Surprise
Surprise 라이브러리란, Python에 기반하며 Scikit-learn API와 비슷한 형태로 제공을 하여 추천 시스템 구현을 도와주는 편리한 라이브러리이다.
surprise에 내장된 3가지 데이터
- ml-100k : MovieLens 100K 데이터 (앞에서 계속 사용해온 데이터)
- ml-1m : MovieLens 1m 데이터 (100만 개)
- jester : 조크사이트 게시물 (650만 개)
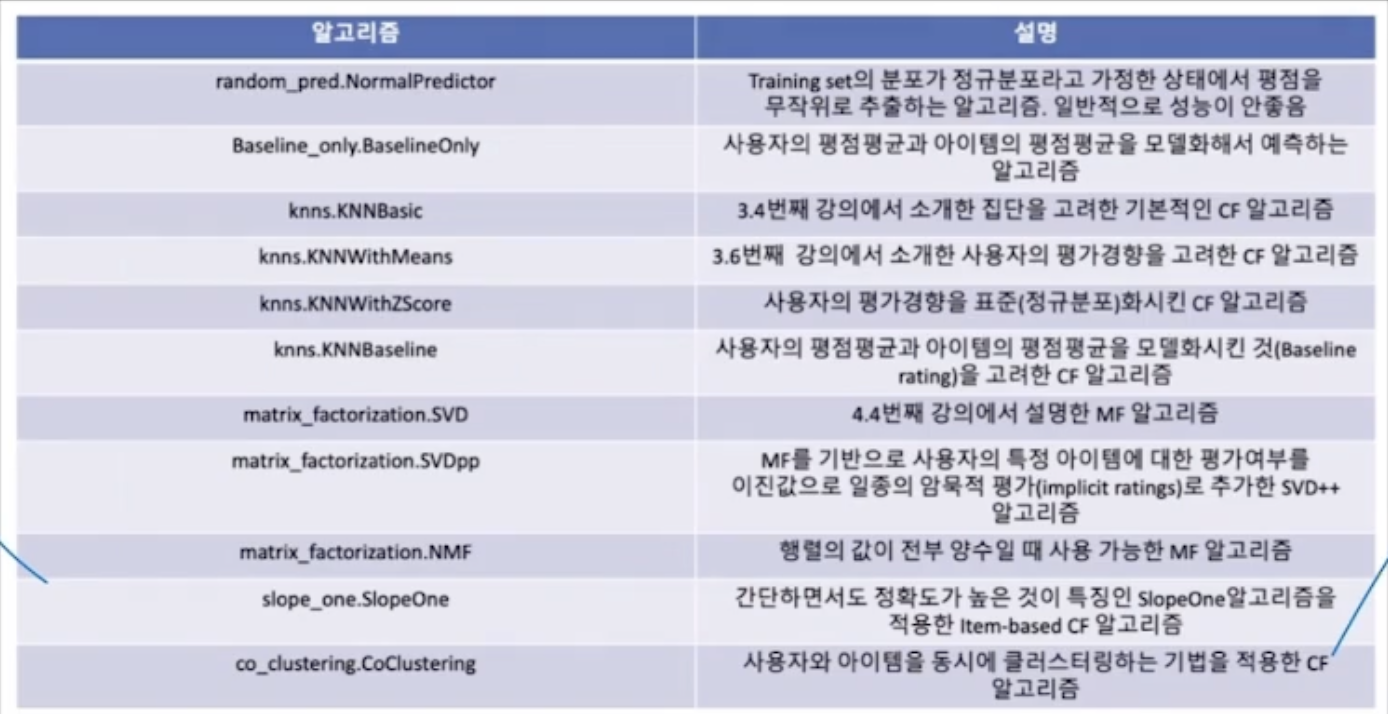
NormalPredictor
Training set의 분포가 정규분포라고 가정한 상태에서 평점을 무작위로 추출하는 알고리즘.
일반적으로 성능이 안 좋다.
BaselineOnly
사용자의 평점 평균과 아이템의 평점 평균을 모델화해서 예측하는 알고리즘.
KNNBasic
KNN을 사용하고, 집단을 고려한 기본적인 CF 알고리즘.
KNNWithMeans
KNN을 사용하고, 사용자의 평가 경향을 고려한 CF 알고리즘.
KNNWithZScore
사용자의 평가 경향을 표준(정규분포)화 시킨 CF 알고리즘.
KNNBaseline
사용자의 평점 평균과 아이템의 평점 평균을 모델화시킨 것을 고려한 CF 알고리즘.
