나의 노드를 갖는 레이어로 모델화할 수 있다.
사용자 입력 노드 M개와 연결된 하나의 노드를 만들면 사용자 평가 경향을 추가할 수 있고, (bu)
아이템 입력 노드 N개와 연결된 하나의 노드를 만들면 아이템 평가 경향을 추가할 수 있다. (bd)
MF를 신경망으로 변환한 것을 도식화하면 아래와 같다.
- 사용자 데이터(input)에 One-hot Representation을 한 것을 사용자 Embedding과 연결한다.
- 아이템 데이터(input)에 One-hot Representation을 한 것을 아이템 Embedding과 연결한다.
- 사용자 Embedding과 아이템 Embedding을 Dot Product한다.
- 사용자 One-hot Representation을 사용자 Bias Embedding과 연결한다.
- 아이템 One-hot Representation을 아이템 Bias Embedding과 연결한다.
- 3번에서 내적한 값과 사용자 Bias Embedding, 아이템 Bias Embedding을 더한다.
- 최종 데이터와 지금까지 계산에 사용된 행렬의 차원을 맞춰주기 위해 차원을 줄여준다.
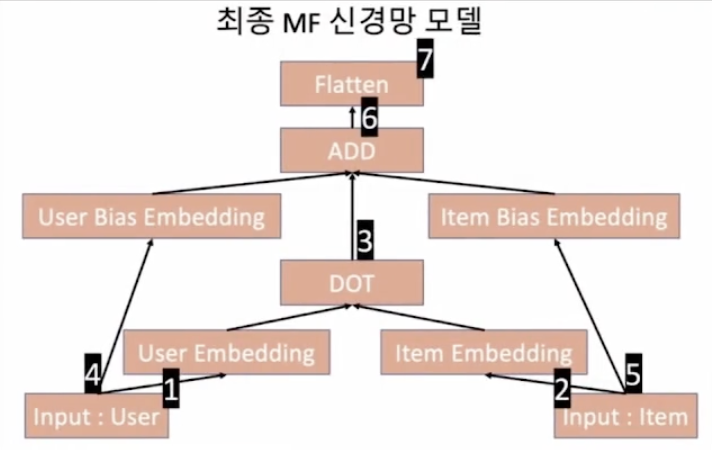
위에서 전체 평균(b)은 고려하지 못했는데, 전체 평균은 상수값이기 때문에 모델에 더하기가 쉽지 않다.
일반적으로 신경망에서는 학습 가능한 가중치나 편향을 사용하는데, MF의 전체 평균은 일정한 상수값이기 때문에 그렇다고 볼 수 있다.
-> 따라서, 아이템 데이터를 신경망에 추입하기 전에 전체 평균(b)을 일률적으로 빼주고, 나중에 산출된 예측치에 다시 전체 평균(b)를 더해주는 형태로 만들어 주어 전체 평균이 고려되지 못하는 상황을 해결할 수 있다.
MF를 신경망으로 변환하기(코드)
은닉층이 없는 신경망을 keras로(MF를 keras로 만드는 형태) 만든다.
import pandas as pd
from sklearn.model_selection import train_test_split
# 필요한 tensorflow 모듈들을 가져온다.
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Dot, Add, Flatten
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import SGD, Adamax
# 데이터 준비
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('drive/MyDrive/RecoSys/data/u.data',
names = r_cols,
sep = '\t',
encoding = 'latin-1')
ratings_train, ratings_test = train_test_split(ratings,
test_size = 0.2,
shuffle = True,
random_state = 2024)
K = 200 #(latent vetor)
# 전체 평균
mu = ratings_train['rating'].mean()
M = ratings['user_id'].max() + 1 #bias 때문에 1 추가
N = ratings['movie_id'].max() + 1
def RMSE(y_true, y_pred): #numpy가 아니라 tensorflow의 연산라이브러리 사용.
return tf.sqrt(tf.reduce_mean(tf.square(y_true - y_pred)))
user = Input(shape = (1,))
item = Input(shape = (1,)) # 입력 크기 지정
P_embedding = Embedding(M, K, embeddings_regularizer = l2())(user) #input으로 one-hot representation한 것과 embedding layer 연결 / P를 나타낸다.
Q_embedding = Embedding(N, K, embeddings_regularizer = l2())(item) #Q를 나타낸다.
user_bias = Embedding(M, 1, embeddings_regularizer = l2())(user) #bias 관련 모델화
item_bias = Embedding(N, 1, embeddings_regularizer = l2())(item)
R = layers.dot([P_embedding, Q_embedding], axes = (2,2)) #axis 2,2 : 첫번째 매트릭스와 두번째 매트릭스 간에 몇번째 축끼리 연산을 할건지 / k와 k를 연산한다.
R = layers.add([R, user_bias, item_bias])
R = Flatten()(R)
model = Model(inputs = [user, item], outputs = R)
model.compile(
loss = RMSE,
optimizer = SGD(),
metrics = [RMSE]
)
model.summary()요약정보 확인
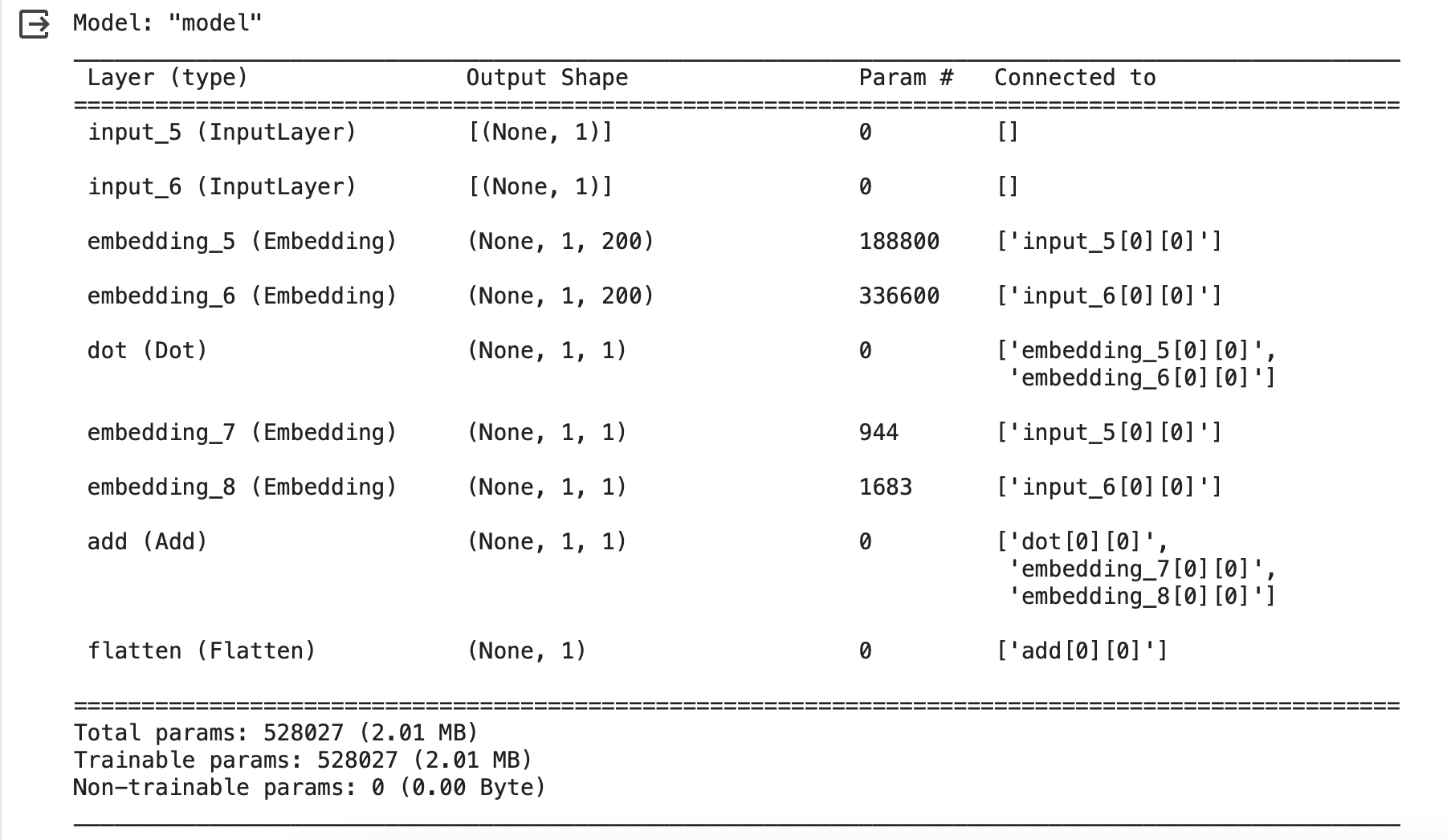
embedding_5 : 188800(params) k = 200 사용자 943명 (+1해서 곱함)