SVD
MF와 SVD를 혼용하기 때문에 SVD로 나와 있지만, 실제로는 MF 알고리즘.
SVDpp
MF를 기반으로 사용자의 특정 아이템에 대한 평가여부를 이진값으로 일종의 암묵적 평가(implicit ratings)로 추가한 SVD++ 알고리즘
실습으로 surprise 공부
import numpy as np
from surprise import BaselineOnly, KNNWithMeans, SVD, SVDpp, Dataset, accuracy, Reader
from surprise.model_selection import cross_validate, train_test_split
data = Dataset.load_builtin(name = u'ml-100k')
# train test 분리
trainset, testset = train_test_split(data, test_size = 0.25)
algo = KNNWithMeans()
algo.fit(trainset)
predictions = algo.test(testset)
accuracy.rmse(predictions)-> SGD를 사용한 MF 알고리즘과 크게 다르지 않다.

BaselineOnly, KNNWithMeans, SVD, SVDpp 알고리즘 비교
from surprise import BaselineOnly
from surprise import KNNWithMeans
from surprise import SVD
from surprise import SVDpp
import numpy as np
# 정확도 측정 관련 모듈을 가져온다.
from surprise import accuracy
# Dataset 관련 모듈을 가져온다.
from surprise import Dataset
# train/test set 분리 관련 모듈을 가져온다.
from surprise.model_selection import train_test_split
# 결과를 그래프로 표시하기 위해
import matplotlib.pyplot as plt
# MovieLens 100K 데이터 불러오기
data = Dataset.load_builtin(name = u'ml-100k')
# train/test set분리
trainset, testset = train_test_split(data, test_size = 0.25)
algorithms = [BaselineOnly, KNNWithMeans, SVD, SVDpp]
names = []
results = []
for option in algorithms:
algo = option()
names.append(option.__name__) # 클래스의 이름 가져오게 된다.
algo.fit(trainset)
predictions = algo.test(testset)
results.append(accuracy.rmse(predictions))
names = np.array(names)
results = np.array(results)
index = np.argsort(results) #rmse 작은 순서대로 index 추출
print(results[index])
%matplotlib inline
# %matplotlib notebook
import matplotlib.pyplot as plt
plt.ylim(0.8, 1) #y축 범위 지정
plt.plot(names[index], results[index])