embedding_6 : 336600(params) k = 200 아이템 1682개 (+1해서 곱함)
embedding_7 : 944 (코드에서 지정한 M)
embedding_8 : 1683 (코드에서 지정한 N)
모델 학습 및 rmse 그래프 그리기
result = model.fit(
x = [ratings_train['user_id'].values,
ratings_train['movie_id'].values],
y = ratings_train['rating'].values - mu,
epochs = 60,
batch_size = 256,
validation_data = (
[ratings_test['user_id'].values,
ratings_test['movie_id'].values],
ratings_test['rating'].values - mu
)
)
import matplotlib.pyplot as plt
plt.plot(result.history['RMSE'], label = 'Train RMSE')
plt.plot(result.history['val_RMSE'], label = 'Test RMSE')
plt.legend()
plt.show()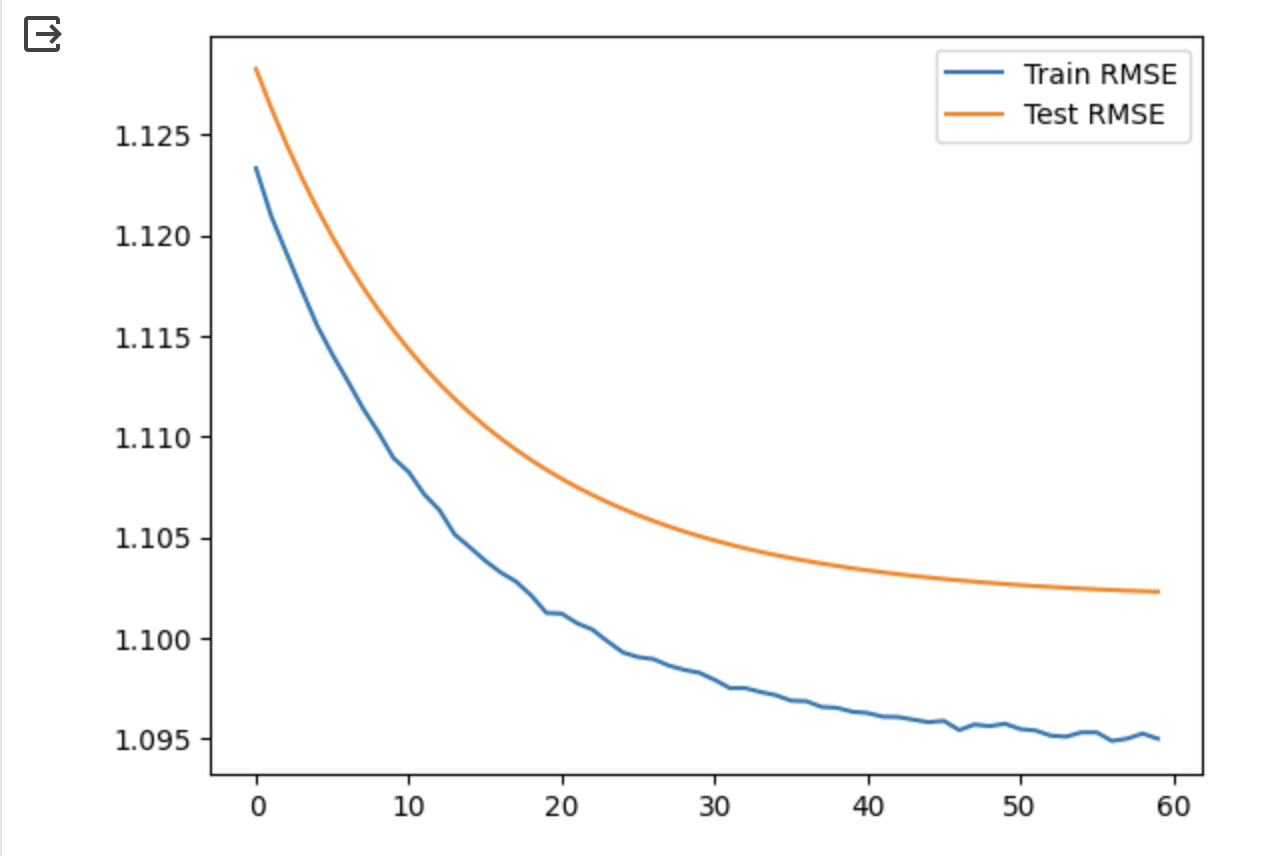