plt.show()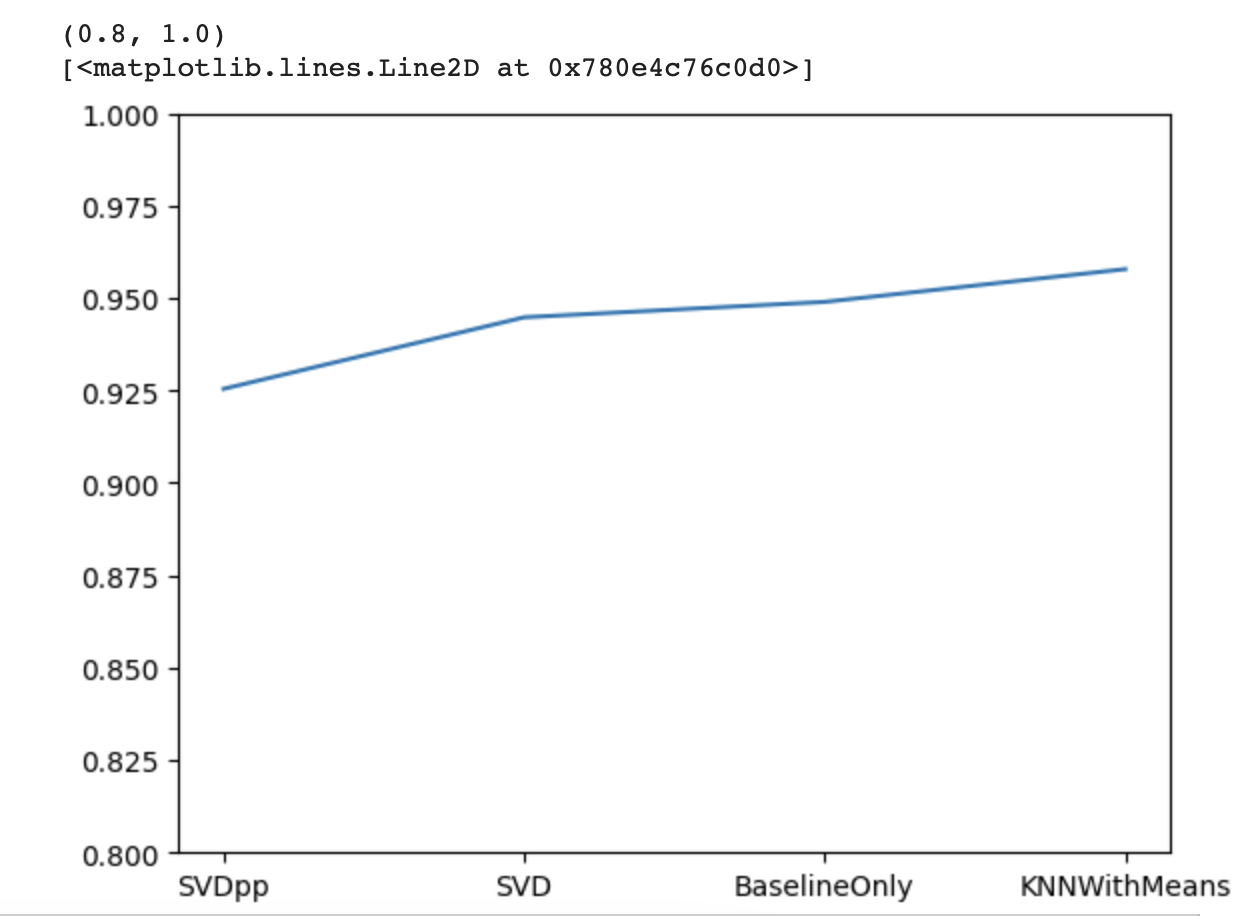
SVDpp가 가장 낮은 rmse로 가장 좋은 성능을 보이고 있다.
알고리즘 옵션 지정
유사도 지표의 종류
- MSD (KNNWithMeans의 default 유사도 지표 : 두 사용자가 공통으로 평가한 아이템의 총 개수와 공통 평가 영화에 대한 평점 차이를 가지고 계산하는 유사도 지표
- cosine sim : 사용자나 아이템을 찾을 때 교집합 안에서만 비교한다.
- pearson sim : 두 벡터의 상관계수. 코사인 유사도와 비슷하지만, 사용자의 평균을 빼서 유저별로 가지는 상대적인 경향을 제거한 방식의 유사도 지표.
- pearson baseline sim : 사용자의 평균을 빼는 것이 아니라, 베이스라인에서 예측한 베이스라인 값을 빼주는 유사도 지표.

sim_options = {'name' : 'pearson_baseline', #유사도 지표의 종류를 넣어준다.
'user_based' : True} #사용자기반 CF를 의미.
algo = KNNWithMeans(k=30, sim_options = sim_options) #k = 집단의 크기
algo.fit(trainset)
predictions = algo.test(testset)
accuracy.rmse(predictions)다양한 하이퍼파라미터들을 적용 후 비교
# KNN 다양한 파라미터 비교
# Grid Search를 위한 모듈 가져오기
from surprise.model_selection import GridSearchCV
param_grid = {
'k' : [5, 10, 15, 25],
'sim_options' : {
'name': ['pearson_baseline', 'cosine'],
'user_based' : [True, False]
}
}
gs = GridSearchCV(KNNWithMeans, #CV cross validation
param_grid,
measures = ['rmse'],
cv = 4)
gs.fit(data) #따로 train test 나누지 않아도 된다.
다양한 추천 알고리즘을 다양한 조건으로 실행해서 정확도를 계산할 수 있기 때문에 초기에 알고리즘 선정이나 대략적 세팅을 정할 때 조금 유용하게 많이 사용한다. 즉, 추천 시스템의 초기개발에 사용한다. 탐색적으로 사용해보기 좋은 알고리즘이다.
*딥러닝 코드에서는 테스트가 어렵다.
외부 데이터 사용(surprise 활용)
외부 데이터를 받아서 저장한 후, pandas로 불러 온 다음, Reader를 이용해 평가 척도를 지정해주고,
user_id, movie_id, rating만 데이터로 가져온다.
import pandas as pd
from surprise import Reader
from surprise import Dataset
# 데이터 프레임 형태로 데이터를 읽어 온다.
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('drive/MyDrive/RecoSys/data/u.data',
names = r_cols,
sep = '\t',
encoding = 'latin-1')
reader = Reader(rating_scale = (1, 5)) #데이터의 평가 척도가 1~5라는 것을 알려주는 것
data = Dataset.load_from_df(ratings[['user_id', 'movie_id', 'rating']], reader)