user_ids = ratings_test['user_id'].values[:6]
movie_ids = ratings_test['movie_id'].values[:6]
predictions = model.predict([user_ids, movie_ids]) + mu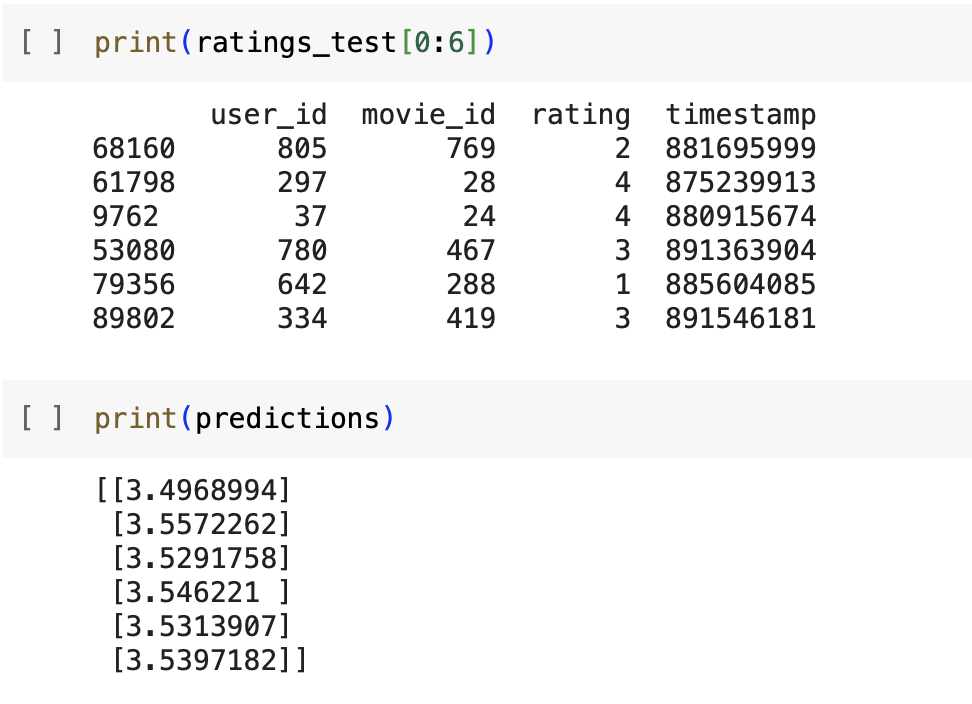
임시로 6개만 예측해본다.
임시로 예측 결과의 rmse 계산
import numpy as np
def RMSE2(y_true, y_pred):
return np.sqrt(np.mean((np.array(y_true)-np.array(y_pred))**2))
user_ids = ratings_test['user_id'].values
movie_ids = ratings_test['movie_id'].values
y_pred = model.predict([user_ids, movie_ids]) + mu
y_pred = np.ravel(y_pred, order = 'C') #1차원 형태로 만든다. y_true와 동일한 배열로 만들기
y_true = np.array(ratings_test['rating'])
RMSE2(y_true, y_pred)
